
在这个信息爆炸的时代,你是否曾幻想过与机器流畅交谈,或是让AI助你笔下生花,创作出惊艳的文章?这一切,都离不开大语言模型的神奇魔力。今天,让我们一起揭开这层神秘的面纱,走进大语言模型的科普奇幻之旅!
通过大语言模型,人们只需要输入自然语言的指令,就能够让模型完成语言生成、翻译、文本分类等等复杂的任务。要做到这一切,首先我们需要将自然语言转化成模型能够处理的数据格式(如向量),让模型“听懂”之后,才能够完成后续的模型计算过程。
将自然语言中的单词映射到
模型易于处理的向量空间的过程,称为词嵌入(Word Embedding)。怎样才能完成这一步呢?如果我们将单词视作离散变量,就可以使用类似One-Hot的方法,让每个单词对应一个向量,第x个单词对应的向量中第x个值置为1,其他值置为0. 这样一来我们可以得到D个D维的向量,其中D为字典大小(所有训练语料中单词的个数),这就是词袋模型(Bag of Words)。
词袋模型成功地将自然语言转化为了向量,但还存在着一些问题:
1.字典:无法处理不在字典中的单词(OOV问题,Out of Vocabulary);而且单纯基于单词层面的构造,可能会不必要地产生非常大的字典。例如,在词袋模型中大量的名词都需要单数和复数形式的两个向量来表达,而-s单独拆出来作为一个向量似乎能更有效地表达信息。
2.向量:One-Hot产生的向量长度非常长也非常稀疏(存在大量的0),而且1出现的位置也没有任何其他含义(比如词之间的相关性),表达信息的效率很低。
本文所介绍的子词模型(Subword Models)将着重处理第一个问题,从单词层面进一步深入到子词(subword),生成描述更小的有意义单元的字典,从而提高后续语言模型的泛化能力。
二、Byte Pair Encoding (BPE) 模型
2016年发表的论文Neural Machine Translation of Rare Words with Subword Units提出了BPE模型。BPE作为经典的子词模型,至今仍被经常使用,其训练过程如下:
1.初始化字典:使用所有字母+标点的集合,以及一个标识单词末尾的符号“·”,作为初始字典。
2.字典训练:每次迭代时,找寻训练样本中相邻两个词组成的词对(pair)的出现频数,每次选择一个频数最高的词对作为一个新的词加入到字典。注意最开始时,这里的“词”实际上是字母等基本字符。在上面的例句中,词对“er”和“r·”的频数为2,而其他均为1,“er”将加入到字典中。下一轮中,“er·”将加入到字典中(或者先加入“r·”也可以,同频数时模型任意选择)。
3.训练停止:人工设置循环次数或者期望的字典大小作为中止条件。
BPE算法能够将英文中的各种后缀、前缀方便地切分出来,提高了字典对自然语言的描述能力,以下是一个可能的分词结果对比:

此外,BPE也能较好地解决OOV问题,一些新的词可以用子词来表达,即使在子词都不能表达的情况,至少也可以用字母等基本字符来覆盖。但BPE在遇到中文、日文等字符空间非常大的语言时,就有些不适用了。2019年的论文Neural Machine Translation with Byte-Level Subwords提出的BBPE模型基于字节进行初始化编码(中文、日文的每个字符由多个字节进行编码),再进行合并过程,一定程度上解决了这一语言兼容的问题。
三、WordPiece和Unigram模型
BPE以训练语料中的频数为依据,产生新的子词加入字典,这一过程中可能会遇到前面案例中出现的两个词对频数相同的情况(“er”和“r·”),这时BPE模型并不能进行区分。WordPiece则使用训练语料X生成的概率作为依据。假设所有的子词是相互独立的,语料中的第i个子词为xi,那么从字典生成出语料的概率将会是各个子词的出现概率p(xi)的乘积:
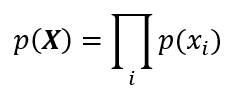
WordPiece模型将尽量产生一个最大化p(X)的字典。在决策是否合并两个相邻的子词A、B时,WordPiece模型使用合并对总概率的影响大小
 来进行判断。在上面的例句中,e、r、“·”出现的频次分别为4、2、5,但“er”和“r·”的频次是相同的,此时p(e)p(r)
来进行判断。在上面的例句中,e、r、“·”出现的频次分别为4、2、5,但“er”和“r·”的频次是相同的,此时p(e)p(r)
Unigram模型也是基于生成概率最大化的思想。和前两个模型的主要区别在于,初始化字典时,Unigram会先启发式地尽可能产生一个非常大的字典(如直接将语料中所有可能的子词组合计算一下频率再取TOP若干个),再逐步缩小到期望的规模。缩小的过程中,模型使用p(xi)和字典进行EM算法来优化目标似然函数(基于生成概率构造)。模型重复进行以下步骤:
1.固定字典,计算所有子词的p(xi)
2.固定p(xi),计算每个子词如果移出字典后,目标似然函数的损失
3.按照损失值排序保留前η%的子词(为解决OOV问题,一直保留所有字母等基本字符)
四、总结
子词模型作为词嵌入的重要技术之一,能够为自然语言处理的各种模型的训练提供更好的字典,加强模型的泛化能力,并解决一些诸如OOV问题、多语言问题等基本问题。如今许多子词模型已经被整理成开源工具包供开发者使用,如谷歌推出的SentencePiece等。
胡赟豪
,硕士毕业于清华大学经济管理学院,现从事于互联网数据科学相关工作,主要技术探索方向为机器学习、大语言模型及其在商业中的应用。
未来,数据派THU将围绕大数据、人工智能等领域推出
“科普之旅”
系列文章。










