构建智能运维平台,运行监控和故障报警是两个绕不过去的重要部分。本次分享主要是数人云工程师介绍引入 SRE 理念后的基于时间序列数据存储的报警工程实践。
SRE 报警介绍
今天我分享的主题是 SRE 基于时间序列数据的报警实践,既然是基于时间序列。
首先,我先简单介绍一下什么是时间序列数据。
时间序列( time series )数据是一系列有序的数据。通常是等时间间隔的采样数据。时间序列存储最简单的定义就是数据格式里包含 timestamp 字段的数据。时间序列数据在查询时,对于时间序列总是会带上一个时间范围去过滤数据。同时查询的结果里也总是会包含 timestamp 字段。
监控数据大量呈现为时间序列数据特征,所以,为了应对复杂的监控数据格式,在每一份数据中加上时间字段。区别于传统的关系型数据库,时间序列数据的存储、查询和展现进行了专门的优化,从而获得极高的数据压缩能力、极优的查询性能,特别契合需要处理海量时间序列数据的物联网应用场景。
Google 的监控系统经过 10 年的发展,经历了从传统的探针模型、图形化趋势展示的模型到现在基于时间序列数据信息进行监控报警的新模型。这个模型将收集时间序列信息作为监控系统的首要任务,同时发展了一种时间序列信息操作语言,通过使用该语言将数据转化为图标和报警取代了以前的探针脚本。
监控和报警是密不可分的两个部分,之前我们公司的 CTO 肖德时曾经做过关于基于时间序列数据监控实践的分享,在本次分享中就不重复介绍前面的监控部分,感兴趣的同学可以去看看老肖的
文章
。
运维团队通过监控系统了解应用服务的运行时状态,保障服务的可用性和稳定性。监控系统也通常会提供 Dashboard 展示服务运行的指标数据,虽然各种折线图看着很有趣,但是监控系统最有价值的体现,是当服务出现异常或指标值超过设定的阀值,运维团队收到报警消息,及时介入并恢复服务到正常状态的时候。
SRE 团队认为监控系统不应该依赖人来分析报警信息,应该由系统自动分析,发出的报警要有可操作性,目标是解决某种已经发生的问题,或者是避免发生的问题。
监控与报警
监控与报警可以让系统在发生故障或临近发生故障时主动通知我们。当系统无法自动修复某个问题时,需要一个人来调查这项警报,以决定目前是否存在真实故障,采取一定方法缓解故障,分析故障现象,最终找出导致故障的原因。监控系统应该从两个方面提供故障的信息,即现象和原因。
黑盒监控与白盒监控
黑盒监控: 通过测试某种外部用户可见的系统行为进行监控。这是面向现象的监控,提供的是正在发生的问题,并向员工发出紧急警报。对于还没有发生,但是即将发生的问题,黑盒监控无能为力。
白盒监控依靠系统内部暴露的一些性能指标进行监控。包括日志分析, Java 虚拟机提供的监控接口,或者一个列出内部统计数据的 HTTP 接口进行监控。白盒监控能够通过分析系统内部信息的指标值,可以检测到即将发生的问题。白盒监控有时是面向现象的,有时是面向原因的,这个取决于白盒监控提供的信息。
Google 的 SRE 大量依赖于白盒监控。
设置报警的几个原则
通常情况下,我们不应该仅仅因为“某个东西看起来有点问题”就发出警报。
紧急警报的处理会占用员工宝贵的时间,如果该员工在工作时间段,该报警的处理会打断他原本的工作流程。如果该员工在家,紧急警报的处理会影响他的个人生活。频繁的报警会让员工进入“狼来了”效应,怀疑警报的有效性和忽略报警,甚至错过了真实发生的故障。
设置报警规则的原则:
-
发出的警报必须是真实的,紧急的,重要的,可操作的。
-
报警规则要展示你的服务正在出现的问题或即将出现的问题。
-
清晰的问题分类,基本功能是否可用;响应时间;数据是否正确等。
-
对故障现象报警,并提供尽可能详细的细节和原因,不要直接对原因报警。
基于时间序列数据进行有效报警
传统的监控,通过在服务器上运行脚本,存储返回值进行图形化展示,并检查返回值判断是否报警。 Google 内部使用 Borgmon 做为监控报警平台。
在 Google 之外,我们可以使用 Prometheus 作为基于时间序列数据监控报警的工具,进而实践 SRE 提供的白盒监控理念。
监控报警平台架构图:

监控报警组件
搭建测试环境
为了方便测试,我们在测试服务器上用容器运行以上组件,测试服务器地址 192.168.1.188 。
-
启动两个 Nginx 容器,并分配不同的 label 标识一个属于 Dev 组的应用,一个属于 Ops 组的应用。
-
启动 cAdvisor 容器,端口映射 8080 。
-
启动 Alertmanager 容器,端口映射 9093 ,配置文件中指定 Alerta 的地址作为 Webhook 的通知地址。
-
启动 Prometheus 容器,端口映射 9090 , CMD 指定“-alertmanager.url ”地址为 Alertmanager 的地址。
-
启动 MongoDB 作为 alerta 的数据库
-
启动 Alerta ,端口映射为 8181
容器运行截图:

应用指标收集
cAdvisor 原生提供 http 接口暴露 Prometheus 需要收集的 metrics ,我们访问
http://192.168.1.188:8080/met...
。
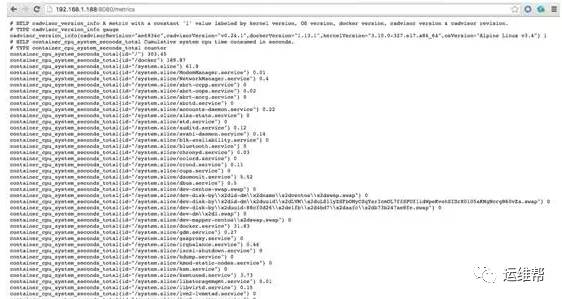
在 Prometheus 的配置文件里配置 cAdvisor 的地址作为 target 地址,可以在 Prometheus 的 Web 页面查看 Targets 的状态。

在 Prometheus 的 Graph 页面,可以对收集的数据进行查询和图形化展示。

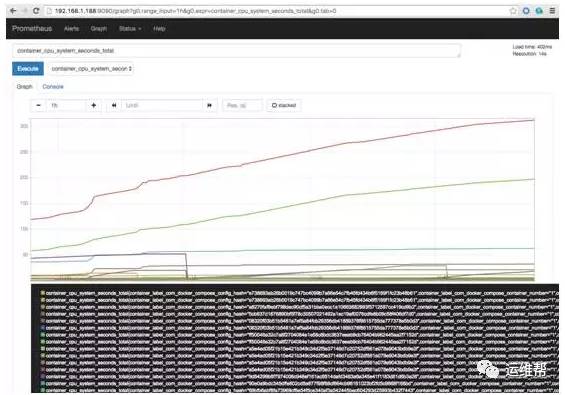
报警规则配置
我们针对容器应用的 CPU 使用率配置报警规则,规则如下:

图中分别针对 dev 组和 ops 组设置了应用容器的报警规则,报警规则的格式:
-
“ Alert ”是报警规则的名字,名字间不能有空格,可以用下划线链接;
-
“ IF ”是数据的查询表达式,截图中的语句内容查询指标“ container_cpu_usage_seconds_total ”, label “ container_label_dataman_service ”等于“ web ”, label “ container_label_dataman_group ” 等于“ dev ”,用函数 irate()计算指标在上一个 5 分钟内每秒钟 CPU 使用时间的差值的比率。简单点说计算了 CPU 占用时间的百分比。这里两个报警规则中的表达式有点区别,是为了区分两个组的应用。
-
“ FOR ”是报警状态持续超过 1 分钟后,将报警由状态“ PENDING ”改为“ FIRING ”,报警将交给 Alertmanager 处理。
-
“ LABELS ”为自定义数据,我们在这里指定了报警的级别和显示“ IF ”中表达式的值。
-
“ ANNOTATIONS ”为自定义数据,我们在这里提供报警的现象和原因介绍。
触发报警
我们用 stress 对两个容器的 CPU 进行加压,使得容器的 CPU 使用率超过报警的阀值。在 Prometheus 的页面我们看到了产生的报警。
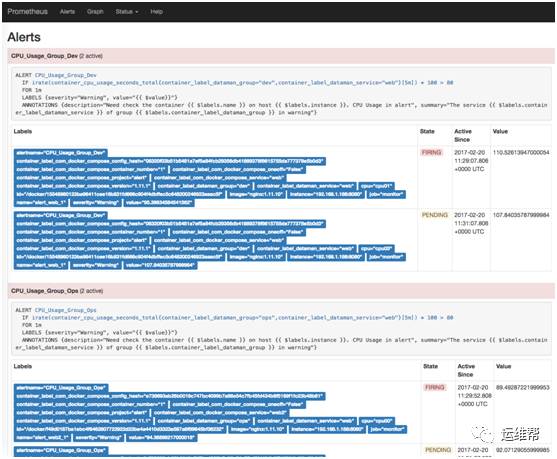
在 Alertmanager 页面看到从 Prometheus 发过来的报警。
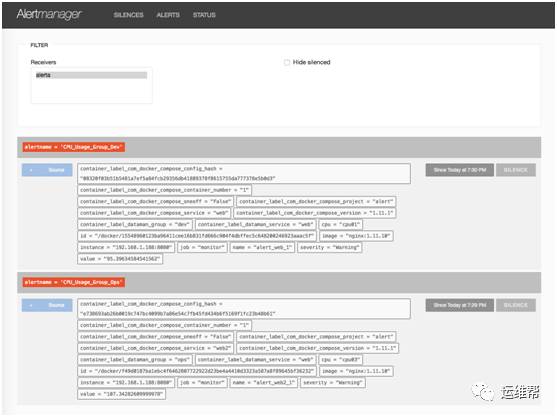
可以看到 Alertmanager 还把报警消息推送给了 alerta 。
报警消息展示
Alerta 对接收到的报警进行保存并展示。
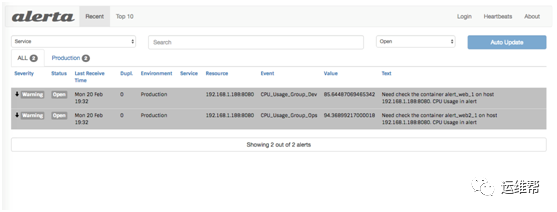
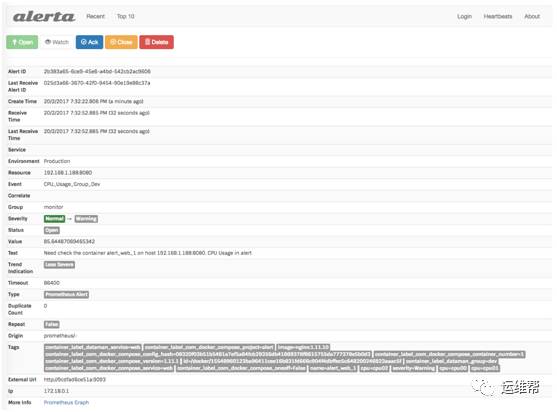
选择某条报警信息,可以进入详情,在详情页可以对报警进行 Ack ,关闭等操作。
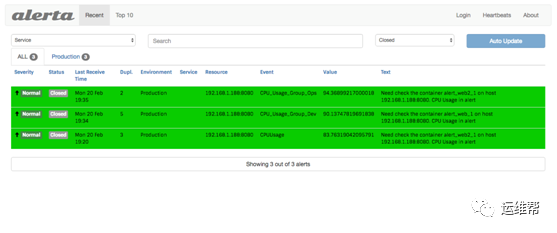
报警结束后,可以在 alerta 中查看报警的历史,即处于关闭状态的报警。
结束语
这里我们简要的介绍了下如何运用 cAdvisor , Prometheus , Alertmanager 和 Alerta 实现 Google SRE 中介绍的基于时序数据的报警实践,针对性能指标的报警只是最基础的报警方式,我们后续还会介绍如何配置和采集应用的内部数据指标,并进行监控报警的配置。应用系统的监控是一个复杂的过程,需要不断的调整以应对服务的运行状况和服务质量,也需要我们不断的吸取 SRE 的运维理念并在实践中落地。 SRE 可以说是 DevOps 在运维方面的具体实现,它既包括了理念、文化也包括了像监控报警这样具体的运维和工程实践。现在国内越来越多的企业开始关注 SRE 如何在整个生命周期为项目提供持续性支持。但是如何能够让 SRE 理念在本土落地,如何寻找到适合企业自身的 SRE 之路,数人云也在不断摸索并持续将现有的经验分享给大家,期望大家都能共同汲取 SRE 的营养以不断提升企业的运维和工程实践的水平。谢谢!
Q&A
Q :告警信息收到后,系统有没有能力自动解决告警报告的问题?还是需要人工解决问题?谢谢
A :这个要分情况,好的机制是报警应该发出的是新的问题,然后通过反馈机制,让同类的问题不再发生,或者由监控系统自身解决。
Q : InfluxDB 系列方案是否有考虑, Grafana 最新版也有了很好的告警机制,是否有尝试?
A :曾经考虑并实践过 InfluxDB 的 TICK 组合方案,非常方便可以实现数据收集存储处理展示的完整流程。通过对比,我们发现 Prometheus 更符合 Google SRE 对于监控的理念,自身社区也非常活跃,就转向 Prometheus 的方案了。 Grafana 实现了强大的可视化配置报警规则的功能,对于原本只做为展示的工具,是很好的增强,这个对我们的启发也很大,也在学习中。
Q :报警规则配置是什么语法,是否可以可视化?
A : Prometheus 是在配置文件中描述报警规则。可以自己动手实现可视化。
Q :数据量庞大的情况怎么解决,比如说万台机器, 500 个指标数据等 一分钟一个点 60
24
30
500
10000 的数据量,如何保存,如何快速查询数据。 需要什么样的架构和硬件?
A :简单回答, Prometheus 可以通过分组支持大规模的集群,但是达到某个确定的规模,那就需要实践给出答案了。
Q :请问在监控报警方面有没有考虑或实践过智能预警,比如基于历史监控数据,通过机器学习,实现提前预警等?
A :这个不是 SRE 推荐的方式,报警应该简单,高级的功能会模糊真实的意图。
Q :请问基于此方案部署的主机和容器规模有多大,基于什么频率进行监控收集?
A :本次分享的是测试环境,规模不大。 Prometheus 定时从 cAdvisor 收集数据,抓取频率 5s 。
Q : cAdvisor 采集数据的性能表现怎么样,占用主机的资源大嘛?
A :性能表现优异,担心占用资源,可以在启动容器时进行资源限制。
Q : APP 自身业务逻辑需要监控的数据,比如 Counter , Gauge 等,传统用 Zabbix 等可以进行数据采集。我明白 cAdvisor 是对 Container 进行数据采集。但是有没有可能把 APP 自身的监控和 Container 的监控结合?
A :后续话题,我们会实践有关应用的监控报警。 Prometheus 的逻辑是定时从 exporter 抓取数据,然后对存储的时序数据,通过 PromQL 进行查询和分析,所以是可以实现 APP 自身的监控和容器监控的结合的。
运维帮「
运维大咖CLUB
」招募会员:如果你是甲方
运维总监/运维经理
,欢迎加入我们,请联系微信yunweibang555
商务合作,请加微信yunweibang555






