在前一个小节中,简单地谈了谈什么是“M-P神经元模型”,顺便用生活中生动的小案例,把激活函数和卷积函数的概念撸了一遍。下笔之处,尽显“神经”。当然这里所谓的“神经”,是说我们把不同领域的知识,以天马行空地方式,揉和在一起,协同提升认知水平。其实,这不也正是深度学习的前沿方向之一——“迁移学习(Multi-Task and Transfer Learning)”要干的事情吗?
下面,继续“神经”下去,首先聊聊机器学习的三大分支,然后以“中庸之道”来看机器学习的发展方向。
4.1机器学习的三个层次
在我们小时候,大概都学习过《三字经》,其中有句“性相近,习相远。”说的就是,“人们生下来的时候,性情都差不多,但由于后天的学习环境不一样,性情也就有了千差万别。”
其实,这句话用在机器学习领域,上面的论述也是大致适用的。机器学习的学习对象是数据,数据是否有标签,就是机器学习所处的“环境”,“环境”不一样,其表现出来的“性情”也有所不同,大致可分为三类:
(1)监督学习(Supervised Learning):用数据挖掘大家韩家炜(Jiawei Han)老师的观点来说,监督学习基本上就是“分类(
classification)”的代名词
。它从有标签的训练数据中学习,然后给定某个新数据,预测它的标签(given data, predict labels)。这里的标签(label),其实就是某个事物的分类。
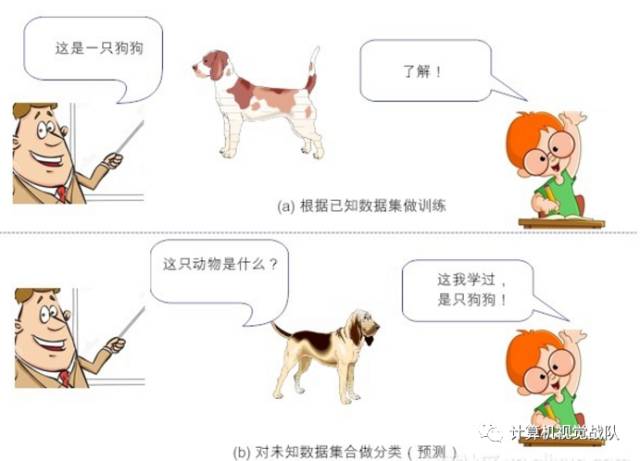
图4-1 监督学习
比如说,小时候父母告诉我们某个动物是猫、是狗或是猪,然后我们的大脑里就会形成或猫或狗或猪的印象,然后面前来了一条“新”小狗,如果你能叫出来“这是一条小狗”,那么恭喜你,你的标签分类成功!但如果你说“这是一头小猪”。这时你的监护人就会纠正你的偏差,“乖,不对呦,这是一头小狗”,这样一来二去的训练,就不断更新你的大脑认知体系,聪明如你,下次再遇到这类新的“猫、狗、猪”等,你就会天才般的给出正确“预测”分类(如图1所示)。简单来说,监督学习的工作,就是通过有标签的数据训练,获得一个模型,然后通过构建的模型,给新数据添加上特定的标签。
事实上,整个机器学习的目标,都是使学习得到的模型,能很好地适用于“新样本”,而不是仅仅在训练样本上工作得很好。通过训练得到的模型,适用于新样本的能力,称之为“泛化(generalization)能力”。
(2)非监督学习(Unsupervised Learning):与监督学习相反的是,非监督学习所处的学习环境,都是非标签的数据。韩老师接着说,非监督学习,本质上,就是“聚类(
cluster)”的近义词
。
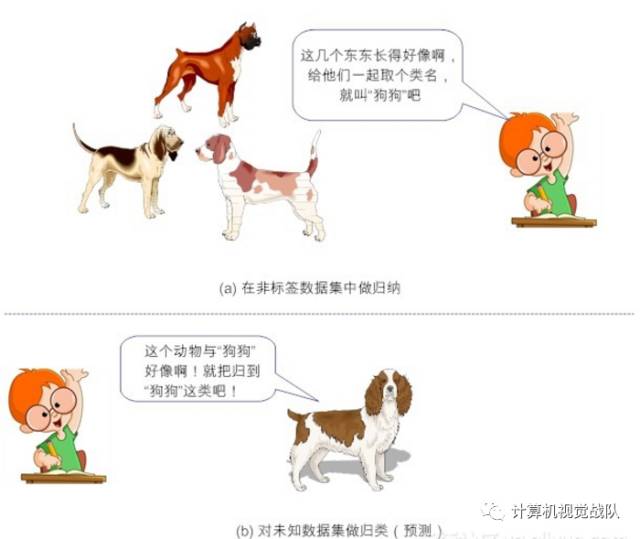
图4-2 非监督学习
简单来说,给定数据,从数据中学,能学到什么,就看数据本身具备什么特性了(given data, learn about that data)。我们常说的“物以类聚,人以群分”说得就是“非监督学习”。这里的“类”也好,“群”也罢,事先我们是不知道的。一旦我们归纳出“类”或“群”的特征,如果再要来一个新数据,我们就根据它距离哪个“类”或“群”较近,就“预测”它属于哪个“类”或“群”,从而完成新数据的“分类”或“分群”功能。
(3)半监督学习(Semi-supervised Learning):这类学习方式,既用到了标签数据,又用到了非标签数据。有句骂人的话,说某个人“有妈生,没妈教”,抛开这句话骂人的含义,其实它说的是“无监督学习”。但我们绝大多数人,不仅“有妈生,有妈教”,还“有小学教,有中学教,有大学教”,“有人教”,这就是说,有人告诉我们事物的对与错(即对事物打了标签),然后我们可据此改善自己的性情,慢慢把自己调教得更有“教养”,这自然就属于“监督学习”。但总有那么一天我们要长大。而长大的标志之一,就是自立。何谓“自立”?就是远离父母、走出校园后,没有人告诉你对与错,一切都要基于自己早期已获取的知识为基础,从社会中学习,扩大并更新自己的认知体系,然后遇到新事物时,我们能“泰然自若”处理,而非茫然“六神无主”。
从这个角度来看,现代人类成长学习的最佳方式,当属“半监督学习”!它既不是纯粹的“监督学习”(因为如果完全是这样,就会扼杀我们的创造力,我们的认知体系也就永远不可能超越我们的父辈和师辈)。但我们也不属于完全的“非监督学习”(因为如果完全这样,我们会如“无根之浮萍”,会花很多时间“重造轮子”。前人的思考,我们的阶梯,这话没毛病!)。
那么到底什么是“半监督学习”呢?下面我们给出它的形式化定义:
给定一个来自某未知分布的有标记示例集
L={(
x
1
,
y
1
), (
x
2
,
y
2
), ..., (
x
l
,
y
l
)}
,其中
x
i
是数据,
y
i
是标签。对于一个未标记示例集
U =
{
x
l+1
, x
l+1
, ... , x
l+u
}
,
l
<<
u
,于是,我们期望学得函数
f:X→Y
可以准确地对未标识的数据
x
i
预测其标记
y
i
。这里均为d维向量,
y
i
∈
Y
为示例
x
i
的标记。
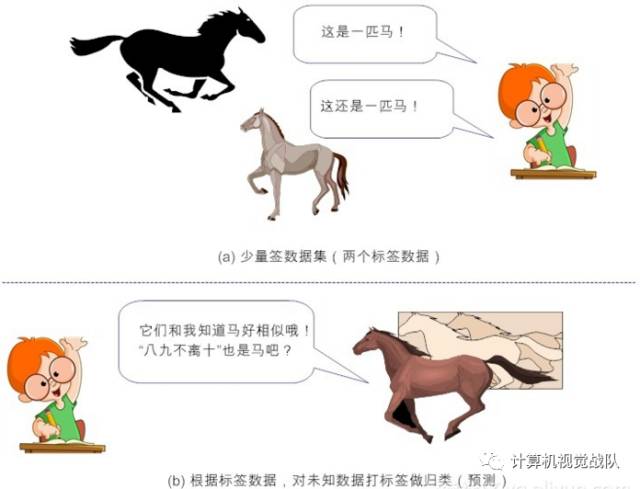
图4-3 半监督学习
形式化的定义比较抽象,下面我们列举一个现实生活中的例子,来辅助说明这个概念。假设我们已经学习到:
(1)
马晓云同学(数据1)是个牛逼的人(标签:牛逼的人)
(2) 马晓腾同学(数据2)是个牛逼的人(标签:牛逼的人)
(3) 假设我们并不知道李晓宏同学(数据3)是谁,也不知道他牛逼不牛逼,但考虑他经常和二马同学共同出没于高规格大会,都经常会被达官贵人接见(也就是说他们虽独立,但同分布),我们很容易根据“物以类聚,人以群分”的思想,把李晓宏同学打上标签:他也是一个很牛逼的人!
这样一来,我们的已知领域(标签数据)就扩大了(由两个扩大到三个!),这也就完成了半监督学习。事实上,半监督学习就是以“已知之认知(标签化的分类信息)”,扩大“未知之领域(通过聚类思想将未知事物归类为已知事物)”。但这里隐含了一个基本假设——“聚类假设(cluster assumption)”,其核心要义就是:“相似的样本,拥有相似的输出”。
事实上,我们对半监督学习的现实需求,是非常强烈的。其原因很简单,就是因为人们能收集到的标签数据非常有限,而手工标记数据需要耗费大量的人力物力成本,但非标签数据却大量存在且触手可及,这个现象在互联网数据中更为凸显,因此,“半监督学习”就显得尤为重要性。
人类的知识,其实都是这样,以“半监督”的滚雪球的模式,越扩越大。“半监督学习”既用到了“监督学习”,也吸纳了“非监督学习”的优点,二者兼顾。
如此一来,“半监督学习”就有点类似于我们中华文化的“中庸之道”了。
的确如此吗?下面我们就聊聊机器学习的“中庸之道”。
4.2从“中庸之道”看机器学习
说到“中庸之道”,很多人立马想到的就是“平庸之道”,把它的含义理解为“不偏不倚、不上不下、不左不右、不前不后”。其实,这是一个很大的误解!
据吴伯凡先生介绍[3],“中”最早其实是一个器具,它看上去像一个槌子,为了拿起方便,就用手柄穿越其中,即为“中”。
这个“中”可不得了,它非常重要,且只有少数人才能使用。那都是谁来用呢?答案就是古代的军事指挥官。在“铁马金戈风沙腾”的战场上,军旗飘飘,唯有一人高高站在战车上,手握其“中”,其他将士都视其“中”而进退有方(见图4-4第二行第一字),而手握其“中”的人,称之为“史”(见图4-4第一行第一字)。所以现在你知道了吧,其实“史”最早的本意,就是手握指挥大权的“大官”。
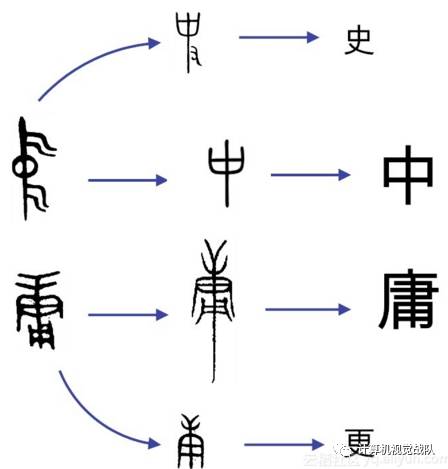
图4-4 中庸之道,蕴意为何?
再后来,“中”就有各种各样的引申含义。在中原地带的人,在他们的语言里头到现在还保留一些古代遗风,比如说河南人说“对”或者“是”的时候,他说的是“中(zhóng)”,当他们说“中(zhóng)”的时候,就表示事情是正确的,是可行的。
其实,“中”还有一个读音叫“中(zhòng)”,比如说成语里就有“正中下怀”、“百发百中”等,这时“中(zhòng)”的含义就是恰到好处,不偏离原则,坚守关键点。









