
0.
经济学人的文章语言好,内容足。就学英语而言,我们可以怎么用、怎么整理呢?
我平时主要拿来作三个用途。
1.
用 site 语法核查表达。
site 是个搜索引擎语法,后面接具体的网站,作用是指定范围,只搜索后面的这个网站的内容。
比如,想看看 beef up 这个搭配,是不是可以用?经济学人是怎么用的?就可以 Google 搜索:
beef up site:economist.com
意思就是说,我只在经济学人官网所有文章中,搜索带有 beef up 这两个词的文章。如图:
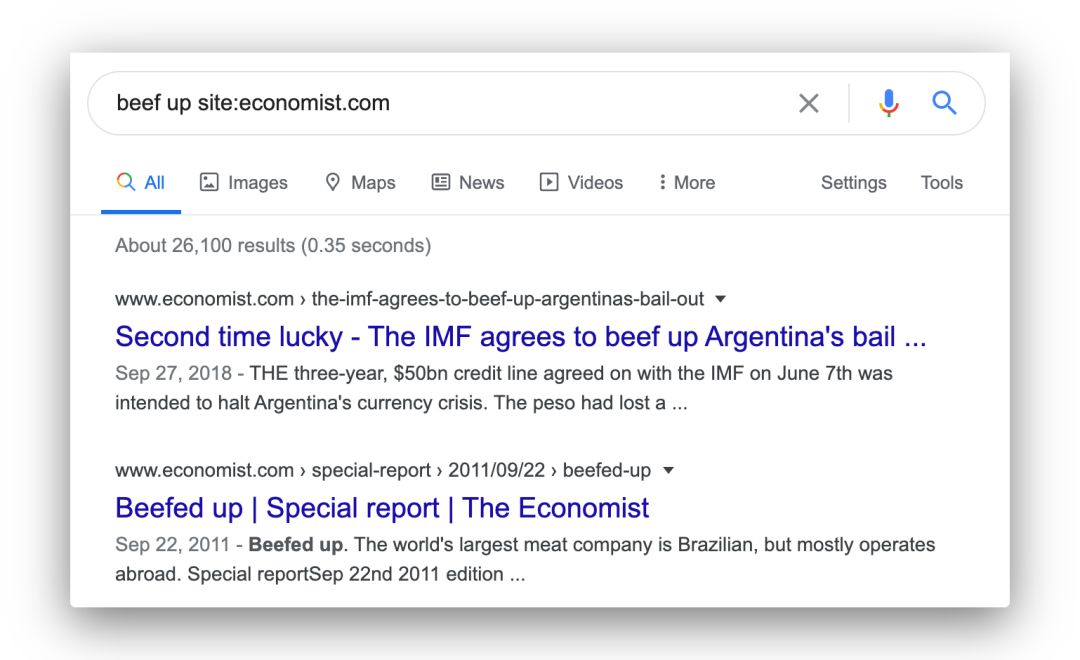
这其实就是把经济学人当作线上语料库来用。这么用,方便是方便,但搜出来的结果会有两个小问题,如图:

1)只有 beef 或 up 单独出现的文本,也在结果中,但这不是我们需要的结果,我们只需要 beef up 连在一起的;
2)这时的结果包括了「读者评论」,这是读者在文章底下的留言,这部分语料质量参差不齐,筛选成本大,最好是能在搜索时就让引擎直接刨除。
逐个解决:
问题一:想只搜出 beef 和 up 连着出现的表达,需要给关键词加上双引号:
“beef up” site:economist.com
结果如图:
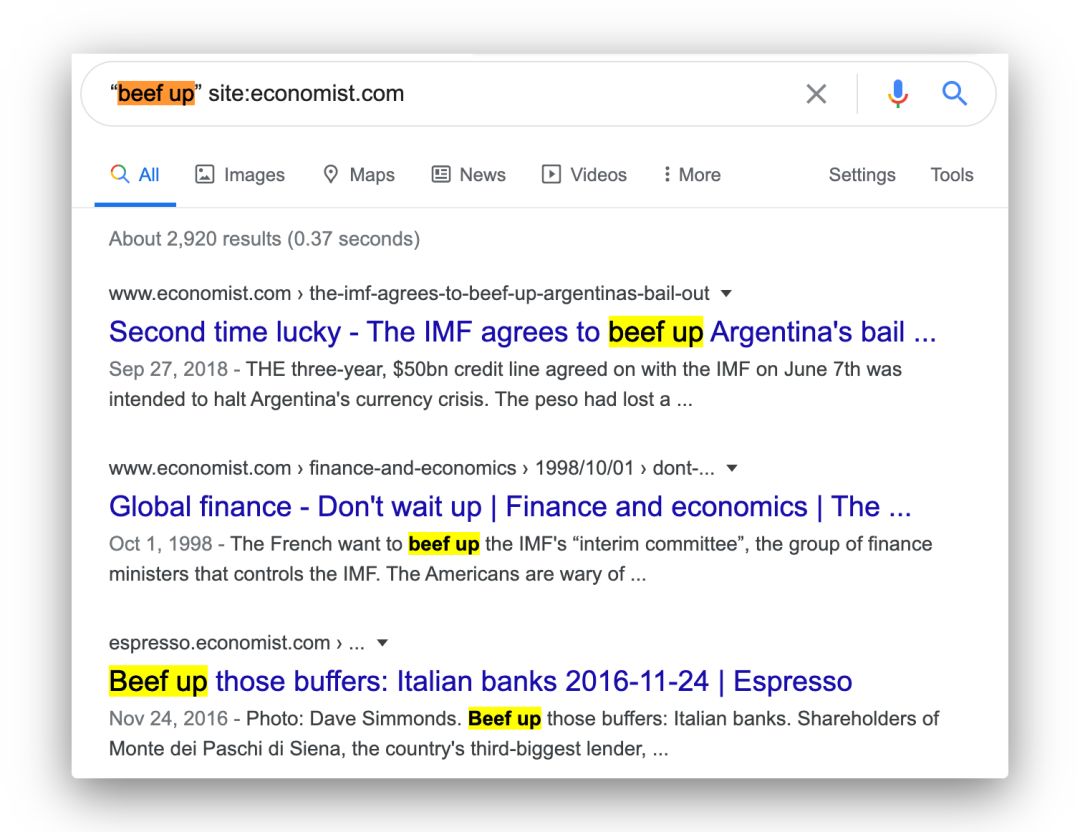
可以看到,结果数量从原来的 2 万多,变为现在的 2 千多,只单独出现了 beef 或 up 的文本,全部排除了,精确不少。
问题二:批量筛除读者评论,要先观察规律,看看这些文本有什么共同点,发现:这些带评论的链接,标题中都会带有 comments 字样。
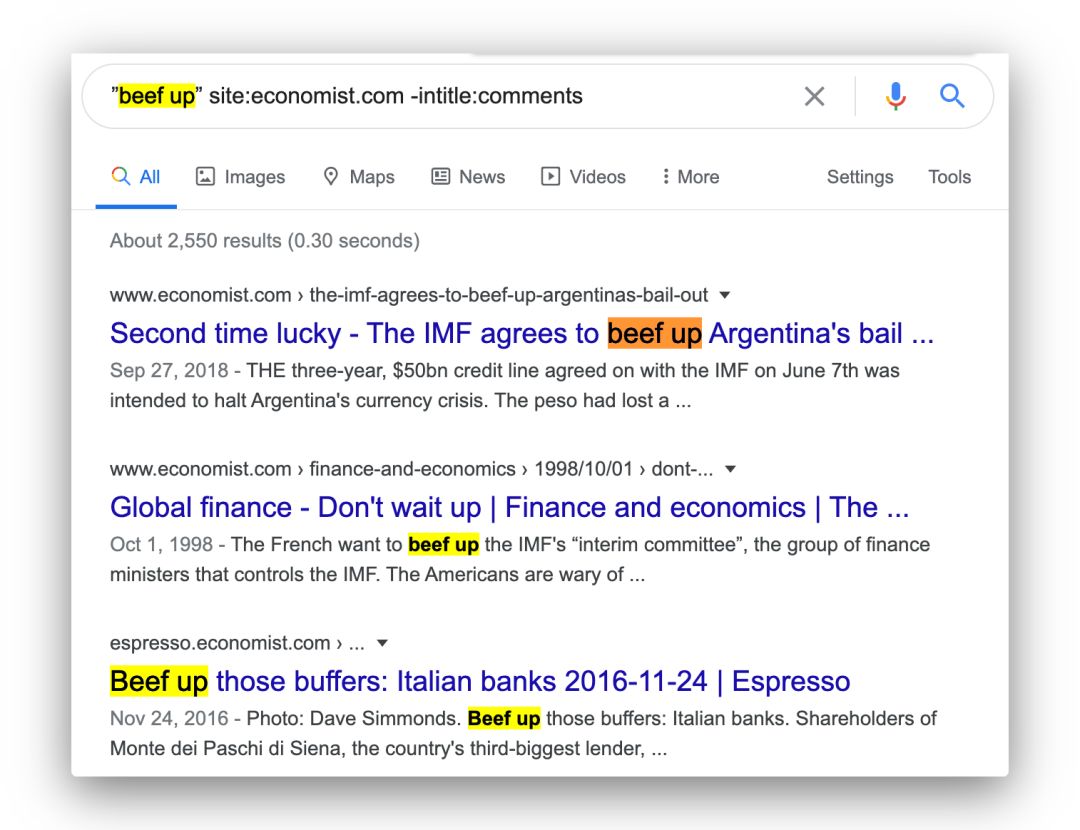
那就可以让搜索引擎来干活了——凡是标题带有 comments 字样的,都排除。写成搜索式子:
“beef up” site:economist.com -intitle:comments
其中,
-
减号指排除接下来的内容;
intitle
是「包含在标题中」。这时结果就精简且准确:
但还有个小问题:这式子又是 site 又是 intitle 的,一大长串,难敲。如果都要逐字手打,那就很麻烦了。
怎么解决?
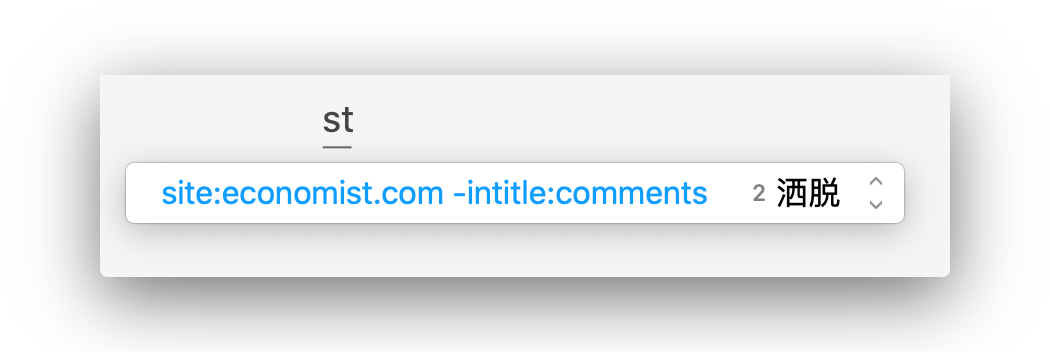
可以利用搜狗输入法等应用的快捷短语功能,把搜索式子添加到自定义短语中去。
比如,可以设定你在输入法键入
st
,就自动给你 site:economist.com -intitle:comments 的结果。如图:
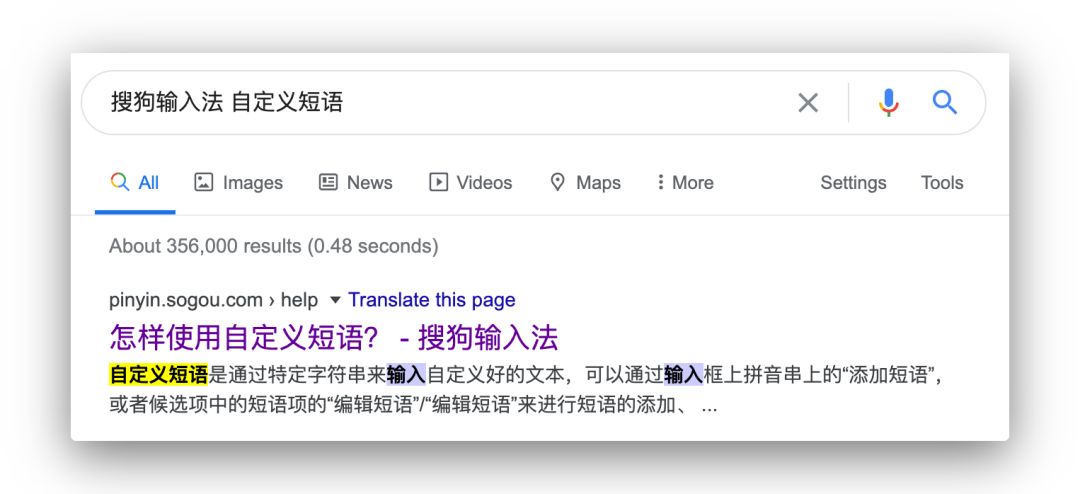
设置很简单,如果你还不会,Google 一下关键词:「搜狗输入法 自定义短语」。第一条就是了:
同样的功能,也可以通过 aText、TextExpander 等应用实现。
2.
主题阅读。
不管是准备雅思、托福还是翻译考试,常常要就一个具体主题积累大量表达,有的是词组搭配,有的是术语行话。这些都可以在经济学人文章里批量学习。
办法很简单:
还是先 site 主题词,搜出需要的文章,加入待读列表,最后批量阅读。
举例:
比如你想了解「新冠疫情」的说法搭配,就可以挑出这个话题关键词,用 site 搜索经济学人官网,再挑出需要的文章。
不过,由于新冠的英文名称目前提法较多,多方公认的新名又才确定不久,不好拿到这里作关键词搜索。但谈及这个话题,多半会提到武汉,不妨就以 wuhan 为关键词,来搜搜看:
wuhan site:economist.com -intitle:comments
如图:
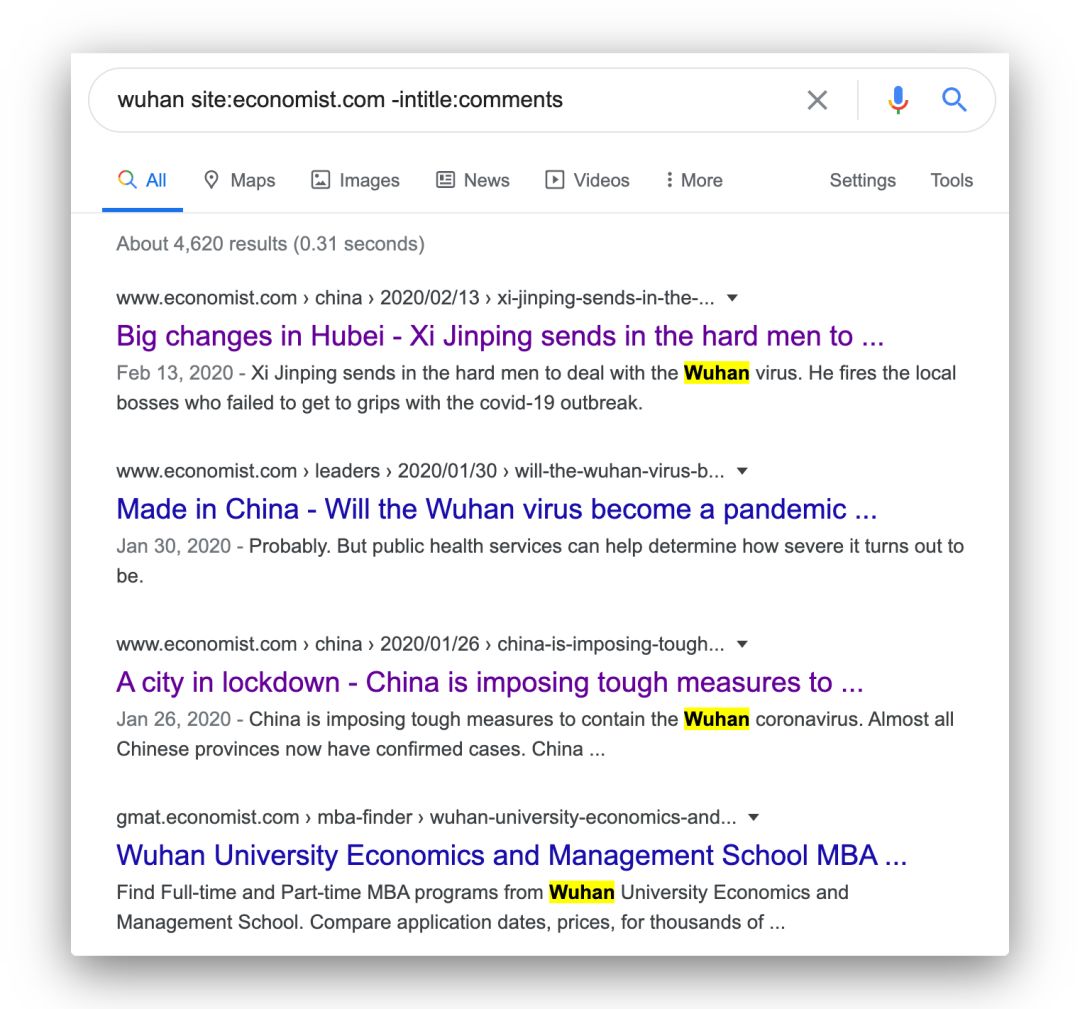
可以看到,排在前面的几篇,大都也是讲疫情的。但这么搜,会有个问题:
搜索引擎会把以前讲武汉别的方面的文章,也都搜出来,而这些文章是跟我们要了解的话题无关的;更不用说,有些只在正文提了一嘴武汉的,也在结果当中。
怎么筛选呢?
本着能剥削机器就不剥削人的原则,办法还是:让搜索引擎直接排除无关结果,只拉取最相关的文章。
怎样的文章是更主题相关的呢?很简单:
标题中含有关键词的文章。
于是,可同样用 intitle 语法来限定,修改式子为:
intitle:wuhan site:economist.com -intitle:comments
看看结果:
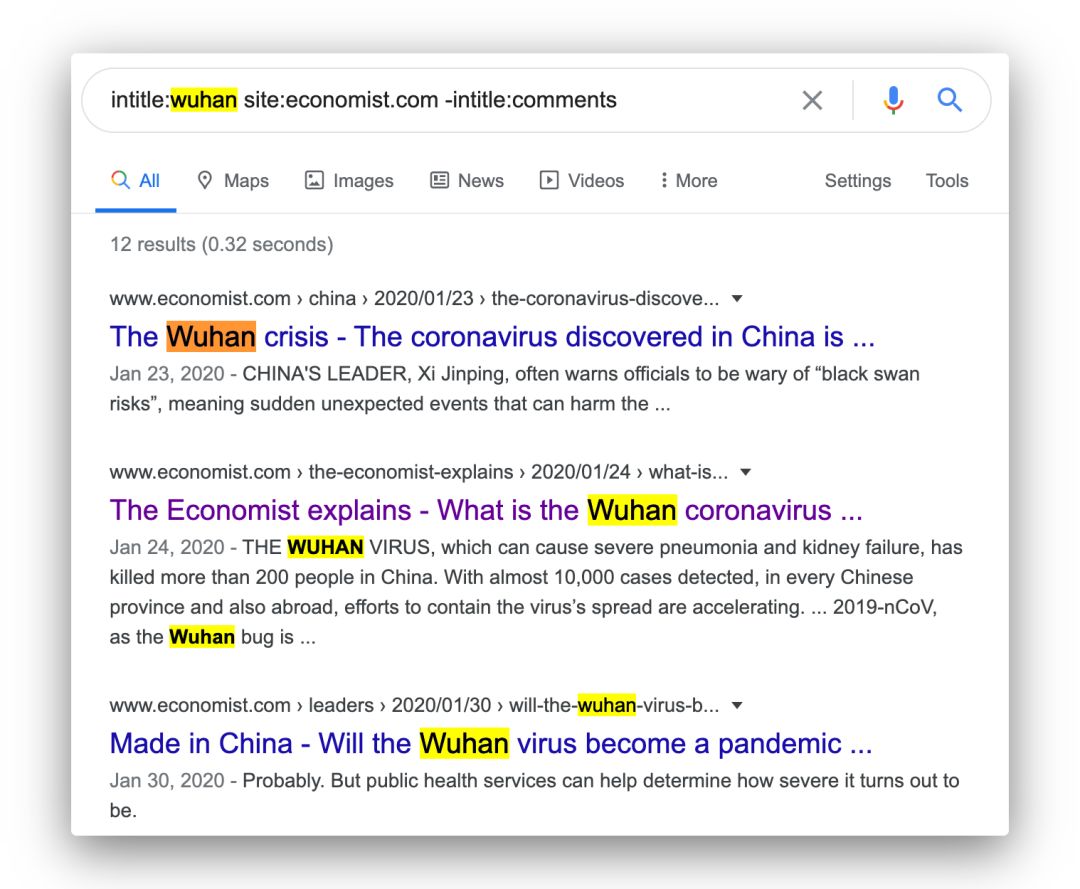
结果数从 4000 多降到了 12 篇,再扫扫标题挑一挑,是很容易的。
这时搜索完成,可以着手阅读了,但一下搜出来十几篇文章,全部点开,浏览器有十几个 tab,一趟是肯定读不完的,怎么办呢?怎样保存我的筛选记录,方便我下次调用呢?
这时就可以用上浏览器插件:OneTab。
这是个 Google Chrome 插件,有数百万安装量,你也可以在 Firefox 等浏览器上找到。

装好后,你只需要在浏览器的工具栏点一下 OneTab 的图标,它就会自动把刚刚打开的多个浏览器标签,全部收到一个插件主页,备你稍后阅读。
比如拿我们刚刚搜到的几篇文章,在浏览器点开再一键收到 OneTab 后,是这样的:
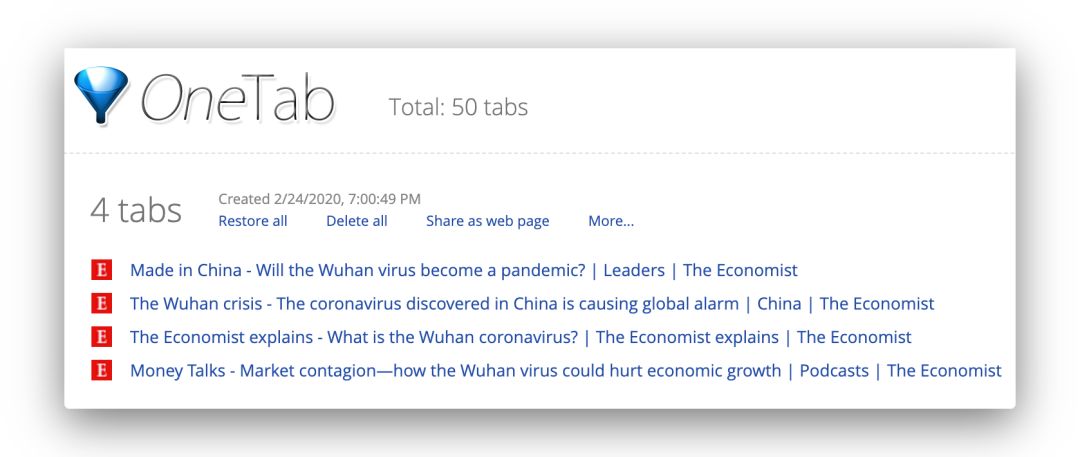
这有点像一张临时阅读清单,OneTab 先帮你一键把东西都按条目理好收好,你什么时候准备妥帖,就可以来读。
并且,这张阅读清单,你可以一键 restore all 恢复全部页面,也可以一键删除,甚至还可以点击 share 选项,把你筛选的文章列表生成链接,分享给别人阅读。
3.
积累话题语块。
同一个主题的多篇文章筛选出来后,这个话题高频、核心、必会的表达,基本也会都覆盖了。但文章里的表达怎么整理、积累呢?
首先要明确整理和积累的基本单位:
话题语块。
「话题语块」是个我平时常用的说法,它不指单词,也不是纯词组,而是可以独立见义的英文搭配。你看到这样一个搭配,就能知道当中核心词的用法,也能在脑海联想到对应的情景。
来练习一下:
- keep
- keep back
哪个是话题语块?
两个都不是。
keep 显然不是,keep back 为什么也不是?因为你光看到这个词组,你还是不知道它到底说的是什么。但 keep back her tears,这就是了。
而且,掌握一个这样的话题语块,你的收获是多方面的。










