加入雷锋网,分享AI时代的信息红利,与智能未来同行。听说牛人都
点了这里
。
根据你提供的图片内容和想要的风格重新“生成”一张新的图片,是今年很多滤镜粉玩过的一个爆火游戏,但如何把这个“游戏”迁移到视频上,并实现高质量的视频风格“生成”对于很多人来说并不熟悉,因为市面上这个功能大规模推向滤镜粉的厂商还并不多,粉丝们对这个技术背后的算法也不甚了解。不过在今年Siggraph Asia 2016上的参展商演讲中,腾讯AI Lab联合清华大学实验室的团队,就为我们现场讲解了关于视频风格变换的相关内容。
演讲者,黄浩智,腾讯AI Lab。
●
●
●
演讲提纲
-
迭代图像风格转换
-
前向图像风格转换
-
迭代视频风格转换
-
前向视频风格转换
-
小结

在这之前,图片风格转换的问题,传统的方法:是基于手工提取特征来生成一张新的图片。而目前比较流行的使用深度学习的方法:是基于深度网络学习的特征来生成一张新的图片。

●
●
●
一. 关于迭代的图像风格转换
今年的CVPR有一篇 oral文章 “Image Style Transfer Using Convolutional Neural Networks”,当时引起了学术界的广泛关注,讲的就是关于迭代的图像风格变换问题。
然后我们具体去做的时候,一般是这样的:
-
先输入一张随机(噪声)图,经过VGG—19网络,可以提取出我们预先定义好的content和style特征。
-
我们将content特征跟用户提供的输入图像(content image)去比对,将style特征跟另外一张预先设定好的风格图像(譬如某位大师的一幅油画)去比对,有了内容的差异和风格的差异后。
-
我们一步步通过一个叫back propagation(反向传播)的过程,从网络的高层往回传, 一直传到我们输入的那张随机噪声图, 我们就可以去修改这张随机噪声图,使得它跟我们指定的content特征和style特征越来越像。
-
所以它最后在content 特征上接近于用户输入的那张,在style特征上接近于另一张预先设定好的油画作品等。
如下图所示,先用一个VGG—19图形识别和卷积网络提取输入图片的content和style特征。(这些提取的特征主要用于后面重构后面随机输入得到的结果)
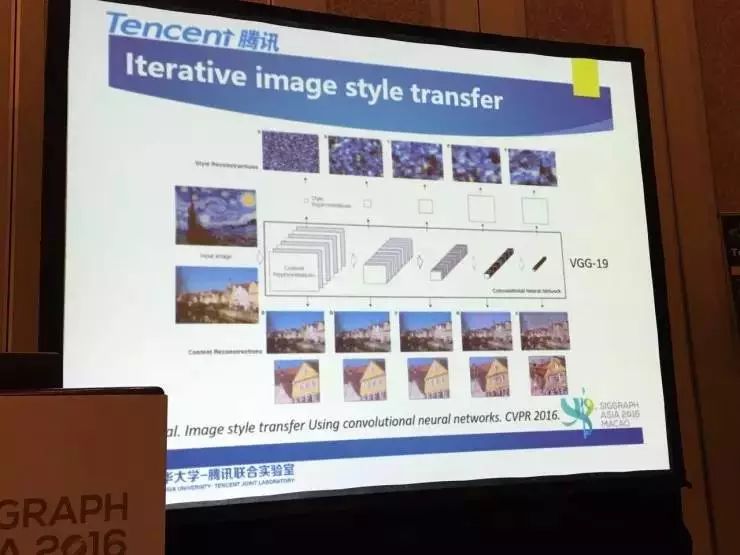
当然,实际执行图片风格转换的时候,还要考虑产生内容损失和风格损失
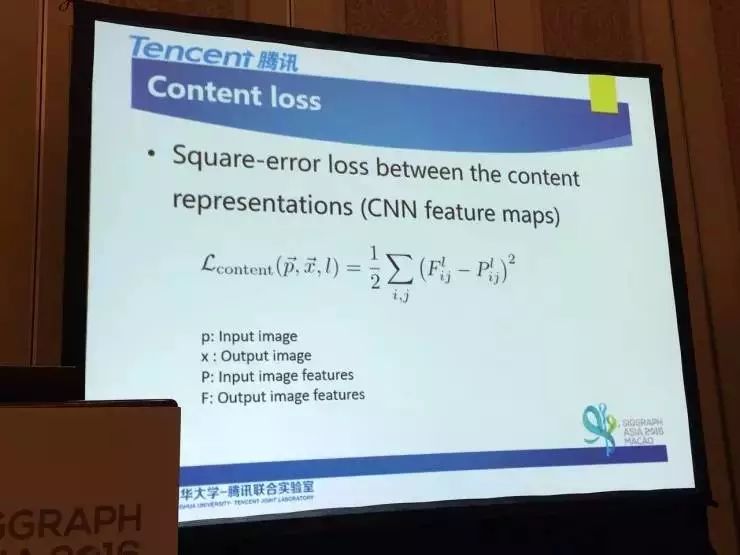
关于内容表示(CNN特征图像): 深度神经网络已经可以抽取高层次(抽象)的信息表征了。

下面是内容损失函数
关于风格表示

下面是风格损失函数

下图是流程的展示。
——一开始输入的随机噪声图,经过中间的(VGG 19)网络,在不同的层次分别提取的内容和风格特征,跟用户输入原图的内容进行比较,跟预先设定的另一张图(比如大师的某张油画图)的风格进行比较,然后计算出损失函数Ltotal。
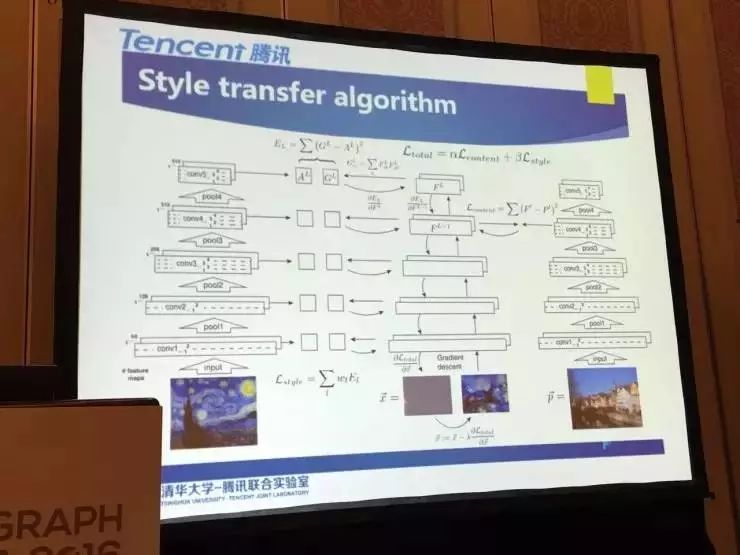
具体的风格变换算法中产生的总的损失=α*内容损失+ β*风格损失。

但迭代图像风格变换自有它的缺陷之处。
-
没有训练和自学习的过程;
-
对每一张新的输入图都要重复它迭代更新的过程;
-
速度慢。

●
●
●
二. 关于前向图片风格转换
斯坦福大学的 Justin Johnson曾经提出一种使用前向网络完成图像风格变换的方法,发表于ECCV 2016。
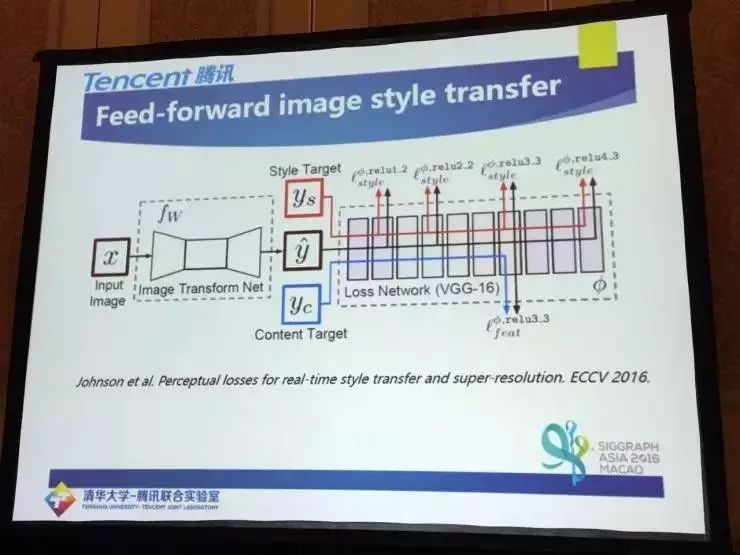
在其实践时,采用的图片转换网络层具体见下:
-
2个卷及网络层进行下采样;
-
中间5个残差网络层;
-
2个反卷积网络层进行上采样。

损失函数包下面三部分

最后的实践结果如下,质量非常不错。

总的来说,使用前向图片风格转换

●
●
●
三. 关于迭代视频风格转换
将风格变换技术由图像向视频拓展最为直接的方式就是使用图像风格变换的技术逐帧完成视频的变换,但是这样很难保证视频帧间风格的一致性。为此 Ruder 等人提出了一种迭代式的做法 [Ruder, Manuel, Alexey Dosovitskiy, and Thomas Brox. "Artistic style transfer for videos." arXiv preprint arXiv:1604.08610 (2016)],通过两帧像素之间的对应关系信息来约束视频的风格变换。
不过,迭代式(Ruder et al.)的方法来处理视频的风格变换考虑了时间域的一致性,但是处理速度非常慢,处理一帧视频大约需要 3 分钟。
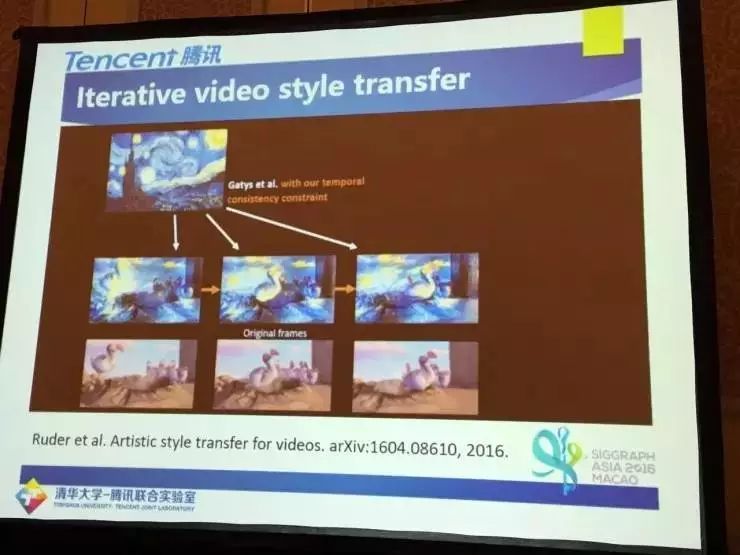

那不考虑时空一致性又是什么结果呢?以静态图片转换为例。

实验结果是这样的
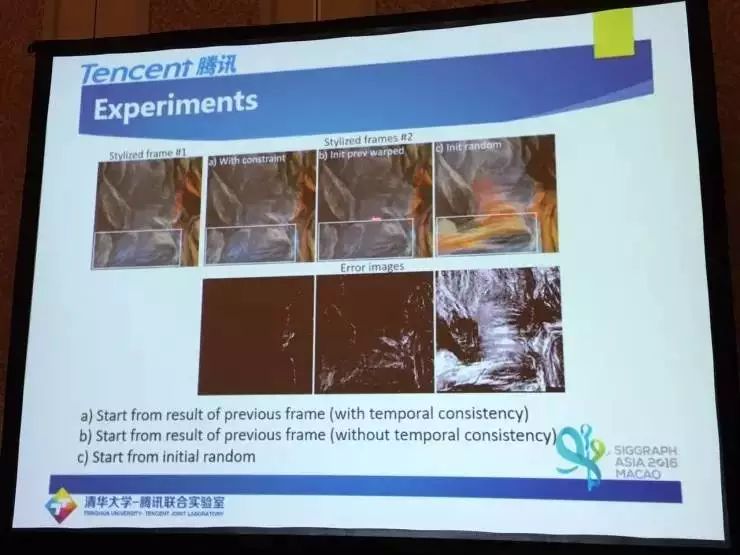
总的来说,迭代式(Ruder et. al)的方法来处理视频的风格变换

●
●
●
四. 关于前向迭代视频风格转换

腾讯AI Lab现场揭秘:实时视频风格转换是如何生成的|SIGGRAPH Asia 2016 (附PPT)
我们的方法:
-
通过大量视频数据进行训练;
-
自动辨别学习效果,并自我优化;
-
在训练过程中我们保持了输出结果的时间一致性。

最终,腾讯AI Lab
-
设计了独特的深度神经网络;
-
将风格变换的前向网络与视频时空一致性结合起来;
-
高效地完成高质量的视频风格变换。

●
●
●
五. 小结
-
深度神经网络已经可以抽取高层次(抽象)的信息表征了。
-
不同网络层的格拉姆矩阵可以用来表述风格(纹理,笔触等)。
-
从图片进阶到视频(风格的转换),要注意时空的一致性。
-
前向神经网络可以同时抓取风格和时空一致性。




