在开始之前,给大家出几个“高频面试题”,可以先思考下:
1. 朴素实现的 KV Cache 为什么会带来显存浪费,用什么方法来解决?
2. 每个请求长度都不一样,如何让它的 KV Cache 做到按需分配?
3. Prefill 和 Decode 两个阶段,Paged Attention 适用于哪个阶段?为什么
前文
图解KV Cache:加速大模型推理的幕后功臣
里最后提到 vLLM 论文里提出的 Paged Attention 通过对 KV Cache 聪明地“按需分配空间”,类似“分隔储物柜”,来避免浪费。那么随之而来有几个问题需要解决:
1. 如何按需分配?分隔储物之后,如何快速找到当前文本序列对应的所有储物柜?
2. 分块之后,PagedAttention 里访存效率会下降吗?如何解决
因为 Paged Attention 是和分块实现的 KV Cache 搭配使用的,主要用途就是让 KV Cache 得以分块实现而尽量不影响程序执行效率,所以搞清楚 Paged KV Cache 的实现逻辑,Paged
Attention 也就搞懂了。因此本文作为 Paged Attention 的上篇,主要介绍 Paged KV Cache 的实现。其中 Page(分页)思想来自操作系统,操作系统里进程看到的都是连续的虚拟内存,但实际上背后的物理内存是分页的。
模型推理的两个阶段
前文
大语言模型推理,用动画一看就懂!
和
图解KV Cache:加速大模型推理的幕后功臣
的动图里,我们用的都是同一个例子,从中能看到模型推理可以分为两个阶段:Prefill(装填) 阶段和 Decode(解码)阶段。Prefill 是模型推理的第一步,输入是 prompt,此时需要计算整个输入文本上的 attention (self-attention)。而第二次及以后的前向迭代,输入只是单个 token,只需要计算单个 query 上的 attention,可以复用缓存里计算好的之前的 key 和 value。
KV Cache Block 的生命周期
首先来看看 vLLM 里处理请求的大致流程图,请求会被放到队列里,然后调度器负责处理这些请求,需要做的事情主要是合理安排 KV Cache 的存储资源,具体是 BlockSpaceManager 来做的。Scheduler 准备好当前想要调度的请求的资源后,LLMEngine 会再调用 Executor(Modle) 来执行一次前向的迭代。下面是 vLLM 里处理请求的大致流程图:
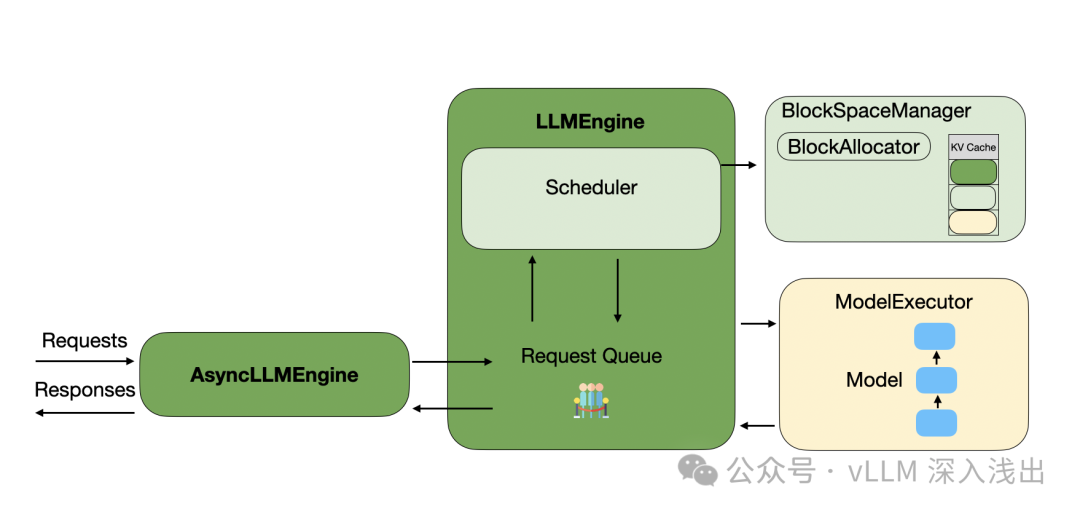
下面我们放大,进入到几个管理 KV Cache 的核心组件上,组件和相互之间的关系如下(假期看了三天才完全梳理清楚):

初始化
KV Cache 是由 Worker 里的 CacheEngine 来做的,那么怎么知道有多少显存可以拿来用于 KV Cache?vLLM 的方法比较智能:Worker 会执行一次 profile run ,这样我们能知道模型在当前最大 batch size 和最大长度情况下,推理一次所需的显存,那么剩下空余的显存都是可以给 KV Cache 用的(实际会再设置一个小的冗余,避免显存占用过多,给系统运行带来压力)。CacheEngine
逐层
申请 KV Cache Tensor,每个 Tensor形状是 [num_blocks, block_size, num_kv_heads, head_size]。KV Cache 都是按照 Block Size 来分配的,即每个 Block 里有多少个 Key/Value 的元素。vLLM 通过实验得到最优配置是 16。
分配/共享/释放
在 Prefill 阶段,因为需要计算出 prompt token len 的 Key/Value,因此需要根据它的长度来分配,而 Decode 阶段,每次只会产出一个 Token,所以如果当前块满了,就分配一个,而如果某个请求和之前的请求共享前缀(比如 systemp prompt)那么就可以
共享
这些块。而如果请求结束了,就需要释放掉占用的块。这个分配/释放过程是 BlockSpaceManager 来管理的,它负责分配新的 KV Cache,处理共享的 KV Cache Block。当然还有 CPU 内存和 GPU 显存之间的搬移(swap)或者删掉被抢占掉的 KV blocks。BlockSpaceManager 里还有一个 block_tables 字典,key 是 sequence id,value 是 BlockTable,方便快速查找到当前文本序列(Sequence) 对应的 PhysicalTokenBlock。
块的分配策略由 CachedBlockAllocator 来实现,它需要知道当前分配了多少块,会给每个分配的块一个
顺序递增的编号(block number)
。为了能够支持前面提到的复用共享前缀块,CachedBlockAllocator 里的 cached_blocks 是一个字典,key 是 block 里 token 内容来得到一个整数的哈希值,value 就是记录了 block number 的 PhysicalTokenBlock。当空闲的块分配完之后,CachedAllocator 就靠 LRU 策略来淘汰。
所有上述操作都是在 Scheduler 里做的,Scheduler 只是在安排 KV Cache 相关的分配、共享、释放等操作。这些安排的信息最终会被 LLMEngine 传递到 Worker,然后 Worker 里的 CacheEngine 会具体调用 AttentionBackend 来做 swap/copy 等操作。因为不同的实现(FlashAttention, FlashInfer)下,最优的显存布局是不同的。
vLLM 如何实现 PagedAttention?
最初 vLLM 自己用 CUDA 实现了 Paged Attention,但去年下半年 Flash Attention v2 原生
支持了 PagedAttention
。
本次我们先看看 Paged Attention 的具体函数接口:







