本文为友情转发唐杰总投稿,供读者参考学习,不完全代表编者观点。
NVMe over fabric
从
2016
年
6
月的协议第一版出来之后,目前来看的最大的变化就是
TCP
协议的加入。对于物理上的三种
Fabric
来讲,
IB
,
FC
和
Ethernet
的大户基本上不用质疑了。对于
TCP
协议的加入,坊间的说法是
Facebook
比较看好
TCP
,虽然他们的
OCP
的
NVMe JBOF
也有一个支持
100G RCOE V2
的定制机头。这个协议目前的进展很快,在
Linux kernel
中已经有支持了。
扩展阅读
:《
NVMe over TCP:iSCSI的接班人?
》
对于
TCP
的加入,
Mellanox
无疑成为最大的受害者,在
RDMA
的
ROCEv2
和
iWarp
之间,
RoCEv2
已经成为清晰的获胜者。虽然目前
Mellanox
和
Broadcom
在无损以太网上的实现不同,相信随着部署规模的扩大,坑应该会被填上。而
TCP
无疑是
Hyperscale
网络管理工程师的福音,
TCP
的扩展性和互操作性基本上没问题。
基于
Mellanox
的一个
live DEMO
的数据,目前协议里面实现的最大
IOPS
,
100G
的带宽
TCP
应该在
2.4M
左右,同样的
NVMe
硬件配置,
RoCEv2
在
2.7M
左右。没有机会问在使用
NVMe over TCP
的时候,
Mellanox
使用的是什么样的
100G
的网卡。不过,很有可能是同样的
100G
的
ConnectX-5
,跑不同的协议,毕竟
Mellanox
的
ConnectX
系列的网卡也支持标准的
TCP
的诸如
check sum /LSO/RSS
之类的硬件
offloading
。
Lightbits
对于一直在做
ASIC
的
lighbits
来讲,他们关注的点基本上和
Facebook
完全一致,
FlashI/O
访问的
long tail
是他们一直在试图优化的。根据他们的胶片,
over TCP
的
fabric
额外延时基本上是
over RoCEv2
的两倍,但是这个还是
iSCSI
的延时的
30%
。他们的逻辑是
over Fabric
只是整个
I/O
堆栈的一部分,在他们看来,加上
NVMe SSD
以及
kernel
软件的延时,
over TCP
和
over RoCEv2
的差别就很小。对于他们的
long tail
的优化,他们将主要是对于
TCP
支持的众多的
RFC
以及流控的优化,而且貌似
lighbits
,
Intel
,
Facebook
的三家的分工很明确,
lightbits
很明白地告诉我他们不关系除了
ASIC
以外的东西。目前没有看到他们的
ASIC
的相关信息,主要的
Topic
还是集中的架构和软件上。
Kazan Network
Kazan
的
ASIC
芯片已经回来了,他们展台上展示了单个
Intel Optane+Fuji
,
Intel NVMe SSD+Fuji
,
Intel SSD + XIlinx FPGA VUP
的三个
live DEMO
,性能的确很好。可能是因为
Kazan
在
2016
年的
FMS
上已经展示过了,因此这次的展台的三个东西应该是意料之中,人很少。我就有机会多打听一下:
-
RoCEV2
和
iWarp
的性能没有差异。说是数据通路类似,基本忽略了
TCP/UDP
的协议消耗不同。
-
我问他如何处理
TCP
的
retransmissionbuffer
的问题,因为毕竟他们没有
DDR
。哥们回答我“
secret sauce “,
和回答其他技术问题一样。
-
因为目前的芯片是
1X100G,
问他什么时候可以支持
Dual 100G
,答案是在
bring up
现在的芯片,
Dual 100G
已经有规划了。
-
从
Kazan
的演讲内容来看,他们使用了有限状态机的机制来实现流的处理。
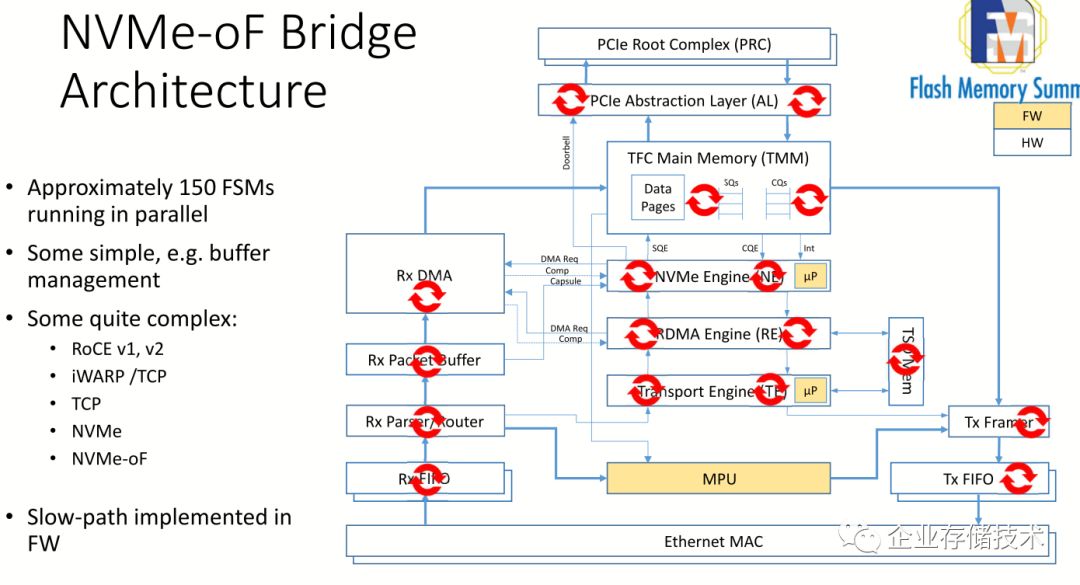
Marvell
马牌的这个
NVMeOF Bridge
的芯片
88SN2400
的确很拉风。整个方案是
Toshiba
的
SSD
,
Marvell
的
NVMe toEthernet
的
Bridge
桥片,以及来自深圳
Aupera
的
JBOF
方案,整个方案都在门口的
Toshiba
展台,基本上有
Toshiba
以色列的一帮
OCZ
的人在介绍。

这个就是和之前
Seagate
做的
IP
盘类似,使用
2X25G
的
Ethernet
接口组织
JOBF
,主要的收益是:
1.
可以做到
100%
的前后带宽匹配,不用和
PCIE
一样需要保持上下带宽
1
:
2
的配比。目前前面是
24
个
NVMe
,
48
个
25G
的
Ethernet
,后面服务的是
12
个
100G
的端口。
2. Aupera
的
CEO
讲,他们的
JBOF
的设计成本要比用
PCIESW
成本低,因为
PCIE SW
的两个厂家现在都是坐地起价。
Ethernet
端口的选择要多一些。
3.
方便管理,
Ethernet
盘的热插拔要比
PCIE
简单。
对于这个方案,我也显示了很大兴趣,特别是
Ethernet
成本比较低的这个结论,因为目前使用的是
NVme+Bridge interposer
的架构,和背板的接口是使用专用的接口,因此很难有一个整体的比较。作为前
Seagate
员工,我们内部认为
Kinetic
的
IP
硬盘的失败归结于市场上没有性价比好的
Chassis
,千兆以太网的交换机的端口成本比
SAS expender
要高太多了。因此有一个比较靠谱的
Chassis
可能是
Marvel
方案的一个关键因素,只有一家
Aupera
还是不够的。
Marvell
的确有计划把整个
Bridge
芯片和
SSD
控制器和在一起,这个和
NVMe
协议标准里面,把命令分成了
ADMIN
,
FABRIC
,
I/O
类似,尽可能做到本地盘和远端的盘没有差别。
这种方案在架构上的确很有意义,随着单盘的容量和性能增加,可能会出现
Intel Ruler
这种
SSD
,具有
RoCEv2
的接口,可以通过高速
Ethernet
形成存储集群,只是这里面的管理功能可能不是单单靠
JOBF
的管理可以支持的。
比如,对于多个
IP
盘之间的数据保护,以及数据的通讯,如果都要靠
Host
来实现,会把
host
变成整个方案的性能瓶颈。
Mellanox Bluefeild
Mellanxo
的
Bluefeild
本质上就是
ConnectX-5+ARM72
的
SoC
架构,基本上不用介绍太多了。直接上照片把:

上面的双宽的双
PCIE Gen3 X16
插卡,不清楚是为那个存储厂家做的控制卡,可以看到使用两组
72Bite
的标准
DRAM
。下面那个
JBOF
控制器形态的设计是神达电脑的,这个和
Mellanox
自己的
Bluefield
参考设计类似。
Broadcom Stingray
Broadcom
的站台有两个,都不大。这个的确是新老板的风格,但是站台的东西都很重要。一个网卡芯片,一个之前
PLX
的
PCIE4.0
以及
5.0
的东西。对于
Broadcom
的
Stingray
,
PS1100R
的产品,的确和
Mellanox
是针锋相对的竞争。目前还没有看到他们太多的数据,相信以后有的。
https://www.broadcom.com/products/ethernet-connectivity/network-adapters/ps1100r
这是他们发布的信息。在站台上没有机会问太多问题。
Altera
这个公司也听了很对年了,一直没有机会直接接触,毕竟是用
Intel
的
FPGA
的方案,和我司的方案直接竞争。在这次他们的站台上,人家除了不让我拍照以为,还是很热心得回答了我很多问题,比如对于
Host side
软件的支持问题,
target
这边和
PCIE Switch
的交互。
目前看到的比较的槽点也就是
25G
网络的支持,和
Intel
的其他
FPGA
的网卡方案类,因为
25G
的不成熟,都是用了两颗大大的
Marvell
的
25 MAC
芯片。
Attala
之前在
Host
上只支持自己的
HBA
,因为客户的要求,目前也支持标准的
Mellanox
网卡了。
Xilinx
Xilinx
基于
ZU19-EG
的
HHHL
的
NVMeoF
的控制器和天鸿的
JBOF
的展示,这个是我之前花了很多力气的一个
DEMO
,这个要感谢天鸿,以及我们的
FPGA
的办卡合作商
Molex
的功劳。放个照片吧,不做过多解释,欢迎大家骚扰了解详情。

Dell EMC
的总结
David
的胶片,我推荐每个架构师都应该学习一下,用很快的语速讲了
NVMe oF
的方方面面,使用自己的方法论进行了很细致的分析。
David
在
NVMe
协议组织里也很活跃,是很多
TAP
的作者,任职
Dell EMC
的
CTO Office
,的确是偶像级的大神。
第一个是
SCSI over FC
和
NVMe over FC
的对比。在标准的实现中,不做任何修改。
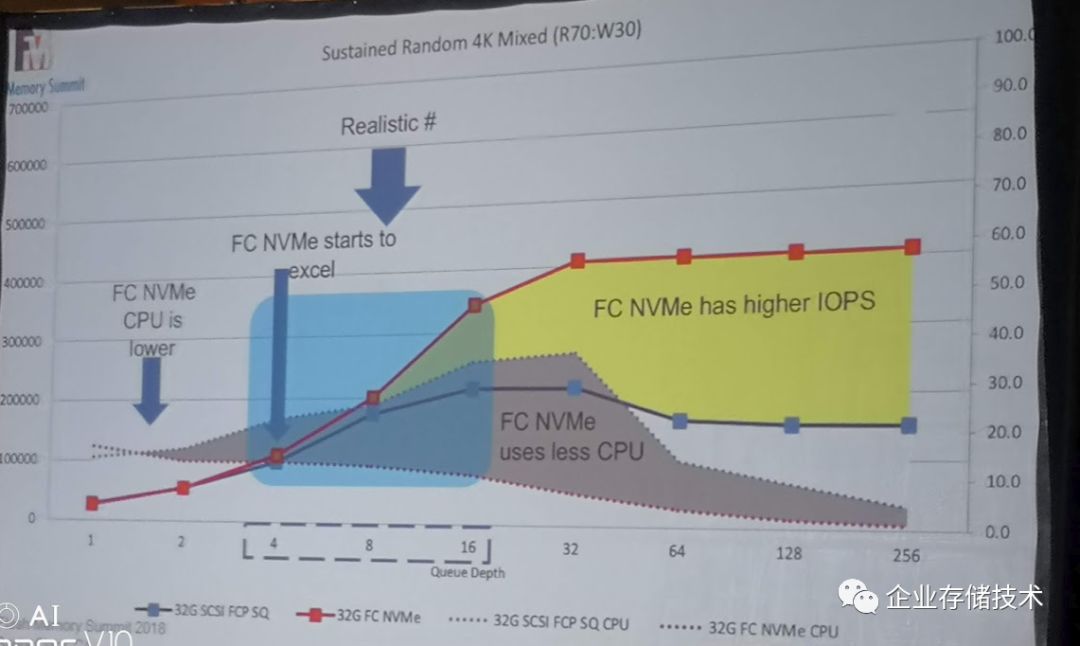
可以看到,和大家想象的一样,新的东西肯定更快,更好。可是,至于新的东西为什么会更快,更好,
David
做了分析:
-
NVMe
的性能的确比
SCSI
好,但是在常用的
Queue Depth 4
到
16
并没有本质的差别
-
NVMe
的
CPU
占用低,主要是
I/O Path
短。
SCSI
是三层架构的。
-
对于
I/O only
的负载,
queue
越多越好,大量的
queue
的批处理是利器。
因为
NVMe
天生是多队列的,
SCSI
从
BUS
技术开始,并行的能力一直是个问题。
Linux SCSI FCP
的队列是单个
Queue
的,
Linux NVMe FC
的队列是多个
Queue
。如果把
Linux SCSI
的
FCP
改成多个
Queue
会如何呢?
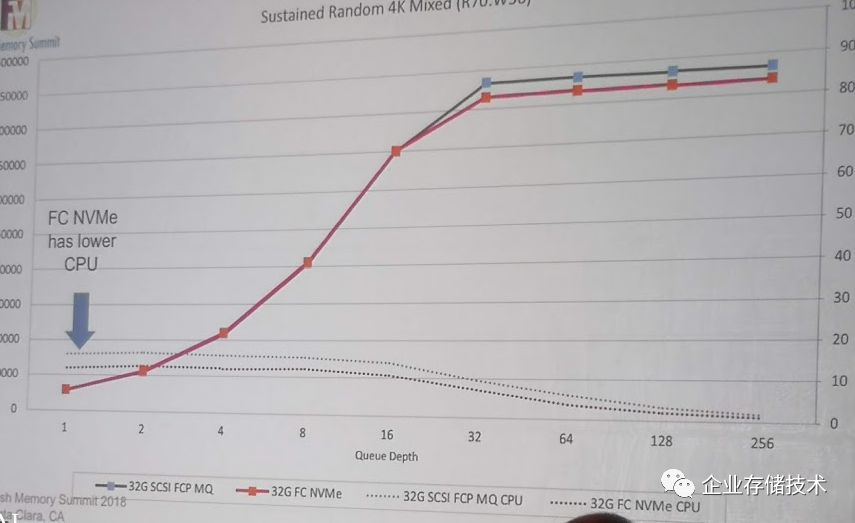
大家都差不多了,可以看出,在同样的底层
Fabric
,协议为所谓新旧,主要有多队列,大
queue depth
,大家都是平等的。
因此,可以得出一个比较有意思的结论,
NVMe over Fabric
的关键还是在
Fabric
,如果你底层的
Fabric
有性能的限制,其实上面的存储协议换了
NVMe
也没用。
iSCSI
,在说你呢?
总结一下,
NVMe over Fabric
的目标很清楚,构建下一代的存储网路。在大家都通过多队列解决了性能问题之后,存储系统的主要挑战就是管理问题了。目前
NVMe
协议的路标如下:
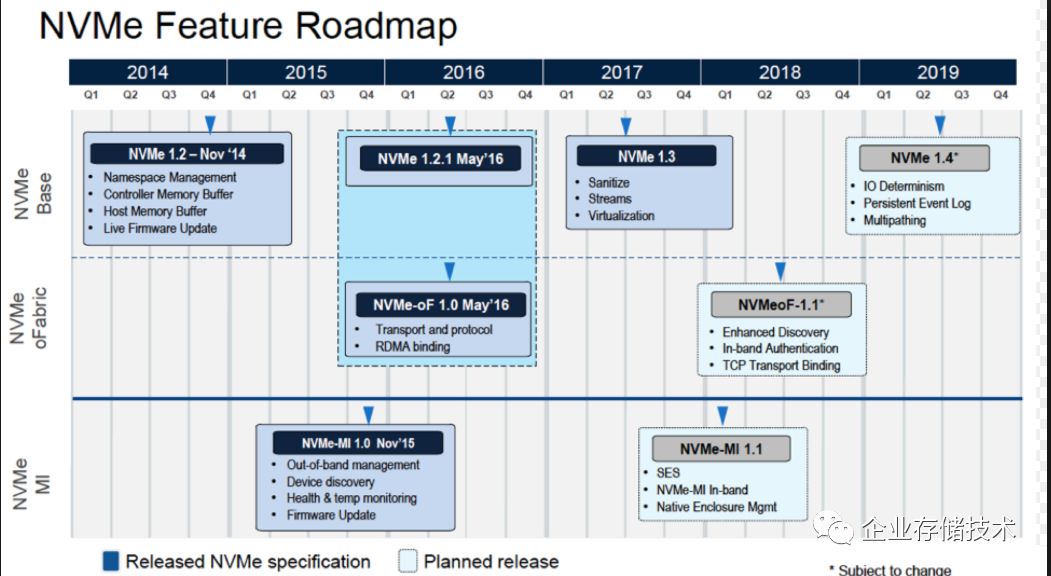
注
:本文只代表作者个人观点,与任何组织机构无关,如有错误和不足之处欢迎在留言中批评指正。
进一步交流
技术
,
可以
加我的
QQ/
微信:
490834312
。如果您想在这个公众号上分享自己的技术干货,也欢迎联系我:)
尊重知识,转载时请保留全文,并包括本行及如下二维码。感谢您的阅读和支持!《企业存储技术》微信公众号:
HL_Storage

长按二维码可直接识别关注
历史文章汇总
:
http://www.10tiao.com/author/index?authorId=691





