作者: 一只爱折腾的后端攻城狮
知乎专栏|后端攻城狮:
https://zhuanlan.zhihu.com/c_1011199533304410112
个人公众号:zone7
概述
前言
思考
统计结果
爬虫技术分析
爬虫代码实现
爬虫分析实现
后记
前言
举国欢庆的国庆节马上就要到来了,你想好去哪里看人山人海了吗?还是窝在家里充电学习呢?说起国庆,塞车与爆满这两个词必不可少,去年国庆我在想要是我能提前知道哪些景点爆满就好了,就不用去凑热闹了。于是我开始折腾,想用 python 抓取有关出行方面的数据,便有了这篇文章。如果我的文章对你有帮助,欢迎关注、点赞、转发,这样我会更有动力做原创分享。
 弘扬一下社会主义核心价值观
弘扬一下社会主义核心价值观思考
(此段可跳过)要抓取出行方面的数据还不简单,直接去看看携程旅游、马蜂窝这类网站看看有没有数据抓取。但是实际上这些网站并没有比较好的格式化的数据供我们抓取,或许是我没找到吧。我在想,有没有什么折中的办法。然而,就这样半天过去了,突然想到,要出行肯定会查找相关的出行攻略吧,那么关键词就是一个突破口,可以查询百度指数来看看哪些景点被查询的次数最多,那么就可以大概知道哪些景点会爆满了。
统计结果
此次的统计结果只是从侧面反映景点爆满的问题,未必是完全准确的,仅供参考。此次统计的景点共有 100 个:
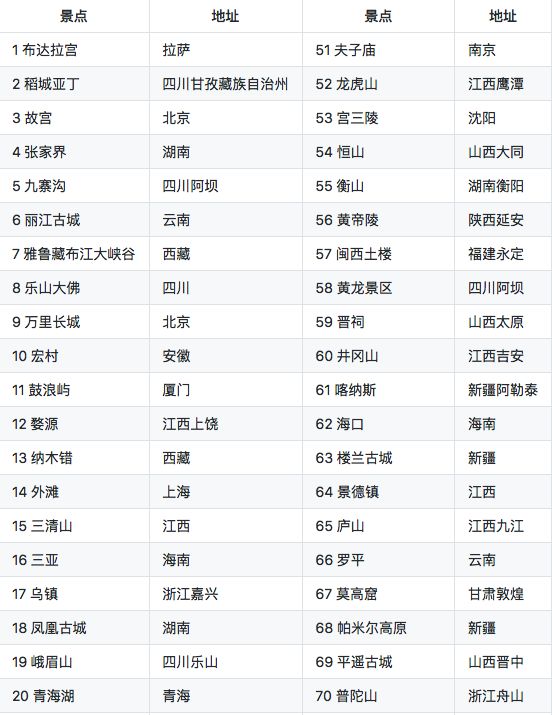
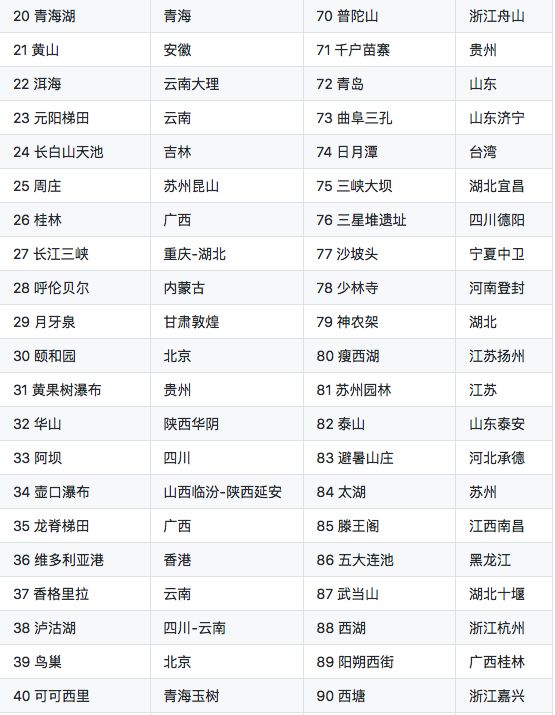
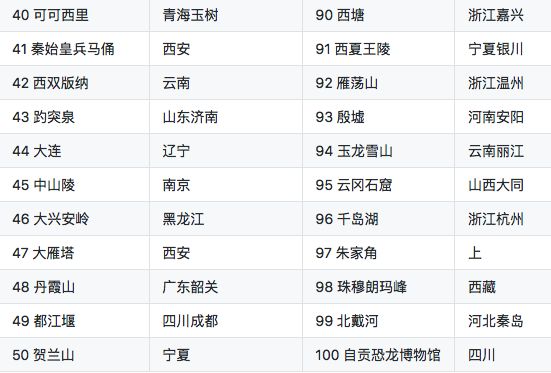
桂林、三亚、泰山的搜索量都是杠杠的,这第一梯队的地方能不去就别去了,去了也是人山人海的,爆满是无疑的了。
 捂脸.jpg
捂脸.jpg
 top0-10
top0-10第二梯队的搜索量也不差,日均搜索量还是上万的,谨慎行动。
 top10-20
top10-20第三梯队下来就可以考虑考虑,为了避免不必要的塞车与等待,建议大家还是呆在家里吧!!!
 top20-30
top20-30
第四梯队应该没太大的问题,建议出去溜达溜达。
 top30-40
top30-40都到第五梯队了,就可以放心地玩耍了。经历了那么多的烦心事,是该好好放飞一下自己了。
 top40-50
top40-50爬虫技术分析
请求库:selenium
HTML 解析:使用正则匹配
数据可视化:pyecharts
数据库:MongoDB
数据库连接:pymongo
爬虫分析实现
此次文章能够实现参考效果,完全是因为抖机灵。首先是选取爬虫来源,携程与马蜂窝没有结构化的数据,我们就换一种思路。首先是想到百度指数,如图:
 百度指数
百度指数
但是,分析源代码之后,你就会发现坑爹之处了,它的数据都是以图片展示的,你不能直接获取到源码,考虑到国庆马上就要到来,我换了一个指数平台,转战搜狗指数,这个平台可以直接获取到源数据,关键是,还有微信热度可以爬取。当然,你执意要使用百度指数,这里也是有方法的,抓取到数据之后,使用图像识别来识别文中的数据,提供一篇有思路的文章 [爬虫实战——四大指数之百度指数(三)]。
关于数据清洗方面,这里筛选了数据量过小,和数据量异常大的景点,详情在源码中查看。
 搜狗指数
搜狗指数
# 这是数据展示的代码片段
def show_data(self):
for index in range(5):
queryArgs = {"day_avg_pv": {"$lt": 100000}}
rets = self.zfdb.national_month_index.find(queryArgs).sort("day_avg_pv", pymongo.DESCENDING).limit(10).skip(index*10)
atts = []
values = []
file_name = "top" + str(index * 10) + "-" + str((index + 1) * 10) + ".html"
for ret in rets:
print(ret)
atts.append(ret["address"])
values.append(ret["day_avg_pv"])
self.show_line("各景点 30 天内平均搜索量", atts, values)
os.rename("render.html", file_name)
爬虫代码实现
由于篇幅原因,这就只展示主要代码,详情请查看源码,点击阅读原文获取源码。
# 这是数据爬取的代码片段
def get_index_data(self):
try:
for url in self.get_url():
print("当前地址为:" + url)
self.browser.get(url)
self.browser.implicitly_wait(10)
ret = re.findall(r'root.SG.data = (.*)}]};', self.browser.page_source)
totalJson = json.loads(ret[0] + "}]}")
topPvDataList = totalJson["topPvDataList"]
infoList = totalJson["infoList"]
pvList = totalJson["pvList"]
for index, info in enumerate(infoList):
for pvDate in pvList[index]:
print("index => "+str(index)+"地址 => "+info["kwdName"] + "日期 => " + str(pvDate["date"]) + " => " + str(pvDate["pv"]) + " => " + str(
info["avgWapPv"]) + " => " + str(info["kwdSumPv"]["sumPv"]) + " => ")
self.zfdb.national_day_index.insert({
"address": info["kwdName"], # 地名
"date": pvDate["date"], # 日期
"day_pv": pvDate["pv"], # 日访问量
})
self.zfdb.national_month_index.insert({
"address": info["kwdName"], # 地名
"day_avg_pv": info["avgWapPv"], # 平均访问量
"sum_pv": info["kwdSumPv"]["sumPv"], # 总访问量
})
except :
print("exception")
后记
整篇爬虫文章分析到这里就结束,不过还是对百度指数很有执念,想找个时间写一篇相关的文章才行,不搞定它感觉心里有块疙瘩,或许这就是程序员最后的倔强,最后祝大家国庆假期愉快,不用写代码。
读BD最佳实践案例,赢DT未来!【政、工、农册免费在线试读】
18各行业,106个中国大数据应用最佳实践案例:
(1)《赢在大数据:中国大数据发展蓝皮书》;
(2)《赢在大数据:金融/电信/媒体/医疗/旅游/数据市场行业大数据应用典型案例》;
(3)《赢在大数据:营销/房地产/汽车/交通/体育/环境行业大数据应用典型案例》;
(4)《赢在大数据:政府/工业/农业/安全/教育/人才行业大数据应用典型案例》。【本册免费在线试读,PC打开连接:https://item.jd.com/12058567.html】
推荐文章
微信ID:SDx-SoftwareDefinedx
❶软件定义世界, 数据驱动未来;
❷ 大数据思想的策源地、产业变革的指南针、创业者和VC的桥梁、政府和企业家的智库、从业者的加油站;
❸个人微信号:sdxtime,
邮箱:[email protected];
=>> 长按右侧二维码关注。

 底部新增导航菜单,下载200多个精彩PPT,持续更新中!
底部新增导航菜单,下载200多个精彩PPT,持续更新中!









