

图源:pixabay
原文来源
:arXiv
作者:
Arbaaz Khan、Clark Zhang、Daniel D. Lee、Vijay Kumar、Alejandro Ribeiro
「雷克世界」编译:嗯~是阿童木呀、KABUDA
导语:
可以这样说,大多数现有的深度多智能体强化学习方法只考虑具有少数智能体的情况。而当智能体的数量增加时,这些方法不能很好地进行扩展,从而不能很好地解决多智能问题。最近,宾夕法尼亚大学GRASP实验室的科学家们提出,通过策略梯度进行可扩展的集中式深度多智能体强化学习。经过一系列的实验结果表明,随着智能体数量的增长,本文提出的算法,在性能方面优于当前最先进的多智能体深度强化学习算法。
在本文中,我们将探索使用深度强化学习来解决多智能体问题。可以这样说,大多数现有的深度多智能体强化学习方法只考虑少数的智能体。当智能体的数量增加时,输入和控制空间的维度也会增加,而这些方法不能很好地进行扩展。为了解决这个问题,我们提出将多智能体强化学习问题视作分布式优化问题。我们的算法假设在多智能体环境设置中,给定群体中个体智能体的策略在参数空间中彼此靠近,并且可以通过单一策略进行近似。通过这个简单的假设,我们展示了我们的算法对于多智能体环境中的强化学习来说非常有效。我们在合作性和竞争性任务中,将该算法与现有的可比较方法进行比较并展示了其有效性。
充分利用强化学习(RL)中深度神经网络的强大力量已经成为设计策略的成功方法,这些策略可以对传感器输入进行映射以控制复杂任务的输出。其中,这些任务包括但不限于学习玩视频游戏、学习机器人任务的复杂控制策略、学习仅使用感官信息进行规划等。虽然这些结果令人印象深刻,但其中大多数方法仅考虑单一智能体环境设置。
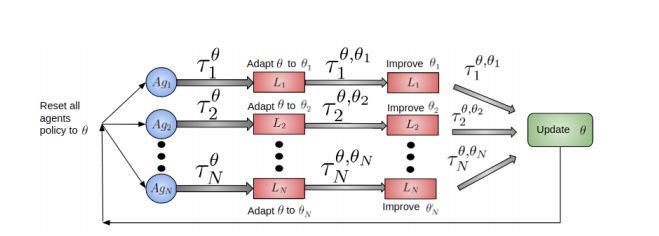
图1:分布式学习的多智能体框架
在现实世界中,许多应用程序,特别是机器人和通信领域,需要多个智能体在合作性或竞争性环境中进行彼此交互。例如具有机器人团队的仓库管理、多机器人家具设备组装、以及机器人团队的并发控制和通信等。传统上,这些问题可以通过最小化一个由机器人和环境动力学所约束的精心设置的优化问题来解决。通常情况下,当向问题添加简单的约束条件或简单地增加智能体数量时,这些问题就会变得更为棘手。在本文中,我们试图通过将多智能体问题定义为多智能体强化学习(multi-agent reinforcement learning,MARL)问题从而解决这一多智能体问题,并利用深度神经网络的强大力量。在MARL中,从智能体的角度来看,环境并不是很稳定。这是因为其他智能体也在改变他们的策略(由于学习)。诸如Q-learning这样传统的强化学习范例不适合这种不稳定的环境。
最近,有几项研究成果提出了使用分散的演员中心化评论家模型(actor-centralized critic models)。当被考虑的智能体的数量很小时,这些已被证明是行之有效的。建立大量演员网络从计算上来看并不是资源高效的。此外,评论家网络的输入空间也会随着智能体数量的增长而迅速增长。而且,在去中心化的框架中,每个智能体都必须对其他智能体进行估计和追踪。即使只有一个智能体,大多数深度强化学习算法都是样本效率低下的。正如我们将要证明的那样,试图在去中心化框架中学习多个智能体的个体策略变得非常低效。因此,试图通过使用去中心化框架,使用有限的交互来学习多策略往往是不可行的。
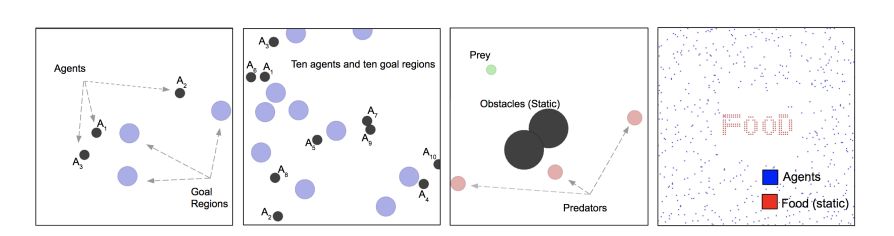
图2:用于测试的多智能体环境:我们既考虑协作环境,也考虑竞争环境。左:协作导航(带有3个智能体);中心左侧:10个智能体的协作导航;中心右侧:捕食者—猎物;右:与许多(630)智能体一起生存。
相反,我们提出使用中心化模型(centralized model)。在这里,所有的智能体都能够意识到其他智能体的行为,这减轻了非平稳性的情况。要使用MARL的中心化框架,我们必须要从单个智能体那里收集经验,然后学习将这些经验结合起来,从而为所有智能体输出行为。一种选择是使用像神经网络这样的高容量模型来学习策略,而这种策略可以将所有智能体的联合观察映射到所有智能体的联合行为中。这种简单的方法适用于智能体数量较少的情况,但在智能体的数量增加时则会受到维度的限制。另一种可能性是为一个智能体学习策略,并在所有智能体中对其进行微调,但这也被证明是不切实际的。为了缓解规模和有限交互的问题,我们提出使用用于MARL问题的分布式优化框架。其关键思想是,当多个智能体进行交互时,为所有展现紧急行为的智能体学习一种策略。这种类型的策略已被证明在自然界以及群体机器人中都有所使用。在本文中,目标是通过强化学习从原始观察和奖励中学习这些策略。
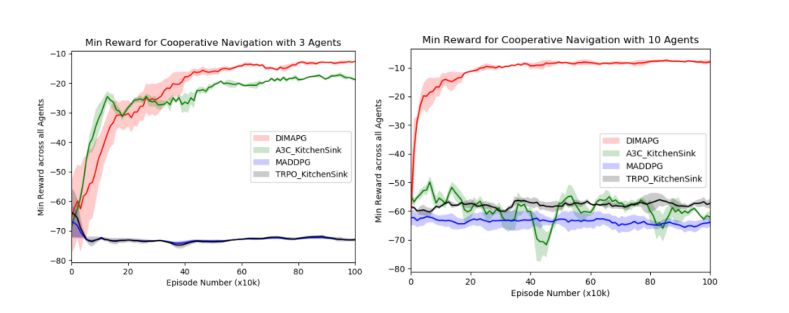
图3:协作导航中的最小奖励VS事件的数量
对一个跨所有智能体的策略进行优化是很困难的,并且有时候还难以控制(特别是当智能体的数量很大时)。相反,我们采用分布式方法,其中每个智能体通过其局部观察来改进中心策略。然后,中心控制器将这些改进结合起来,从而改进整体策略。这可以被看作是对一个原始问题的重塑,由对一个策略进行优化重塑为对若干个策略进行优化,而这若干个策略受限于它们是相同的。训练结束后,所有智能体只能使用一个策略。这是一种优化技术,之前已经在分布式环境设置中取得了成功。因此,本文的主要贡献是:
1.提出一种使用分布式优化解决MARL问题的新算法。
2.在使用分布式优化解决MARL问题时,提出策略梯度公式。
相关研究
多智能体强化学习(MARL)一直是强化学习领域中,备受积极探索的分支。许多初始方法都基于表格法(tabular methods)来计算Markov博弈总体的Q值。过去的另一种方法是将每个事件(
episode



