李林 编译自 pyimagesearch
作者 Adrian Rosebrock
量子位 报道 | 公众号 QbitAI
OpenCV是一个2000年发布的开源计算机视觉库,有进行物体识别、图像分割、人脸识别、动作识别等多种功能,可以在Linux、Windows、Android、Mac OS等操作系统上运行,以轻量级、高效著称,且提供多种语言接口。
而OpenCV最近一次版本更新,为我们带来了更好的深度学习支持,在OpenCV中使用预训练的深度学习模型变得非常容易。
pyimagesearch网站今天发布了一份用OpenCV+深度学习预训练模型做图像识别的教程,量子位编译整理如下:
最近,OpenCV 3.3刚刚正式发布,对深度学习(dnn模块)提供了更好的支持,dnn模块目前支持Caffe、TensorFlow、Torch、PyTorch等深度学习框架。
另外,新版本中使用预训练深度学习模型的API同时兼容C++和Python,让系列操作变得非常简便:
从硬盘加载模型;
对输入图像进行预处理;
将图像输入网络,获取输出的分类。
当然,我们不能、也不该用OpenCV训练深度学习模型,但这个新版本让我们能把用深度学习框架训练好了的模型拿来,高效地用在OpenCV之中。
这篇文章就展示了如何用ImageNet上预训练的深度学习模型来识别图像。
OpenCV 3.3中的深度学习
自OpenCV 3.1版以来,dnn模块一直是opencv_contrib库的一部分,在3.3版中,它被提到了主仓库中。
用OpenCV 3.3,可以很好地利用深度学习预训练模型,将它们作为分类器。
新版OpenCV兼容以下热门网络架构:
该模块的主要贡献者Rynikov Alexander,对这个模块有远大的计划,不过,他写的release notes是俄语的,感兴趣的同学请自行谷歌翻译着读:https://habrahabr.ru/company/intel/blog/333612/
我认为,dnn模块会对OpenCV社区产生很大的影响。
函数和框架
在OpenCV中使用深度学习预训练模型,首先要安装OpenCV 3.3,安装过程量子位就不再详细描述了……
下面是我们将用到的一些函数。
在dnn中从磁盘加载图片:
cv2.dnn.blobFromImage
cv2.dnn.blobFromImages
用“create”方法直接从各种框架中导出模型:
cv2.dnn.createCaffeImporter
cv2.dnn.createTensorFlowImporter
cv2.dnn.createTorchImporter
使用“读取”方法从磁盘直接加载序列化模型:
从磁盘加载完模型之后,可以用.forward方法来向前传播我们的图像,获取分类结果。
用OpenCV和深度学习给图像分类
接下来,我们来学习如何用Python、OpenCV和一个预训练过的Caffe模型来进行图像识别。
下文用到的深度学习模型是在ImageNet上预训练过的GoogleLeNet。GoogleLeNet出自Szegedy等人2014年的论文Going Deeper with Convolutions,详情见:https://arxiv.org/abs/1409.4842
首先,打开一个新文件,将其命名为deep_learning_with_opencv.py,插入如下代码,来导入我们需要的包:

然后拆解命令行参数:
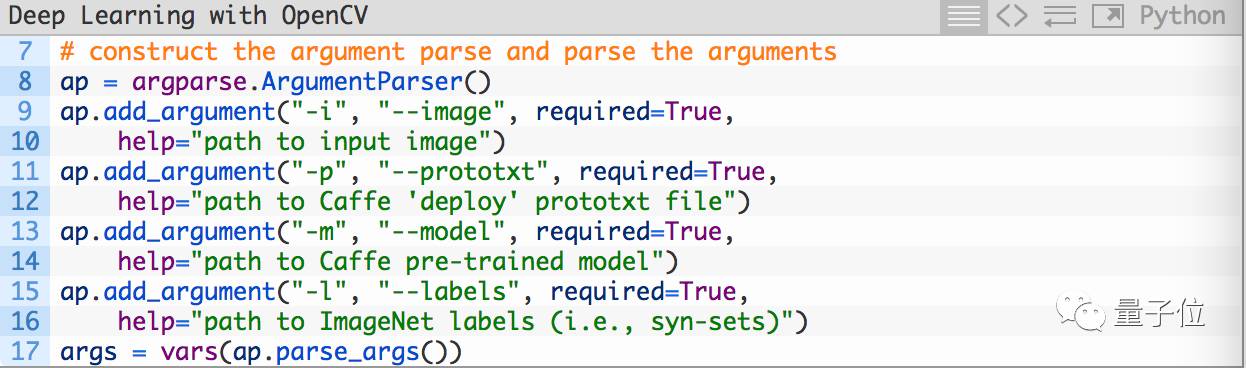
其中第8行ap = argparse.ArgumentParser()是用来创建参数解析器的,接下来的代码用来创建4个命令行参数:
—image:输入图像的路径;
—prototxt:Caffe部署prototxt的路径
—model:预训练的Caffe模型,例如网络权重等;
—labels:ImageNet标签的路径,例如syn-sets。
我们在创建参数之后,将它们解析并存在一个变量args中,供稍后使用。
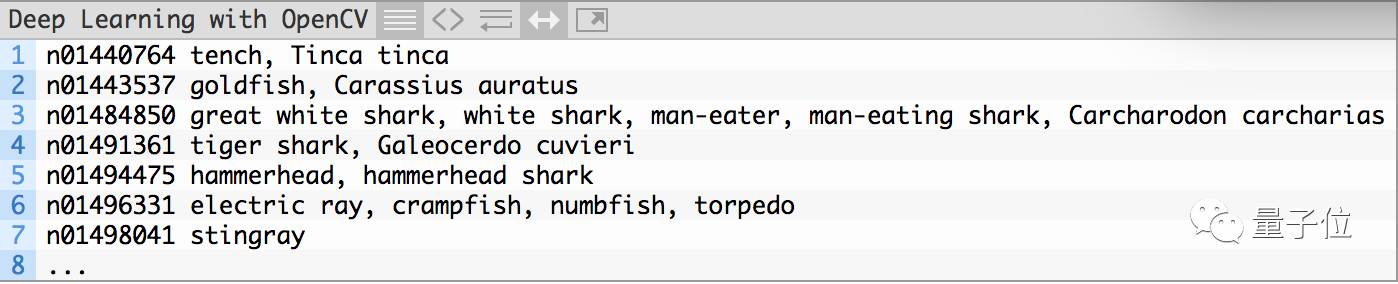
接下来,加载输入图像和标签:

第20行从磁盘加载了图像,第23行和24行加载了这些标签:
搞定了标签之后,我们来看一下dnn模块:

注意上面代码中的注释,我们使用cv2.dnn.blobFromImage执行mean subtraction来对输入图像进行归一化,从而产生一个已知的blob形状。
然后从磁盘加载我们的模型:

我们用cv2.dnn.readNetFromCaffe来加载Caffe模型定义prototxt,以及预训练模型。
接下来,我们以blob为输入,在神经网络中完成一次正向传播:
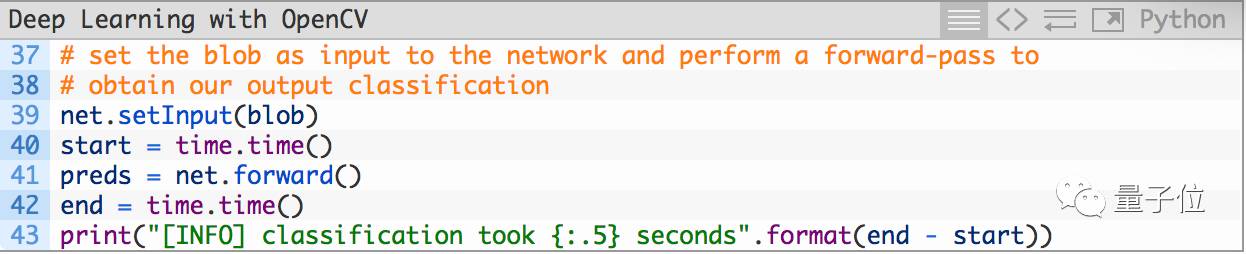
请注意:我们不是在训练CNN,而是在使用预训练模型,因此只需要将blob从网络中传递过去,来获取结果,不需要反向传播。
最后,我们来为输入图像取出5个排名最高的预测结果:

我们可以用NumPy来选取排名前5的结果,然后将他们显示出来:
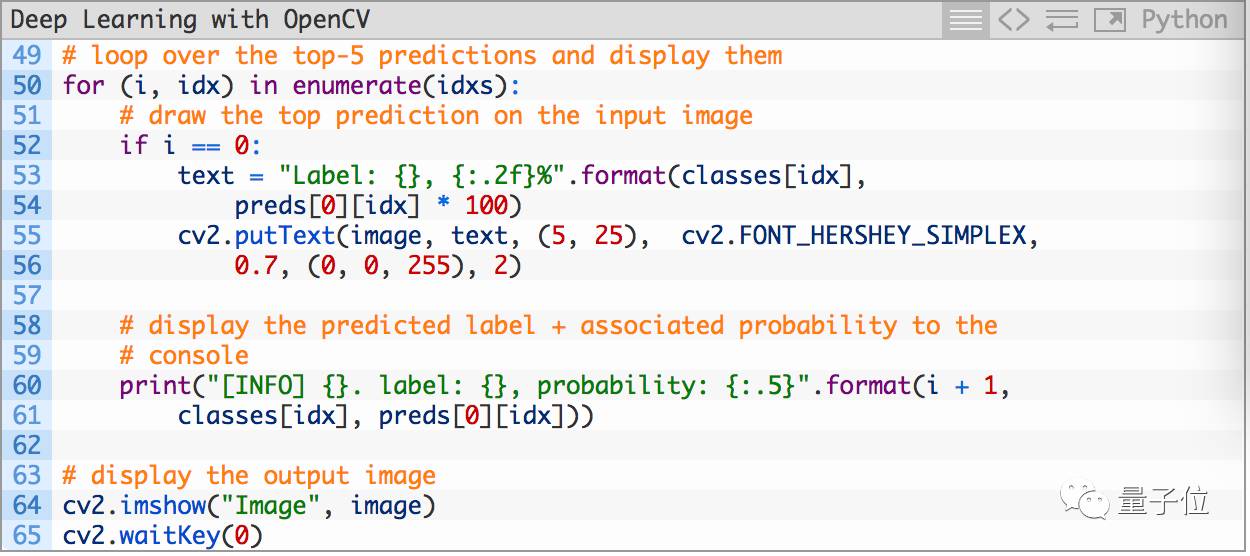
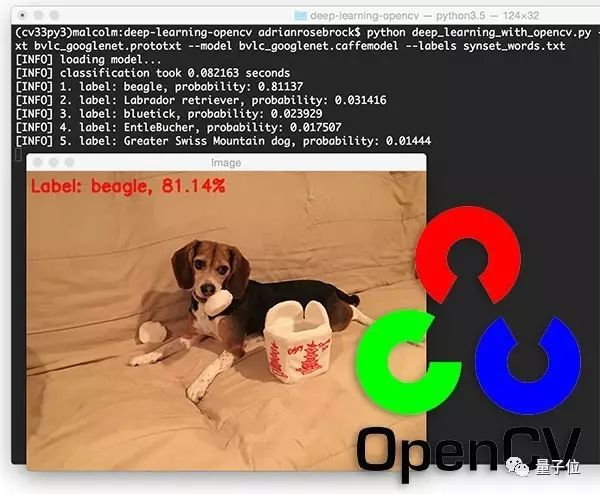
分类结果
我们已经在OpenCV中用Python代码实现了深度学习图像识别,现在,可以拿一些图片来试一试。
打开你的终端,执行以下命令:
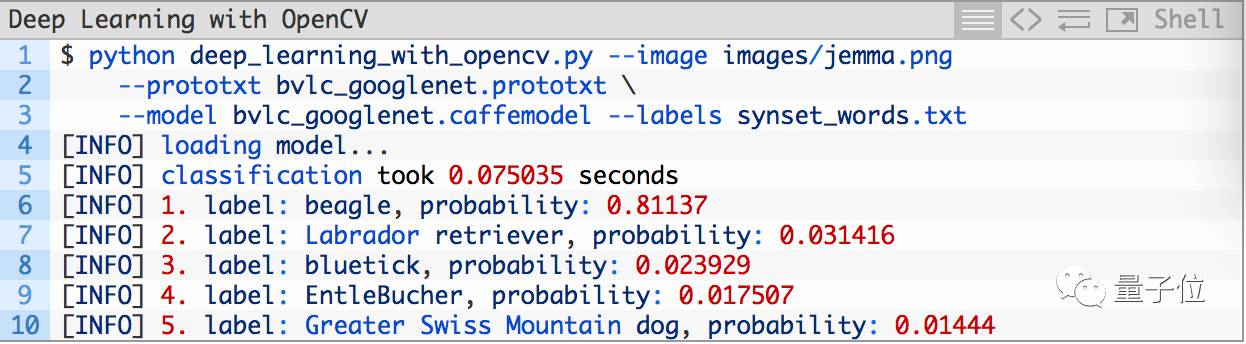
就会得到这样的结果:
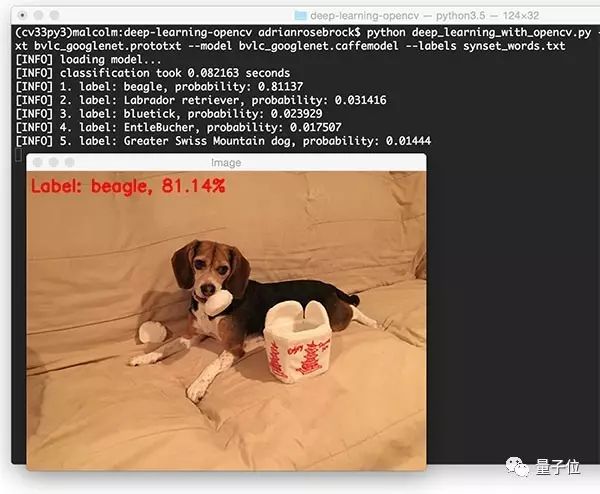
OpenCV和GoogleLeNet正确地认出了比格小猎犬,排名第一的结果是正确的,之后的4项结果相关度也很高。
在CPU上运行这个算法,得到结果也只需要不到一秒钟。
再来一张:
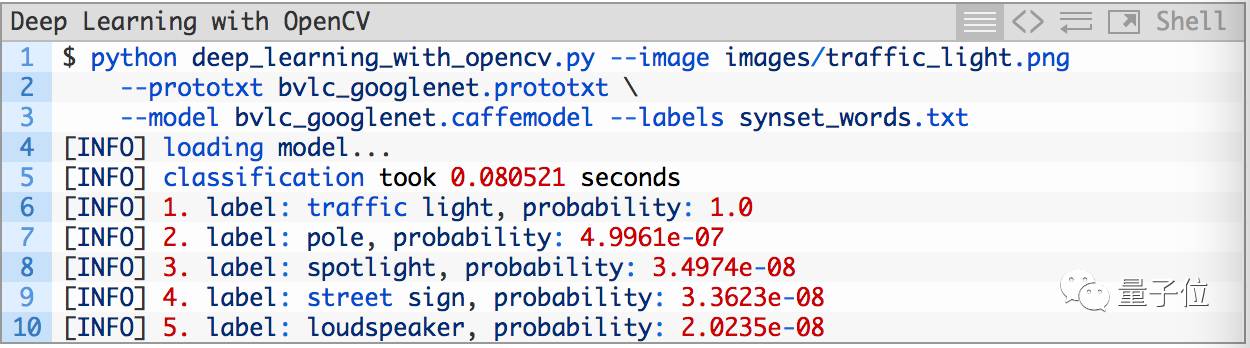
结果如下:
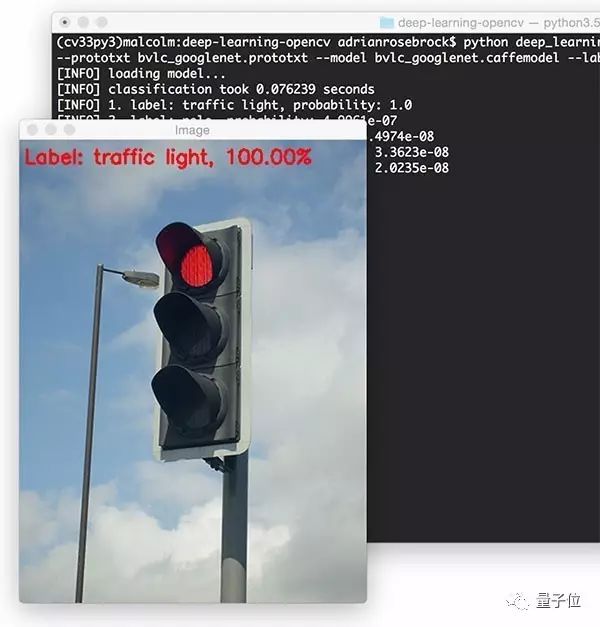
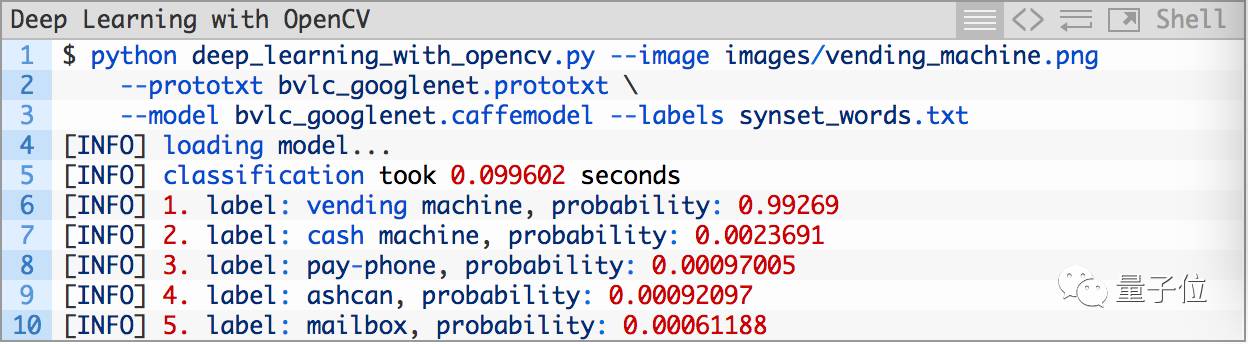
再来:
结果依然不错:
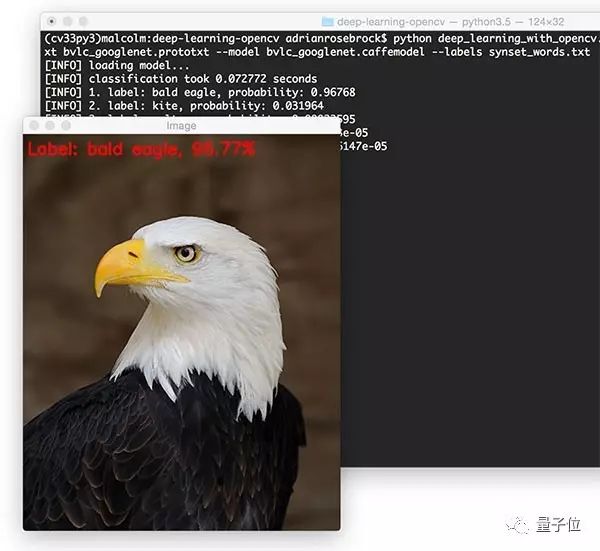
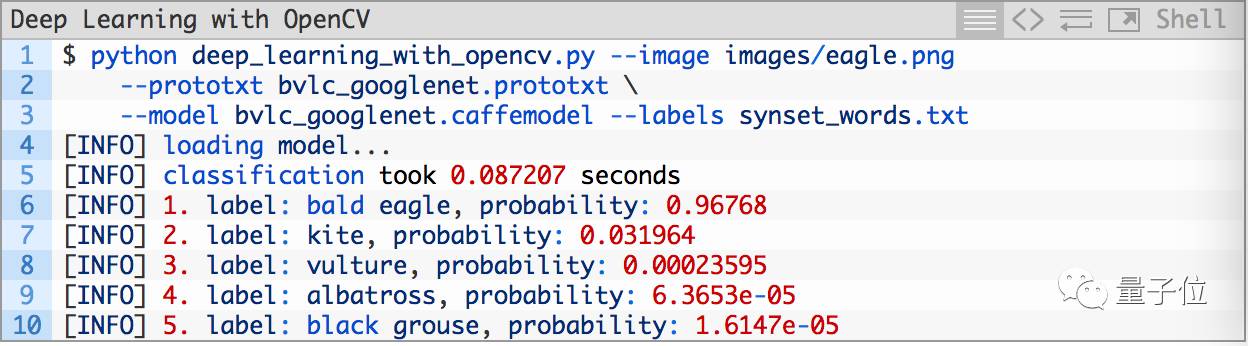
最后一个例子:
也认得不错:

相关链接
教程原文:
http://www.pyimagesearch.com/2017/08/21/deep-learning-with-opencv/
相关代码:
在原文下填邮箱获取,或在量子位公众号(QbitAI)对话界面回复“OpenCV”获取。
量子位AI社群7群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot2入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot2,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。









