
目前,深度学习几乎成了计算机视觉领域的标配,也是当下人工智能领域最热门的研究方向。计算机视觉的应用场景和深度学习背后的技术原理是什么呢?下面让我们来一探究竟。
计算机视觉的应用
什么是计算机视觉呢?形象地说,计算机视觉就是给计算机装上眼睛(照相机)和大脑(算法),让计算机可以感知周围的环境。目前计算机视觉研究主要集中在基础应用场景,像图片分类、物体识别、人脸的3D建模等。
识别物体是图片分类的一个比较常见的应用,例如一个简单的猫咪识别模型,我们首先要给计算机定义模型,然后准备大量猫咪的照片去训练这个模型,让计算机能识别出来,输一张图片的时候能识别出图片是不是猫咪。正常情况下计算机模型能识别得比较准确,但是当我们输入了一些有遮挡、形态多变或者角度、光照不一的图片时,之前我们建立的模型就识别不出来。这就是计算机视觉在应用中存在的难点问题。
深度学习背后的技术原理
机器学习
在计算机视觉领域中是怎么运用深度学习来解决问题的呢?深度学习作为机器学习的一种,这里先简单介绍下机器学习。
机器学习的本质其实是为了找到一个函数,让这个函数在不同的领域会发挥不同的作用。像语音识别领域,这个函数会把一段语音识别成一段文字;图像识别的领域,这个函数会把一个图像映射到一个分类;下围棋的时候根据棋局和规则进行博弈;对话,是根据当前的对话生成下一段对话。
机器学习离不开学习两个字,根据不同的学习方式,可以分为监督学习和非监督学习两种方式。
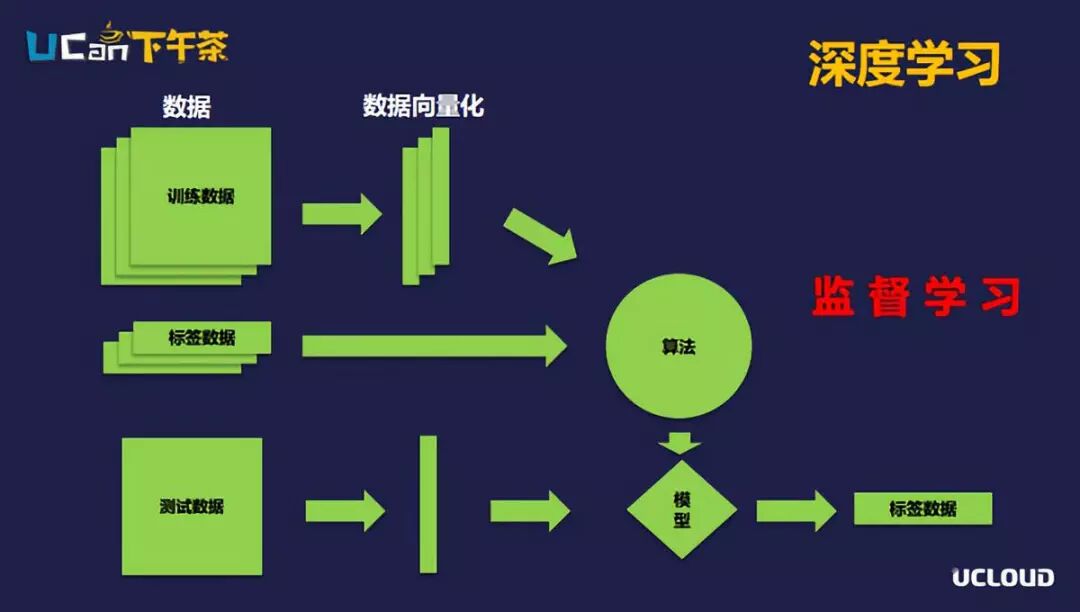
监督学习中,算法和数据是模型的核心所在。在监督学习中最关键的一点是,我们对训练的每个数据都要打上标签,然后通过把这些训练数据输入到算法模型经过反复训练以后,每经过一次训练都会减少算法模型的预计输出和标签数据的差距。通过大量的训练,算法模型基本上稳定下来以后,我们就可以把这个模型在测试数据集上验证模型的准确性。这就是整个监督学习的过程,监督学习目前在图片分类上应用得比较多。
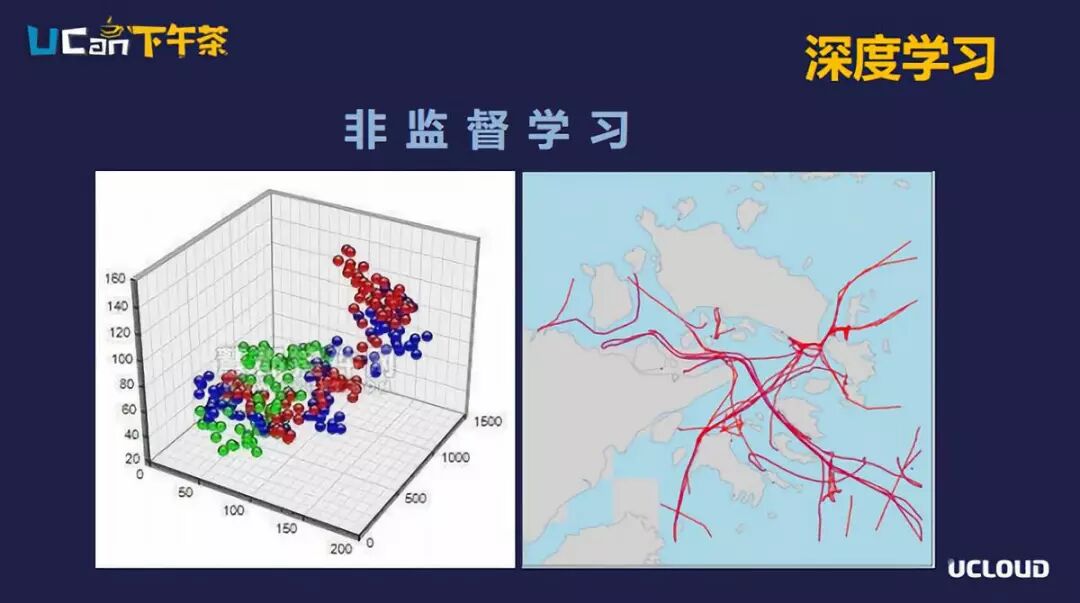
再来看非监督学习。跟监督学习不同的地方是,非监督学习不需要为所有的训练数据都打上标签。非监督学习主要应用在两个大类,第一类是做聚类分析,聚类分析是把一组看似无序的数据进行分类分组,以达到能够更加更好理解的目的;另外是做自动编码器,在数据分析的时候,原始数据量往往比较大,除了包含一些冗余的数据,还会包含一些对分析结果不重要的数据。自动编码器主要是对原始数据做降维操作,把冗余的数据去掉,提高后面数据分析的效率。
通过不同的学习方式获取到数据后,算法是接下来非常重要的一环。算法之于计算机就像大脑对于我们人类,选择一个好的算法也是特别重要的。
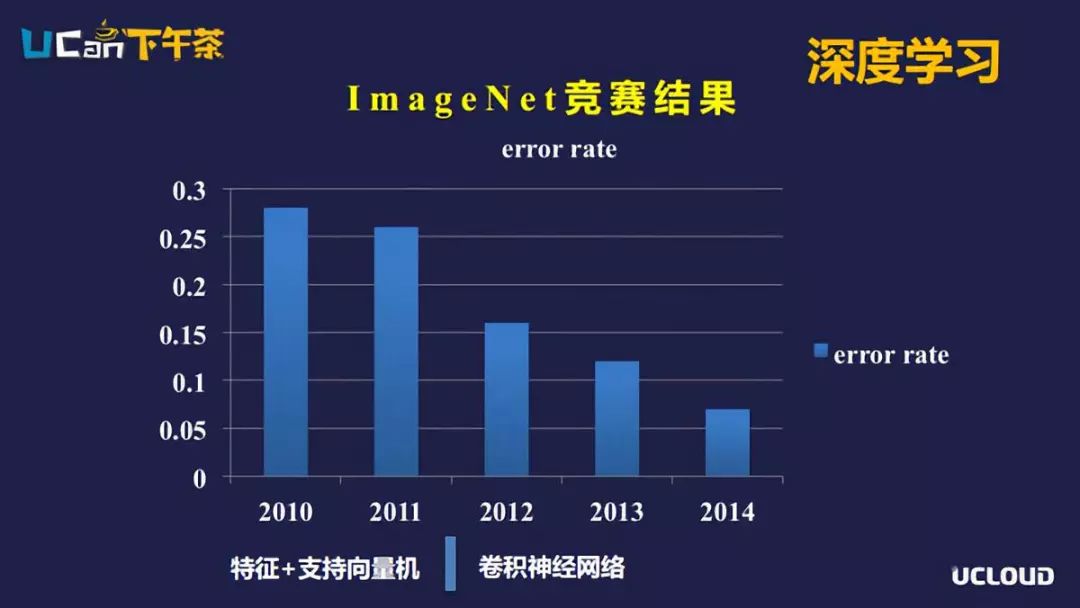
上面是ImaegNet竞赛的结果,2012年以前图片分类采用的机器学习的模型是特征+支持向量机的模型,2012年以后是卷积神经网络的模型,卷积神经网络在计算机视觉领域发挥着至关重要的作用。为什么2014年以后卷积神经网络才发挥它的作用呢?我们先来看看神经网络。
神经网络
神经网络是受人脑神经元结构的启发,研究者认为人脑所有的神经元都是分层的,可以通过不同的层次学习不一样的特征,由简单到复杂地模拟出各种特征。
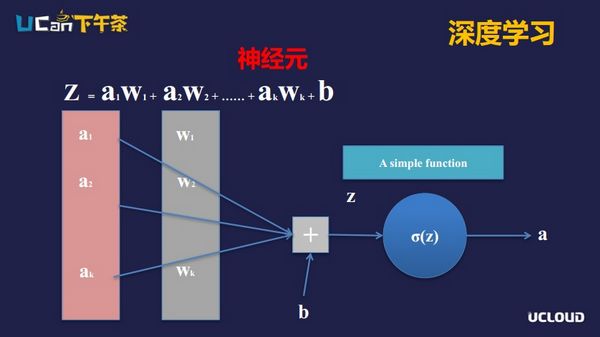
上图是计算机应用数学的方式来模拟人脑中神经元的示意图。a1到ak是信号的输入,神经元会对输入信号进行两次变换。第一部分是线性变换,因为神经元会对自己感兴趣的信号加一个权重;第二部分是非线性变换。
神经网络就是由许多的神经元级联而形成的,每一个神经元都经过线性变换和非线性变换,为什么会有非线性变换?从数学上看,没有非线性变换,不管你神经网络层次有多深都等价于一个神经元。如果没有非线性变换,神经网络深度的概念就没有什么意义了。
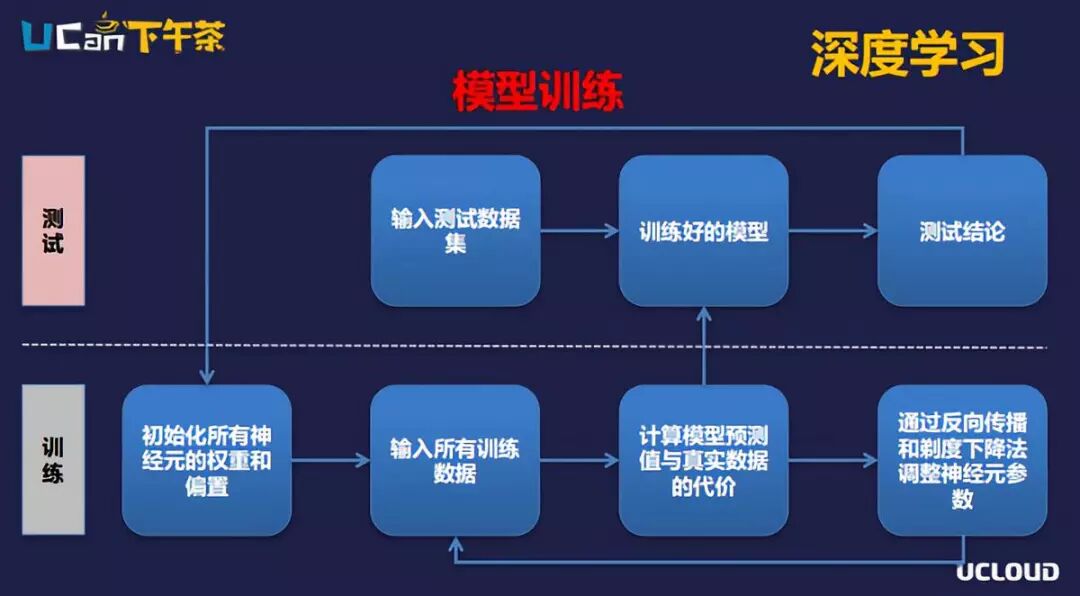
这是大家知道的神经元网络整体的模型,我们具体怎么来训练神经网络呢?
第一步,定义一个网络模型,初始化所有神经网络的权重和偏置。定义好网络模型以后再定义好这个模型的代价函数,代价函数就是我们的预测数据和标签数据的差距,这个差距越小,说明模型训练得越成功。第一次训练的时候会初始化所有神经元的参数。输入所有训练数据以后,通过当前的模型计算出所有的预测值,计算预测值以后和标签数据比较,看一下预测值和实际值有多大的差距。
第二步,不断优化差距,使差距越来越小。神经网络根据导数的原理发明了反向传播和梯度下降算法,通过N次训练后,标签数据与预测值之间的差距就会越来越小,直到趋于一个极致。这样的话,所有神经元的权重、偏置这些参数都训练完成了,我们的模型就确定下来了。接下来就可以在测试集上用测试数据来验证模型的准确率。
卷积神经网络

以上所讲的都是一般的全连接神经网络,接下来进入卷积神经网络。卷积神经网络是专门针对图片处理方面的神经网络。卷积神经网络首先会输入一张图片,这张图片是30×30,有三个颜色通道的数据,这是输入层。下面是卷积层,有一个卷积核的概念,每一个卷积核提取图片的不同特征。
提取出来以后到池化层,就是把卷积层的数据规模缩小,减少数据的复杂度。卷积和池化连起来我们叫做一个隐层,一个卷积神经网络会包含很多个隐层,隐层之后是全连接层,全连接层的目的是把前面经过多个卷积池化层的特征把数据平铺开,形成特征向量,我们把特征向量输入到分类器,对图片进行分类。
简单来说,卷积神经网络更适合计算机视觉主要有两个原因,一是参数共享,另外一个是稀疏连接。
基于深度学习的人脸识别算法模型
以上是深度学习在计算机视觉领域的相关应用以及它背后的技术原理,接下来看看基于深度学习的人脸识别算法模型。
先看一下人脸识别的应用场景,主要分三个方面:一是1:1的场景,如过安检的时身份证和人脸比对、证券开户;二是1:N的场景,比如说公安部要在大量的视频中检索犯罪嫌疑人;三是大数据分析场景,主要是表情分类,还有医学的分析等。
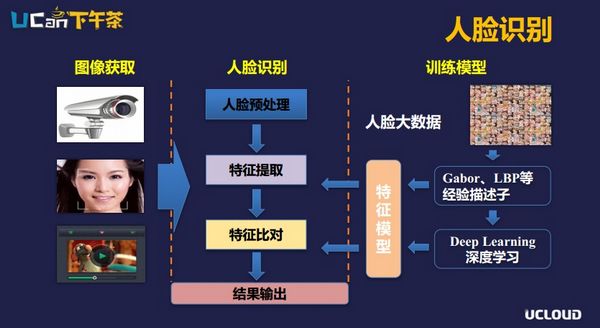
上图主要是人脸识别简单的流程,右边的是训练模型,有人脸的大数据库,经过Gabor、LBP等经验描述子,或深度学习算法提取特征模型,这个模型部署在应用上,应用通过摄像头、视频获取到人脸以后做预处理,进行特征提取,特征比对,最后输出结果,这是比较通用的人脸识别的流程。
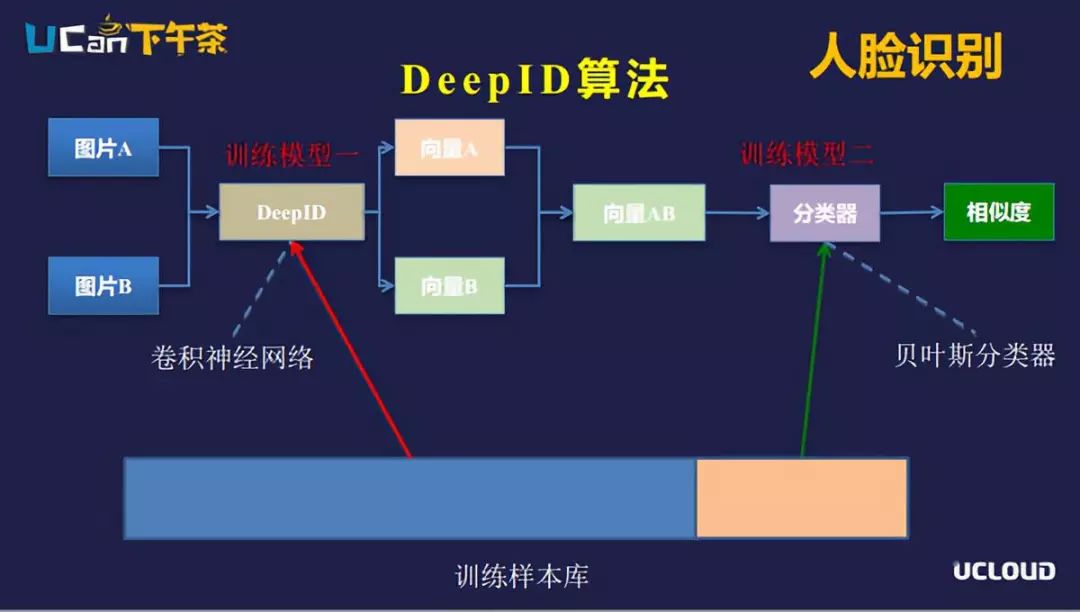
DeepID算法
DeepID算法的目的是识别两张图片,最后的输出是两张图片的相似度。输入图片A和图片B,经过DeepID卷积神经网络模型会计算出向量A和向量B,合并成向量AB。然后将向量AB输入分类器,算出向量AB的相似度,最后以这个相似度区分这两个图片是不是同一类。
这里要提到的两个模型,一是DeepID的模型,二是分类器的模型。DeepID模型是用卷积神经网络算法训练的,最后的应用是把卷积神经网络后面的softmax分类层去掉,得到softmax前面的特征向量;分类器模型是比较经典的如支持向量机/联合贝叶斯分类。训练过程中,把训练样本分成五份,四份用来训练卷积神经网络,一份用来训练分类器,可以相互印证。
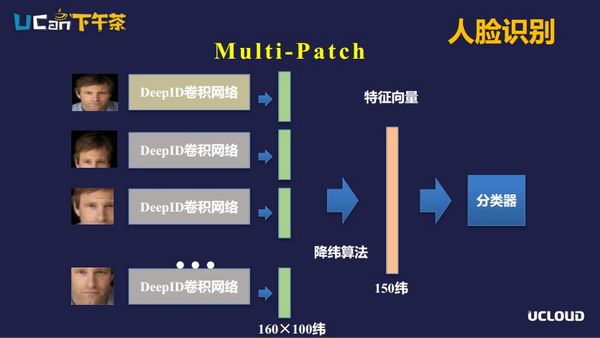
DeepID除了在网络模型上做的工作,还会对图片做预处理。像Patch的处理,按照图片以人脸的某一个部位为中心生成固定大小的图片,然后对每一个特定的Patch训练卷积神经网络。一张图片输入后,切分成多个patch,分别输入到对应的卷积神经网络。每一个卷积神经网络输出一个向量,通过降维的算法,把所有patch对应的输出向量进行处理,去除冗余信息,得到人脸的向量表示。
最后在比较两张人脸时,就是分别将两张人脸的这个向量输入分类器得到相似度结果的。这里多patch切分有一个优势,比如在现实应用中有一些人的脸部是被遮挡的,由于它是分为不同的patch,这样的场景下鲁棒性会比较好。
DeepFace算法

再来看DeepFace算法。这是人脸对齐的流程,这张图是史泰龙的侧脸图片,第一步是把人脸截取出来,对人脸上面68个基本点,描述出基本点以后,用三角剖分的算法把68个基本点连起来,然后将标准的人脸模型运用到三角剖分上,这样标准的人脸模型就具备了这样的深度。
经过仿射变形后,将侧脸模型转成正脸模型,最后把这个模型应用到具体的图片上,就得到了人的正脸图片。这个算法的主要作用是通过一些模型将人物的侧脸转成正脸,以便做进一步的人脸识别/人脸分类 。

DeepFace神经网络如图所示,前面三个卷积层比较普通,是用来提取脸部的一些基本特征;后面三个卷积层有一些改进,用的是参数不共享的卷积核,我们提到卷积核的基本特征有一个是参数是共享的,因为研究认为图片中不同的部位一些基本特征是相似的。
但在这个算法中,经过人脸对齐之后,它的不同的区域会有不同的基本特征,所以这里运用了参数不共享的卷积核。参数不共享,就不会发挥出卷积核参数少的优势,这样可能增加训练的复杂度。










