接着上一篇
支撑大规模公有云的Kubernetes改进与优化 (1)
接下来我们按照kubernetes创建容器的详细过程,以及可能存在的问题。
一、API Server的认证,鉴权,Quota
当客户需要创建一个pod的时候,需要先请求API Server。
Kubernetes的API Server要负责进行认证和鉴权。
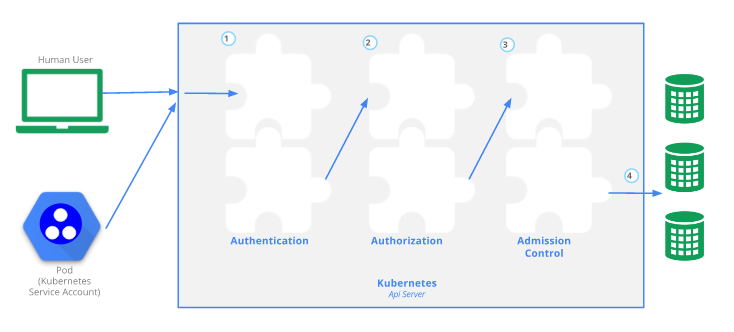
Kubernetes的认证方式也是如OpenStack或者AWS一样,是通过Token和PKI进行认证的。
所谓Token的方式就是在服务端配置一个很长的字符串,在客户端请求的时候带上这个字符串,两面匹配了,认证就通过了。
而PKI的方式复杂一些,PKI是Public Key Infrastracture,也即通过证书的方式进行认证。
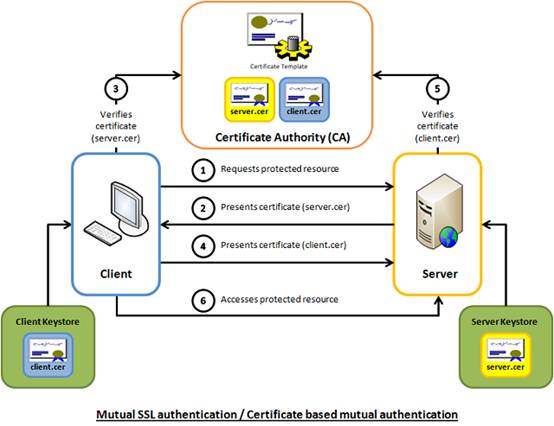
为什么叫做PKI呢?在出现Public Key和Private Key对这种方式之前,人们一直用的是对称加密的方式,客户端和服务端共享一个Private Key,两面对上了,就算认证通过了,但是如何传输,交换,约定这个Private Key是一个大问题,一旦在公网上传输,一定有可能被窃取,一旦泄露了,就被黑了。
后来就发明了Public Key和Private Key也即公钥和私钥对体系,因为以前是没有公钥的,所以这个体系叫做Public Key Infrastracture。
私钥是放在用户自己手里的,不能够在公网上进行传播,私钥千万不能丢,丢了就要赶紧换一个。而公钥是可以随便放在公网上的任何地方的。所以客户端和服务器各自抱着自己的私钥,然后拿到对方的公钥,私钥加密的只有对应的公钥可以解密,实现了相互的安全通信。
然而公钥可以随便放在网上,如何能够保证公钥能够被信任,不被篡改呢?就需要一个权威机构对这个公钥进行盖章,盖过章的就叫做Certificate,就像你的毕业证书被你的学校盖章了一样。权威机构成为CA,CA会有很多个级别,最低的级别叫Self-signed Certificate,也就是没啥权威机构盖章,我自己给自己盖章,只要我自己足够牛,例如订票网站12306,你添加他的证书的时候,浏览器会说不信任,但是没关系,你可以强行信任,不信任他你信任谁呢?还有更高级别的CA,一级一级盖章上去。
这也是为什么Kubernetes的
X509 Client Certs这种认证方式配置的是
--client-ca-file=SOMEFILE。
说完了认证,接下来我们再说鉴权。
鉴权一般采取的方式都是RBAC,也即Role Based Access Control。
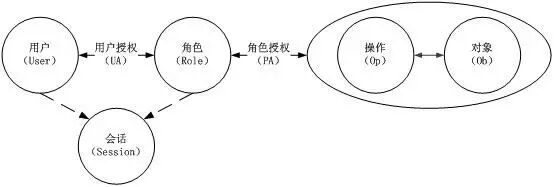
这是基本的RBAC的一个模型,有了这个模型,使得云对于权限的控制非常的灵活。
例如可以灵活定义Role之间的相互关系,例如互斥的关系,继承的关系。
另外可以事先定义Role和Permission之间的关系,他们之间的关系相对稳定,不会频繁变化,而一个User属于哪个Role,这个反而是经常改变的。
我们可以灵活的控制某个层级的管理员的权限,让这个管理员可以将用户关联或者解关联一个Role,但是不给这个管理员权限配置某个Role的Permission,因为后者显然更专业,需要更高层级的管理员来操作。
有了RBAC的权限设置,云平台可以灵活的控制资源的权限,隔离,账单等。
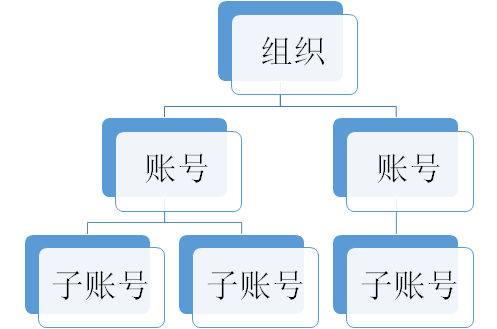
例如AWS有一个层级的账号体系,其中账号对应一个租户,租户之间完全隔离,租户之下有子账号,租户之内隔离性差一些,因而子账号多用于一个租户下面的多个子部门或者子团队的权限控制。而如果需要多个公司之间需要完全隔离,但是又有一个母公司的存在,或者一个公司统一结账,然后将资源转售给其他的公司,则不同的公司则不建议使用子账号,而应该使用账号,而母公司使用组织。
然而Kubernetes使用了相对简单的Attribute-based access control (ABAC) ,仅仅通过设置用户,访问哪个资源,访问哪个namespace,是否只读等。还不能满足公有云复杂的账号体系。
最后是设置ResourceQuota,也是针对namespace的。
Kubernetes的租户是用namespace隔离的,然而namespace是逻辑隔离,而非物理隔离,处于不同namespace的容器很可能会在同一台主机,甚至同一二层网桥上面,无论是计算,网络,存储没有实现真正的隔离。这对于私有云的可信租户是没有问题的,但是对于公有云的非可信租户,则有很大的问题。
二、Kubernetes的Scheduler
kube-scheduler启动的时候会创建一个NewSchedulerServer,并且运行它,app.Run(s)。
当前的scheduler回去etcd里面竞选自己是leader,如果是的话,则运行调度功能sched.Run()。
func (s *Scheduler) Run() {
go wait.Until(s.scheduleOne, 0, s.config.StopEverything)
}
其中scheduleOne的算法有以下的步骤:
获取下一个需要调度的Pod。
pod := s.config.NextPod()
使用调度算法找到一个具体的Node节点。
dest, err := s.config.Algorithm.Schedule(pod, s.config.NodeLister)
将Pod和节点绑定在一起。
b := &v1.Binding{
ObjectMeta: metav1.ObjectMeta{Namespace: pod.Namespace, Name: pod.Name},
Target: v1.ObjectReference{
Kind: "Node",
Name: dest,
},
}
err := s.config.Binder.Bind(b)
好了,重点来了,是调度算法。
对于默认的调度算法generic_scheduler.go来讲:
第一步预选,过滤掉不符合条件的节点,在kubernetes里面叫predicate。
例如PodFitsResources:检查Node的资源是否充足,包括允许的Pod数量、CPU、内存、GPU个数等。
另外还有一些规则可以通过标签选择部分节点,可以满足亲和性和反亲和性要求。
第二步优选,通过优先级排序,选择优先级最高的节点,在kubernetes里面叫做Prioritizing。
例如LeastRequestedPriority:优先调度到请求资源少的节点上。
是不是看到了你熟悉的预选和优选,对的OpenStack也是这样做的,分别叫做Filtering和Weighting。
但是Kubernetes的调度是在Pod层级的,Node对于租户来讲没有隔离,没有分别,全部可见。不同的租户的Pod是会调度到一台机器上的,这样安全性就有问题。
三、Kubernetes的kubelet启动容器
Kubelet启动的时候会运行一个KubeletServer,会调用RunKubelet,最终调用startKubelet。
在这里面不断的循环,查看有没有需要更新的Pod。
kl.syncLoop(updates, kl)
如果是新添加一个Pod,kubetypes.ADD,则HandlePodAdditions,这事情会dispatchWork给一批podWorkers来做。
podWorkers会调用syncPodFn,也即kubelet.syncPod,会真正创建容器。
创建容器的时候,当然先要下载容器的镜像,但是容器的镜像如何管理呢?
Kubernetes本身没有方案,需要你自己去解决。
当然最简单的是搭建一个Docker Registry,但是这个是单机版,只能测试使用,或者有一个Harbor,可以进行镜像的同步,权限的控制,是比较热的镜像管理软件,当然也可以你自己去搭建一个高可用的集群,当然需要有一个高可用的后端存储保存镜像,一般会用对象存储,那使用Swift呢,还是用Ceph呢?
好了下载了镜像,可以运行容器了,刚才说了,容器是隔离性不好的,是否需要采用隔离性好的容器实现呢?
当前业内有两种主流的实现方式,其实都是基于加一层微内核虚拟机来做这件事情的。
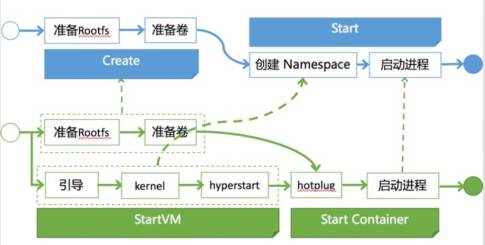
其中一个是著名的Hyper,加了一层虚拟化层如下图。
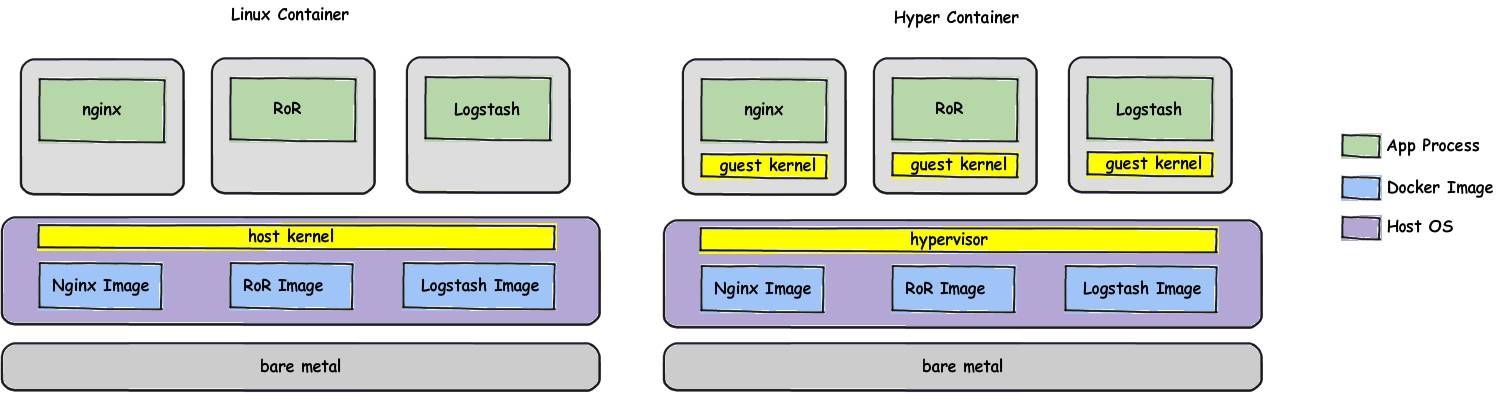
他容器的创建过程是先启动一个虚拟机,然后将Docker的rootfs映射进去,然后再启动容器。