选自
kdnuggets
作者:
Reena Shaw、KDnuggets
机器之心编译
参与:
Nurhachu Null、黄小天
本文先为初学者介绍了必知的十大机器学习(ML)算法,并且我们通过一些图解和实例生动地解释这些基本机器学习的概念。我们希望本文能为理解机器学习基本算法提供简单易读的入门概念。
机器学习模型
在《哈佛商业评论》发表「数据科学家是 21 世纪最性感的职业」之后,机器学习的研究广受关注。所以,对于初入机器学习领域的学习者,我们放出来一篇颇受欢迎的博文——《初学者必知的十大机器学习算法》,尽管这只是针对初学者的。
机器学习算法就是在没有人类干预的情况下,从数据中学习,并在经验中改善的一种方法,学习任务可能包括学习从输入映射到输出的函数,学习无标签数据的隐含结构;或者是「基于实例的学习」,通过与存储在记忆中的训练数据做比较,给一个新实例生成一个类别标签。基于实例的学习(instance-based learning)不会从具体实例中生成抽象结果。
机器学习算法的类型
有三类机器学习算法:
1. 监督学习:
可以这样来描述监督学习:使用有标签的训练数据去学习从输入变量(X)到输出变量(Y)的映射函数。
Y = f (X)
它分为两种类型:
a. 分类:通过一个给定的输入预测一个输出,这里的输出变量以类别的形式展示。例如男女性别、疾病和健康。
b. 回归:也是通过一个给定的输入预测一个输出,这里的输出变量以实数的形式展示。例如预测降雨量、人的身高等实数值。
本文介绍的前 5 个算法就属于监督学习:线性回归、Logistic 回归、CART、朴素贝叶斯和 KNN。
集成学习也是一种监督学习方法。它意味着结合多种不同的弱学习模型来预测一个新样本。本文介绍的第 9、10 两种算法--随机森林 Bagging 和 AdaBoost 提升算法就是集成学习技术。
2. 非监督学习:
非监督学习问提仅仅处理输入变量(X),但不会处理对应的输出(也就是说,没有标签)。它使用无标签的训练数据建模数据的潜在结构。
非监督学习可以分为 2 种类型:
a. 关联:就是去发觉在同一个数据集合中不同条目同时发生的概率。广泛地用于市场篮子分析。例如:如果一位顾客买了面包,那么他有 80% 的可能性购买鸡蛋。
b. 聚类:把更加相似的对象归为一类,而不是其他类别对象。
c. 降维:顾名思义,降维就是减少数据集变量,同时要保证重要信息不丢失。降维可以通过使用特征提取和特征选择方法来完成。特征选择方法会选择原始变量的一个子集。特征提取完成了从高维空间到低维空间的数据变换。例如,主成分分析(PCA)就是一个特征提取方法。
本文介绍的算法 6-8 都是非监督学习的例子:包括 Apriori 算法、K-均值聚类、主成分分析(PCA)。
3. 强化学习:
强化学习是这样一种学习方法,它允许智能体通过学习最大化奖励的行为,并基于当前状态决定下一步要采取的最佳行动。
强化学习一般通过试错学习到最佳行动。强化学习应用于机器人,机器人在碰到障碍物质之后会收到消极反馈,它通过这些消极反馈来学会避免碰撞;也用在视频游戏中,通过试错发现能够极大增长玩家回报的一系列动作。智能体可以使用这些回报来理解游戏中的最佳状态,并选择下一步的行动。
监督学习
1. 线性回归
在机器学习中,我们用输入变量 x 来决定输出变量 y。输入变量和输出变量之间存在一个关系。机器学习的目标就是去定量地描述这种关系。
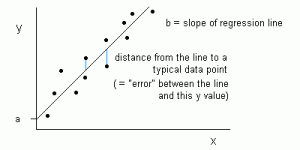
图 1:以一条直线的形式展示出来的线性回归:y = ax +b
在线性回归中,输入变量 x 和输出变量 y 的关系可以用一个方程的形式表达出来:y=ax+b。所以,线性回归的目标就是寻找参数 a 和 b 的值。这里,a 是直线的斜率,b 是直线的截距。
图 1 将一个数据集中的 x 和 y 用图像表示出来了。如图所示,这里的目标就是去寻找一条离大多数点最近的一条直线。这就是去减小一个数据点的 y 值和直线之间的距离。
2.Logistic 回归
线性回归预测是连续值(如厘米级的降雨量),logistic 回归预测是使用了一种变换函数之后得到的离散值(如一位学生是否通过了考试)。
Logistic 回归最适合于二元分类问题(在一个数据集中,y=0 或者 1,1 代表默认类。例如:在预测某个事件是否会发生的时候,发生就是 1。在预测某个人是否患病时,患病就是 1)。这个算法是拿它所使用的变换函数命名的,这个函数称为 logistics 函数(logistics function,h(x)= 1/ (1 + e^x)),它的图像是一个 S 形曲线。
在 logistic 回归中,输出是默认类别的概率(不像线性回归一样,输出是直接生成的)。因为是概率,所以输出的值域是 [0,1]。输出值 y 是通过输入值 x 的对数变换 h(x)= 1/ (1 + e^ -x) 得到的。然后使用一个阈值强制地让输出结果变成一个二元分类问题。
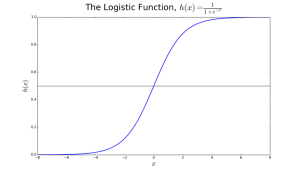
图 2:确定一个肿瘤是恶性的还是良性的回归。如果概率 h(x)>0.5,则是恶性的
在图 2 中,为了判断一个肿瘤是不是恶性,默认变量被设置为 y=1(肿瘤是恶性的);变量 x 可能是对一个肿瘤的检测结果,例如肿瘤的尺寸。如图中所示,logistics 函数将变量 x 的值变换到了 0 到 1 之间。如果概率超过了 0.5(图中的水平线为界),肿瘤就被归类为恶性。
logistic 回归的方程 P(x) = e ^ (b0 +b1*x) / (1 + e^(b0 + b1*x))可以被转换为对数形式: ln(p(x) / 1-p(x)) = b0 + b1*x。
logistic 回归的目标就是使用训练数据来寻找参数 b0 和 b1 的值,最小化预测结果和实际值的误差。这些参数的评估使用的是最大似然估计的方法。
3. 分类和回归树
分类和回归树(CART)是决策树的一种补充。
非终端节点(non-terminal node)包含根节点 (root node) 和中间节点 (internal node)。每一个非终端节点代表一个单独的输入变量 x 和这个变量的分支节点;叶节点代表的是输出变量 y。这个模型按照以下的规则来作出预测:
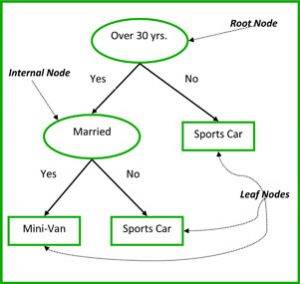
图 3:决策树的一些部分
4. 朴素贝叶斯法
在给定一个早已发生的事件的概率时,我们用贝叶斯定理去计算某个事件将会发生的概率。在给定一些变量的值时,我们也用贝叶斯定理去计算某个结果的概率,也就是说,基于我们的先验知识(d)去计算某个假设(h)为真的概率。计算方法如下:
P(h|d)= (P(d|h) * P(h)) / P(d)
其中,
-
P(h|d) = 后验概率。就是假设 h 为真概率,给定的数据相当于先验知识 d。其中 P(h|d)= P(d1| h)* P(d2| h)*....*P(dn| h)* P(d)。
-
P(d|h) = 似然度。假设 h 正确时,数据 d 的概率。
-
P(h) = 类先验概率。假设 h 正确的额概率。(无关数据)
-
P(d) = 预测器先验概率。数据的概率(无关假设)
这个算法被称为「朴素」的原因是:它假设所有的变量是相互独立的,这也是现实世界中做出的一个朴素的假设。
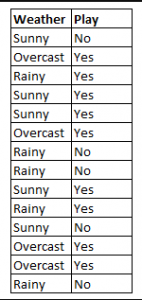
图 4:使用朴素贝叶斯法来预测变量「天气」变化状态
以图 4 为例,如果天气=晴天,那么输出是什么呢?
在给定变量天气=晴天时,为了判断结果是或者否,就要计算 P(yes|sunny) 和 P(no|sunny),然后选择概率较大的结果。
计算过程如下:
->P(yes|sunny)= (P(sunny|yes) * P(yes)) / P(sunny)
= (3/9 * 9/14 ) / (5/14)
= 0.60
-> P(no|sunny)= (P(sunny|no) * P(no)) / P(sunny)
= (2/5 * 5/14 ) / (5/14)
= 0.40
所以,天气=晴天时,结果为是。
5.KNN
KNN 使用了整个数据集作为训练集,而不是将它分为训练集和测试集。
当给定的一个数据实例时,KNN 算法会在整个数据集中寻找 k 个与其新样本距离最近的,或者 k 个与新样本最相似的,然后,对于回归问题,输出结果的平均值,或者对于分类问题,输出频率最高的类。k 的值是用户自定义的。
样本之间的相似性是用欧氏距离或者汉明(Hamming)距离来计算的。
非监督学习算法
6.Apriori 算法




