日本在半导体产业尤其是处理器、SoC芯片等方向似乎没有太多声音。从近几年日本半导体产业发展来看,虽然具体的产品并没有太多,不过但凡有新品出现,都以独特的设计和规格让人眼前一亮。NEC在2017年发布了一款全新的矢量处理器,并在2018年正式将其推向市场。和传统的通用处理器、GPU加速器相比,矢量处理器还比较少见。今天,本文将和你一起解读NEC矢量处理器背后的秘密。
NEC在高性能处理器设计上拥有丰富的经验,其辉煌的顶点是在2002年左右推出的Earth Simulator Computer也就是地球模拟器超级计算机,这款产品占据了全球最快超级计算机的宝座长达三年之久,并且大部分核心处理器都由NEC设计完成,其特点就是先进的矢量计算设计。不过,由于当时的普通用户对矢量计算需求不足,因此这类产品距离主流市场较远,NEC的矢量处理器往往只能用于大型设备,完全称不上大众化。

▲NEC在高性能处理器研究上具有丰富的经验
事物在发生着变化。随着AI计算的兴起,矢量加速器又开始逐渐成为很多用户的选择。鉴于此,NEC又开始重新考虑将矢量计算相关产品推向主流市场。2017年,NEC宣布推出全新的矢量超级计算机SX-Aurora TSUBAME,其中的计算核心Vector Engine超级矢量卡(下文简称为“VE卡”)一经发布就引起了众人关注。
这款采用主流PCIe接口设计、专攻矢量计算的产品使用范围极其广泛,NEC称其能够支持“标准环境”,也就是支持Linux和英特尔x86架构。考虑到NEC在之前矢量处理器设计上的保守,这不得不说是一次重大改变。
对长期关注本刊的读者来说,矢量和标量的概念应该不陌生。所谓矢量,又可称为向量,就是指具有方向和大小、且满足平行四边形法则的几何对象。标量则只有大小,没有方向。一般来说,矢量多用在工程学、物理学中,比如位移、加速度、力矩、电流密度等都需要用矢量来表示。值得注意的是,矢量在代数中可以用矩阵的方式表示。比如矢量a可以表示为a=[a, b, c],其中a,b,c分别是矢量在三维坐标体系中的坐标值。
由于矢量的数组特性使其可以一次性进行多组计算,因此从一开始矢量计算和相关矢量处理器就颇受重视。从20世纪70年代一直到20世纪90年代,矢量计算和相关矢量处理器都是超级计算机的核心。随之兴起的就是一些处理多重矢量的技术,包括MIMD多指令多数据、SIMD单指令多数据、VLIM超长指令集架构等。这些技术都是希望通过减少指令的数量,通过大量数据进行并行计算,一次性处理更多的内容。
在这里,我们通过一个例子来显示CPU传统的“循环”计算和矢量处理器在计算方面的差异。

从例子可以看出,CPU每次只能加一个数据,10个周期才能做完这件事情。但是对矢量处理器而言,利用规模优势,一次可以执行10次运算,一个周期就能做完10个计算。这是典型的单指令多数据流处理方法。相比传统的CPU,在面对大量并行数据时,矢量处理器效率更高。
由于矢量处理器在大规模数据计算上的优势,因此任何现代计算架构都无法忽视其存在。实际上,现代CPU往往都已经包含了矢量计算模块。比如英特尔和AMD很早就推出了MMX、SSE、3D Now!、AVX等指令集,通过特殊的矢量加速模块和指令,能够大幅度加速相关矢量计算。
不过,CPU依旧有其在逻辑计算上的优势,矢量计算并不是它的重点,一般只有在IBM Power 9这样专为超级计算机和大型机设计的处理器中才专门设计了超大规模的矢量计算核心。即使如此,矢量计算也会给传统处理器带来极大的性能提升。比如英特尔新近加入的AVX-512指令集就能够大幅度加强AI计算等这类天然的大数据量、并行度极高的矢量计算。
除了CPU之外,GPU则可被称为天然的矢量加速器。传统的图形计算的顶点转换本身就是为矢量计算而生,再加上像素计算方面RGBA的固定模式,因此GPU的每一个计算核心都可以被看做一个矢量加速单元。诸如英伟达最新的Volta、Turning等架构,更是可以看成是专为图形计算设计的矢量加速器。
除了CPU和GPU外,市场上还有专门的矢量加速处理器、矢量计算机等。这类产品在核心架构上设计更为简洁,并不包含太多的附加功能,也没有为特定用途优化,其目的就是通过纯粹的矢量计算核心设计,为AI计算、特殊并行计算、超级计算机等提供加速计算的能力。
本期的主角VE超级矢量卡以及其核心SX-Aurora处理器正是这种“纯粹”的产品,专为加速而生,别无旁骛。术业有专攻,专业的加速处理器自然有一定的优势,在架构设计上也可能存在和传统通用加速器的差异,值得研究。

▲SX-Aurora TSUBAME超级计算机
从SX-Aurora TSUBAME超级计算机到VE超级矢量卡
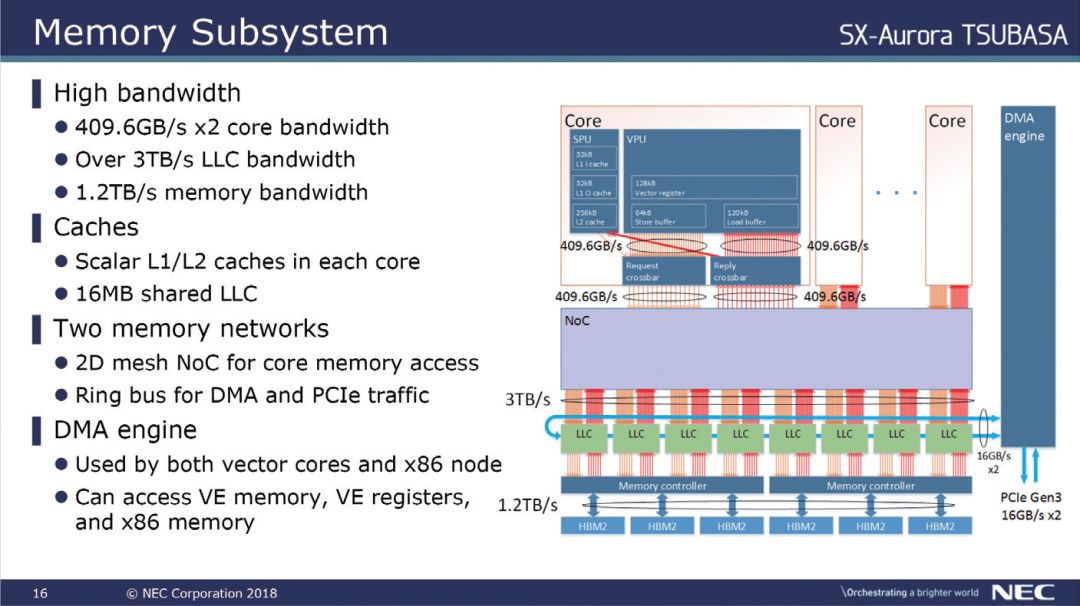
要了解VE超级矢量卡,我们先来一起看看SX-Aurora TSUBAME超级计算机。这款超算是NEC对所谓“标准环境”的首次尝试,其特点就是采用了英特尔的处理器,支持PCIe总线。根据不同的配置,在风冷环境下,SX-Aurora TSUBAME可以实现1颗或者2颗处理器,但是搭载1个、2个、4个甚至8个VE卡的不同配置方案。在水冷环境下,SX-Aurora TSUBAME最多能够实现8个机架搭配64个VE卡的方案。

▲不同规格的SX-Aurora TSUBAME超级计算机和硬件搭配
为了更好地区分不同的配置,NEC也根据不同的配置情况对产品的命名进行了调整。比如1颗处理器搭配1个VE卡的型号是A100-1,这是最基本的方案。进阶配置中,1颗处理器搭配2个VE卡型号被称为A300-2,2颗处理器搭配4个VE卡则是A300-4。风冷条件下最强的型号是A300-8,采用2颗处理器搭配8个VE卡的设计。最高端的则是水冷型号,NEC采用InfiniBand连接8个机架,组成了16颗处理器和64个VE卡的产品,型号则是A500。

▲不同类型的VE超级矢量卡
SX-Aurora TSUBAME在CPU方面采用的是英特尔Skylake-SP架构的Xeon Gold或者Xeon Sliver处理器,主角部分则是本文的核心VE超级矢量卡。
对这款产品,熟悉PC DIY的用户可能会误认为VE卡是哪一家新厂商推出的新显卡。诚然,从外观来看,采用标准PCIe接口、侧吹散热的VE超级矢量卡在外观上和一般的显卡别无二致。令人想不到的是,其火红的外观下隐藏的是完全不一样的核心。
VE超级矢量卡在计算架构上和一般的加速卡存在很大差异。根据NEC的说明,VE卡的工作模式遵循OS卸载模式。简而言之,除了偶尔的系统调用或者I/O功能外,VE卡在工作中需要将所有的执行程序和数据转移到本地存储并在处理器上运行,只有计算完成后才输出结果。在软件支持方面,VE卡可以使用标准的语言模型,比如C、C++或者Fortran,无需特殊的编程模型或者平台支持。
这种设计的优势在于大大降低了处理器和加速卡之间的传输瓶颈,尤其是PCIe带宽压力,也避免了一般加速卡出现的由于CPU和加速器数据传输延迟导致的性能下降等问题。但是,这种设计方法也存在一定的缺陷,那就是计算灵活度可能会受到限制,因此需要完善软件优化以及合适的算法搭配,这样才能更有效地利用VE卡的计算能力。
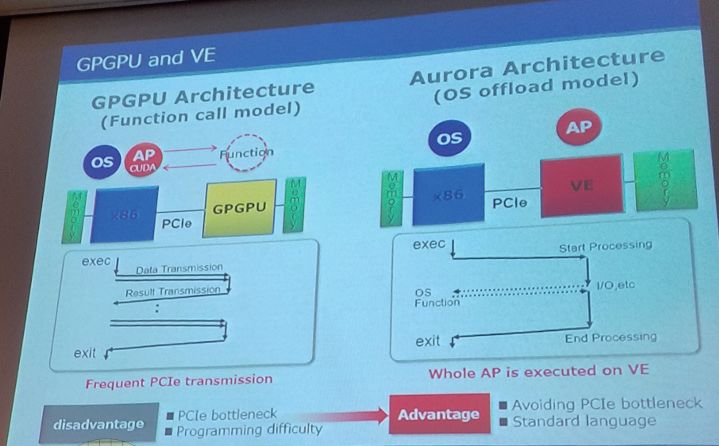
▲VE超级矢量卡的独特运行模式
另外,在物理规格上,这种设计也对VE卡的本地存储能力提出了要求,VE卡依赖于更大的本地存储(目前为48GB),毕竟本地存储空间越大,能够计算的数据量也就越大。
为了解决这些问题,NEC提出了一些新的优化思路,被称为VH Call和VEO。这两个设计的优势在于,在VH调用模型下,应用程序被存放在矢量加速卡中,并在主处理器上执行标量相关计算。而VEO则是Vector Engine Offload的简称,在这种模式下,仅有矢量化部分被载入,标量化部分则交由系统处理器完成。
在程序执行方面,VE卡使用名为ve_exec的特殊程序调用用户的适量程序,然后,ve_exec程序会自动请求在矢量计算卡上运行OS创建新的进程。接下来,ve_exec迭代可执行的ELF文件,读取每个段落并将其传递给矢量计算卡。

▲VE卡的工作模式遵循OS卸载模式
同时,系统会在x86也就是向量主机上生成伪进程,这个伪进程具有与矢量计算卡虚拟地址空间平行的虚拟地址空间。举例来说,在某个存储器操作时,首先分配的是虚拟地址页面,然后向矢量计算卡的OS请求在VE卡上的物理地址空间上分配页面,并由VE卡进行相关的虚拟地址转换和数据保护。
此外,NEC还为SX-Aurora设计了一个名为存储主机存储器(SHM)的特殊指令。在异常情况下,SHM指令用于将系统调用ID以及其参数传递给矢量OS中的伪进程,然后执行监视器调用指令,该指令将停止VE内核并在VH上调用中断程序。接下来操作系统就可以唤醒伪进程进行异常处理了,这相当于是加入了一个错误排除机制。
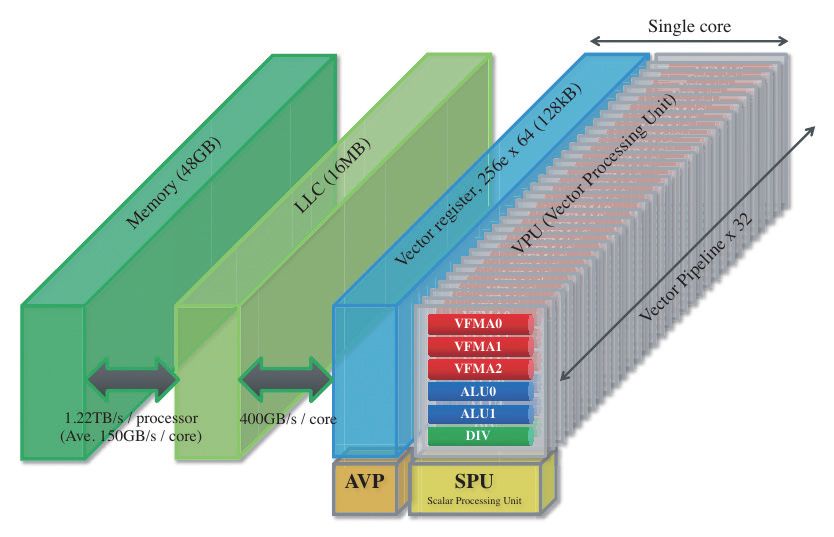
如果拆开VE超级矢量卡的话,可以看到PCB板上除了电源和一部分功能芯片外,实际上只存在一颗硕大的芯片,那就是名为SX-Aurora的矢量引擎处理器。这颗处理器拥有8颗矢量核心和相对应的6颗HBM2存储颗粒。这颗核心采用了台积电16nm工艺制造。
▲矢量处理单元架构简图
相比之下,NEC设计的前代产品也就是SX-Ace采用的是DDR3内存,通道数量高达16条—如此多的DDR3通道数量除了需要占据相当大的电路板空间外,芯片的存储控制器部分也是一笔不小的开支。最终这款产品所需要的电路面积过于庞大,只能使用传统的服务器主板搭载。
而新的SX-Aurora则采用了全新的HBM2存储颗粒,通过先进的封装设计大幅度降低了芯片和数据传输对PCB面积的需求,不但提高了存储带宽,还使得最终成品使用PCIe规格的尺寸就能够搭载,大大提高了产品的灵活性。
前文说过,一颗SX-Aurora矢量引擎处理器内包含了8颗矢量核心,相比前代产品的4颗而言数量翻倍。尽管核心数量看起来很低,但是每颗核心一个循环就可以执行192个双精度浮点运算。以芯片的频率为1.6GHz来看的话,每颗内核的计算能力高达307.2Giga Flops,总计8颗核心高达2.45 TFlos,注意,这是双精度计算能力。
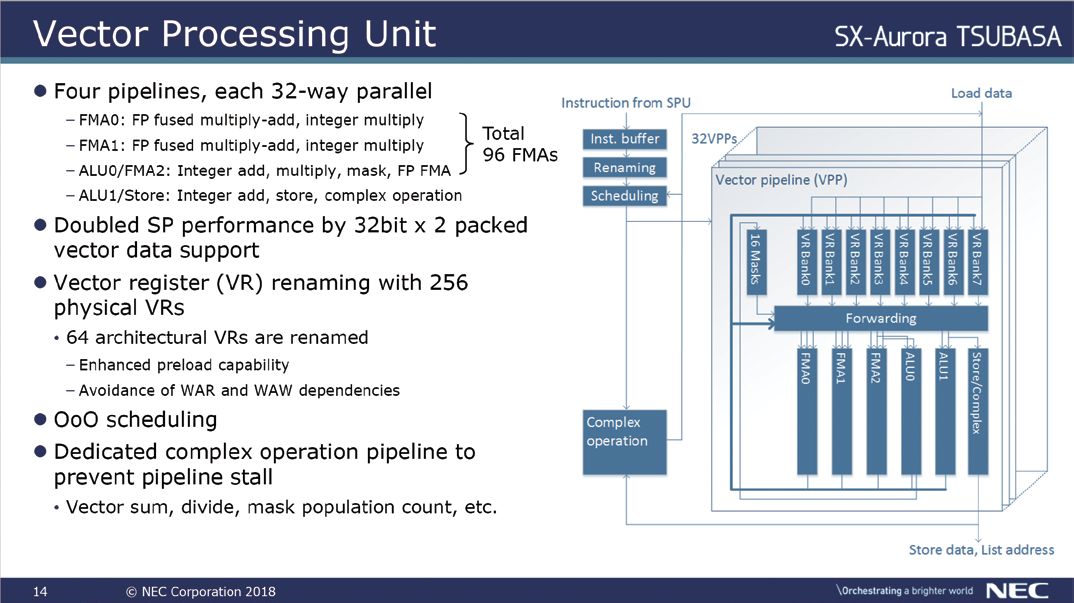
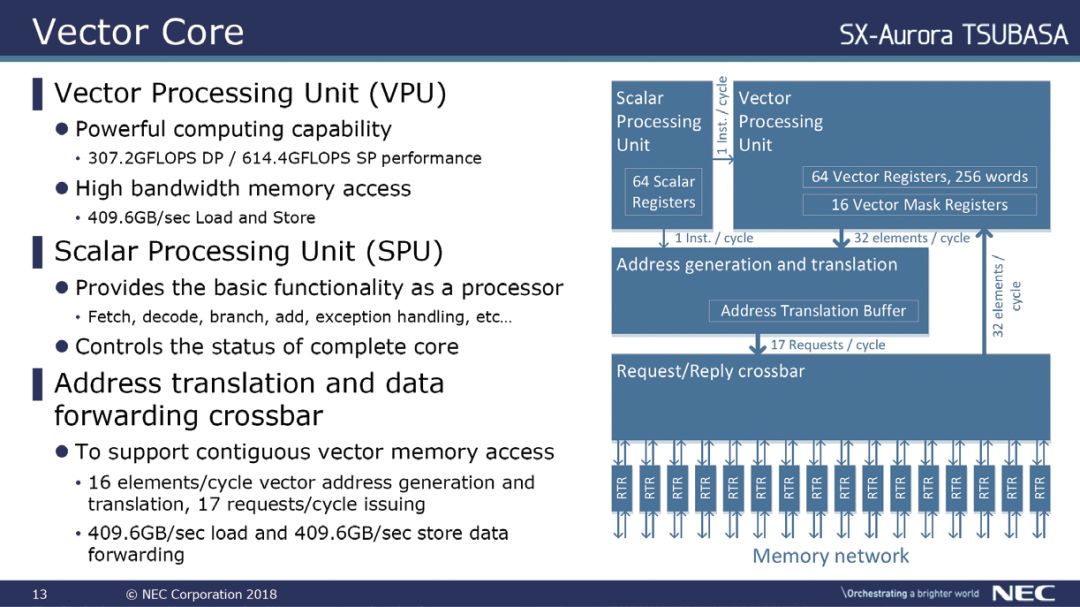
继续拆解的话,可以看到每颗核心由三个功能模块组成:标量处理单元SPU、矢量处理单元VPU和NoC接口。一般来说,即使是一款矢量处理器,标量单元依旧非常重要。这是因为应用程序需要完全在矢量处理器上运行,因此SPU相对应的必须有良好的序列化代码性能,这里需要重点提及SPU单元的设计。
NEC在SPU的设计上采用了一个四发射的乱序执行设计方案,它能够在每个周期内拾取、解码和重命名四条指令。NEC还表示,SPU具有硬件预取和复杂的分支预测器,整体深度为8阶段,具有运行一个完整操作系统所需要的所有功能。
▲矢量处理单元内部配置方案
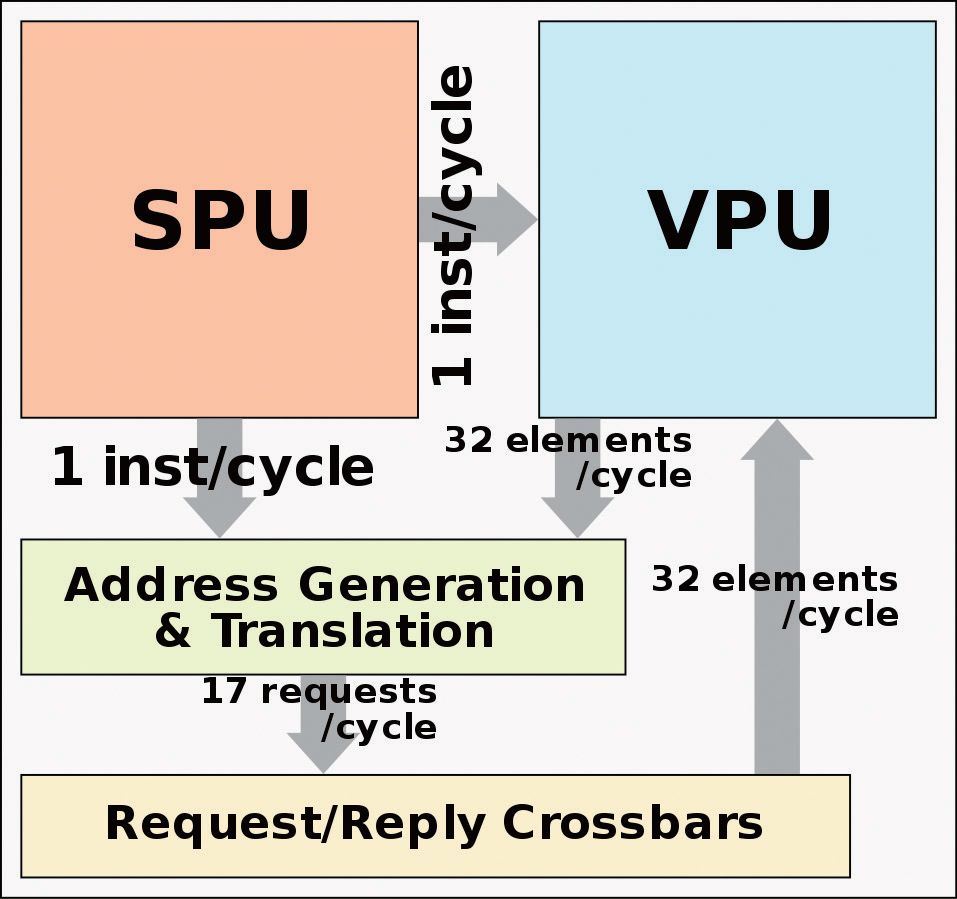
后端设计上,SPU包含一套统一的调度程序,每周期可以发送五条指令,一旦解决了指令的相关性问题,就会以乱序执行的方式发送指令给五个独立的执行单元。这五个独立执行单元包括用于通用标量算数的整数和浮点ALU、一个专用分支ALU、一个LSU和一个矢量EU。除了典型的标量操作外,SPU还需要计算矢量访问的基本内存地址。
在实际应用中,SPU可以保证VPU单元满载并且不间断地工作,还可以将每个周期的一条指令传递到VPU的缓冲区以等待执行,另外还能够向地址生成单元发送矢量指令,以便可以提前计算矢量地址。这些设计都能够大大提高效率,保证核心计算的效能。
进一步向细节深入的话,在矢量核心中最重要的部分就是矢量处理单元也就是VPU了。理想情况下,绝大部分密集型计算应该在VPU中完成。VPU的控制逻辑类似于流水线,拥有一个相当简单的管道,并且也采用了乱序执行的设计。
▲SX-Aurora矢量引擎处理器核心架构图
▲矢量核心内部结构示意
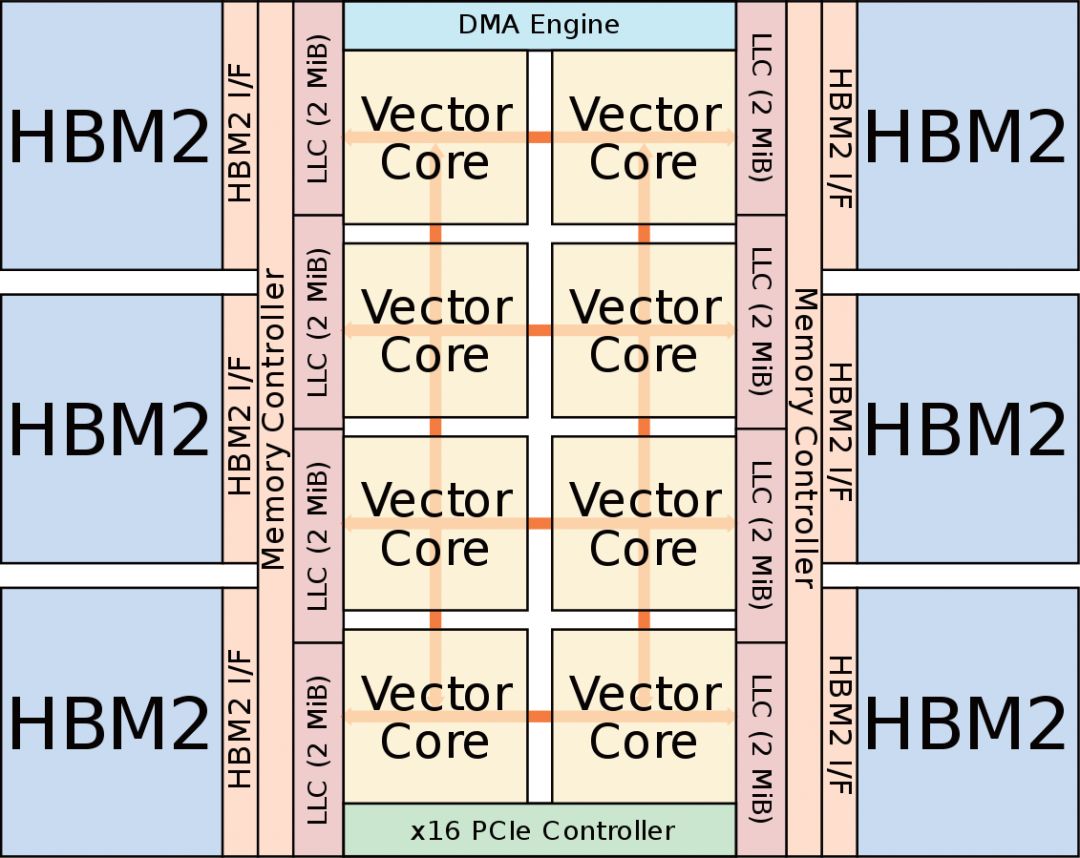
▲SX-Aurora矢量引擎处理器内部布局示意图,可见6个HMB2内存和8个矢量核心。
实际操作中,在SPU发出的指令会被放置到指令缓冲区,并在那里将其重命名、重排序和调度,等待VPU的处理。系统将64个矢量寄存器重命名为256个物理寄存器,支持增强预加载功能,并避免WAR/WAW等依赖性的存在。
调度方面,VPU的调度相对比较简单且拥有一个专门的复杂操作管道。一般来说,调度程序往往会独占一个专用端口,用于复杂操作执行单元和矢量并行管道(VPP),复杂操作执行单元一般用于处理高延迟操作,比如矢量求和、除法、掩码填充计数等操作会被发送至该单元,这可以防止由于这些操作涉及到了高延迟而导致整个流水线的停顿。
在SX-Aurora中,一个VPU中有32个VPP,相比上代产品翻倍。另外VPP部分还配备了一个8端口的矢量寄存器、16个屏蔽寄存器和6个执行管道。其中,6个执行管道包括3个浮点管道、2个整数ALU以及一条用于数据输出,设计复杂的存储管道,在这里一个ALU管道和一个存储管道共享相同的读取端口。
类似的还有FMA和另一个ALU共享一个读取端口,总而言之,每个周期执行的有效管道数量实际上是4个。和前代产品相比,现在的产品每个VPP拥有一个额外的FMA单位,可以在一定程度上加强处理器的计算能力。
性能方面,VPU部分能够实现的峰值理论性能是每周期每VPP 3个FMA操作,每个VPU包括32个VPP,因此总计是96个FMA每周期、192个DP Flops/周期。考虑到频率为1.6GHz,因此每个VPU的峰值性能是307.2Giga Flops。对单精度计算而言,每个FMA都可以对打包数据进行操作,因此可以将2个32位数据打包为一个双精度数据进行处理,这样单精度的浮点峰值性能就是双精度的一倍,为614.4Giga Flops。
从上文的数据也可以看出,整个VPU部分的吞吐能力非常强大,这样强大的计算能力对内存子系统的设计提出了极高的要求,原因也很简单,如果喂不饱VPU,那么计算效率将严重降低。
在2013年推出的SX-Ace包含了4个VPU核心,每个VPU有16个VPP,每个VPP有2个FMA。在1GHz频率下,每个核心将带来64 GigaFlops或者总计256 GigaFlops的计算能力。为了满足这颗核心的吞吐能力,四个内核连接至一个CrossBar,总带宽为256GB/s,共计16条内存通道,搭配的内存为DDR3-2133,内存带宽也恰好为256GB/s,所以每GigaFlops对应了1GB/s的带宽,这是之前的数据和带宽匹配情况。