转自老顾谈几何
公众号ID:conformalgeometry
作者:顾险峰

图1. 基于最优传输映射(Optimal Mass Transportation Map)的保面积映射(area-preserving mapping)。
今天老顾讲解了Wasserstein GAN模型和最优传输理论的几何解释,详细给出了W-GAN中关键概念的几何理解,包括概率分布(probability distribution)、最优传输映射(Optimal Mass Transportation Map)、Brenier势能、Wasserstein距离等等。理论上,深度学习领域中常用的概率生成模型(Generataive Model)都可以用最优传输理论来分析,随机变量生成器都可以用最优传输映射来构造。相比于传统神秘莫测的深度神经网络(DNN),最优传输映射是完全透明的,用最优传输理论来探索深度神经网络,可以帮助我们更好的理解深度学习的本质。今天,很多研究生和几位教授听了老顾的讲座,随后和老顾展开了热烈的讨论,并对一些基本问题展开了深入的交流。下面,老顾开始撰写下一次的课程讲义。
深度学习的方法强劲有力,几乎横扫视觉的所有领域,很多人将其归功于神经网络的万有逼近能力(universal approximation property):给定一个连续函数或者映射,理论上可以用(一个包含足够多神经元的隐层)多层前馈网络逼近到任意精度。对此,老顾提出另外的观点:有些情况下,神经网络逼近的不是函数或映射,而是概率分布;更为重要的,逼近概率分布比逼近映射要容易得多。更为精密的说法如下:在理想情况下,即逼近误差为零的情形,如果神经网络逼近一个映射,那么解空间只包含一个映射;如果神经网络逼近一个概率分布,那么解空间包含无穷个映射,这些映射的差别构成一个无穷维李群。
我们这一讲就是要证明这个观点,所用的工具是(包括无穷维)微分几何。
二十年前,老顾在哈佛学习的时候,Mumford教授、师兄朱松纯就已经系统性地将统计引入视觉,他们提出了用图像空间中的概率分布来表示视觉概念的纲领。今天,一些深度学习的模型(例如GAN)所遵循的原则和他们的纲领是一脉相承的。这也正是老顾更为看好逼近概率分布,而非逼近映射的原因之一。
我们先看最简单的(伪)随机数生成器。我们选取适当的整数 ,计算序列
,计算序列

那么 给出了随机变量,符合单位区间的均匀分布(uniform distribution)。由均匀分布,我们可以生成任意的概率分布。例如,我们可以构造一个映射
给出了随机变量,符合单位区间的均匀分布(uniform distribution)。由均匀分布,我们可以生成任意的概率分布。例如,我们可以构造一个映射 ,
, 将单位正方形上的均匀分布映射成平面上的高斯分布:
将单位正方形上的均匀分布映射成平面上的高斯分布:
 。
。
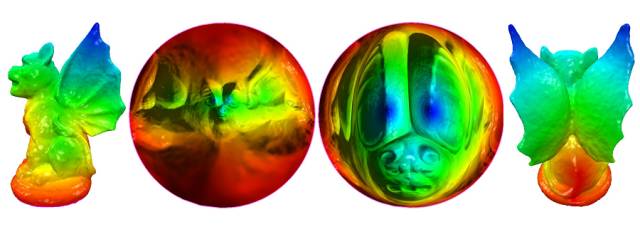 图2. 怪兽的最优传输映射。
图2. 怪兽的最优传输映射。
在上一讲中,我们给出了最优传输理论的几何解释。给定一个区域 ,其上定义着两个概率测度
,其上定义着两个概率测度 和
和 ,则唯一存在一个最优传输映射
,则唯一存在一个最优传输映射 ,将概率分布映射成概率分布,亦即对于一切可测集合
,将概率分布映射成概率分布,亦即对于一切可测集合 ,
,
 ,
,
记为 ,并且极小化传输代价
,并且极小化传输代价
 。
。
这个最优传输映射是某个凸函数的梯度映射,这个凸函数被称为是Brenier势能函数,满足蒙日-安培方程。如图2所示,我们将怪兽曲面(第一帧和第四帧)保角地映射到平面圆盘上面(第二帧),保角映射将曲面的面积元映射到平面上,诱导了平面圆盘上的一个概率测度。平面圆盘上也有均匀概率分布(第三帧),从第二帧到第三帧的映射为最优传输映射。图1和图3显示了基于最优传输映射的曲面保面积参数化(Surface Area-preserving Parameterization)。
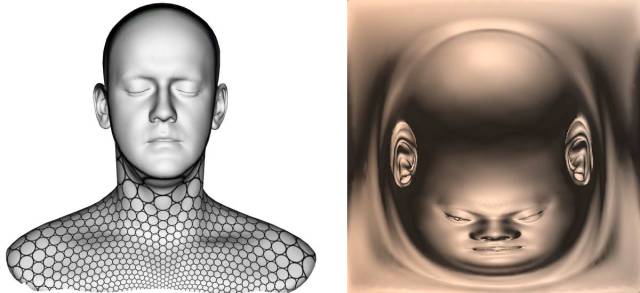
图3. 基于最优传输映射(Optimal Mass Transportation Map)的保面积映射(area-preserving mapping)。
在Wasserstein生成对抗网络中(Generative Adversarial Network), 生成器(generator)可以被抽象为一个非线性映射 。
。 将全空间映到自身,同时将均匀概率分布映射成概率分布,
将全空间映到自身,同时将均匀概率分布映射成概率分布, ,同时尽量极小化概率分布和真实数据概率分布之间的Wasserstein距离。那么,我们的问题是:
,同时尽量极小化概率分布和真实数据概率分布之间的Wasserstein距离。那么,我们的问题是:
满足保持测度条件的映射是否唯一?如果不唯一,又有多少?
对于这个问题的彻底解答需要用到映射极分解理论(Mapping Polar Decomposition)。
我们考虑所有的可微双射 ,满足条件
,满足条件 。存在唯一的最优传输映射,它是Brenier势能函数
。存在唯一的最优传输映射,它是Brenier势能函数 的梯度映射
的梯度映射 。映射的极分解理论就是说
。映射的极分解理论就是说 可以分解成两个映射的复合(composition),
可以分解成两个映射的复合(composition),
 ,
,
这里映射 保持初始测度不变,因此的雅克比行列式处处为1。所有这种在映射复合的意义下构成一个李群(Lie Group),被称为是保体积微分同胚群(Volume-Preserving Diffeomorphisms),记为
保持初始测度不变,因此的雅克比行列式处处为1。所有这种在映射复合的意义下构成一个李群(Lie Group),被称为是保体积微分同胚群(Volume-Preserving Diffeomorphisms),记为 。我们下面来说明,这个李群是无穷维的。
。我们下面来说明,这个李群是无穷维的。
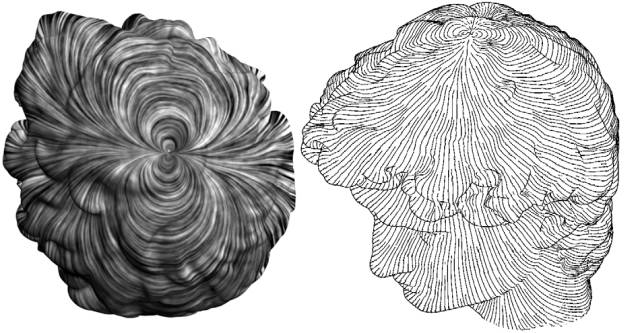
图4. 曲面上的光滑矢量场。
如图4所示,我们在曲面上构造一个光滑切向量场 ,则切向量场诱导了曲面到自身的一个单参数微分同胚群
,则切向量场诱导了曲面到自身的一个单参数微分同胚群 ,满足常微分方程:
,满足常微分方程:
 。
。
直观上,切向量场可以视作曲面上的一个流场,每一点p依随这个流场流动,流动的速度向量等于矢量场在p点处的切向量。在时刻 t,流场初始点到终点的映射,就给出了微分同胚 。那么,如果切矢量场的散度(divergence)处处为0,则的雅克比行列式处处为1,即不可压缩流场诱导保体积微分同胚。这一点,可以用嘉当的神奇公式来证明(Cartan's Magic Formula)。
。那么,如果切矢量场的散度(divergence)处处为0,则的雅克比行列式处处为1,即不可压缩流场诱导保体积微分同胚。这一点,可以用嘉当的神奇公式来证明(Cartan's Magic Formula)。
我们来仔细解释嘉当的神奇公式。我们以平面为例,平面的面元是一个2阶微分形式(2-form) 。考察任意一个区域
。考察任意一个区域 ,在微分同胚下的像为区域
,在微分同胚下的像为区域 。像的面积为
。像的面积为
 ,
,
由此,我们定义所谓的拉回2-form ,
,
 ,
,
那么关于时间t的导数被称为面元 关于矢量场的李导数(Lie Derivative),记为
关于矢量场的李导数(Lie Derivative),记为
 。
。
嘉当的神奇公式具有形式:
 ,
,
这里d是外微分算子。在平面上,为2-形式,因此 恒为0。如果矢量场
恒为0。如果矢量场 散度处处为0,则
散度处处为0,则 恒为0。直接计算得到:
恒为0。直接计算得到:
 ,
,
因此 我们得到
 。
。
因此面元关于矢量场的李导数为零。微分同胚保持面元不变,的雅克比行列式处处为1。
由此可见,曲面上不可压缩流场(散度为0的切矢量场)诱导保面积微分同胚。曲面上任选一个光滑函数,其梯度场旋量处处为0。在曲面上任意一点p处,我们将梯度向量围绕法向量逆时针旋转90度,所得的矢量场散度处处为0。我们知道,曲面上的函数是无穷维的,因此无散场也是无穷维的,保面积微分同胚群也是无穷维的。
我们现在可以回答上面提出的问题,满足保持测度条件的映射不唯一;所有这种映射可以表示成保体积微分同胚和最优传输映射的复合;保体积微分同胚是无穷维的。
图5. 两个满足保测度条件的映射,彼此相差一个保体积微分同胚。
从理论上讲,如果我们两次训练GAN网络,其生成器所得到的映射之间相差一个保体积微分同胚 。保体积微分同胚群内有一个自然的黎曼度量:我们在保体积微分同胚群内构造一条路径,
。保体积微分同胚群内有一个自然的黎曼度量:我们在保体积微分同胚群内构造一条路径,
 ,
,
连接着两个同胚 ,
, 。这条路径的长度可以计算
。这条路径的长度可以计算
 ,
,
两个保体积微分同胚之间的距离定义为连接它们的所有路径长度中最短者。用这个度量,我们可以定量测量两次训练结果的内在差异程度。保体积微分同胚群的度量几何(无穷维微分几何)在视觉领域和医学图像领域被作为形状空间的一种理论工具。
小结
通过以上讨论,我们看到如果用一个深度学习的网络来逼近一个映射,解空间只有一个映射;如果来逼近一个概率分布,则解空间为无穷维的保体积微分同胚群。因此,用深度学习网络来逼近一个概率分布要比逼近一个映射、函数容易得多。这或许可以用来解释如下的现象:基于老顾以往的经验,我们用神经网络来求解非线性偏微分方程,要比用神经网络给图像分类困难,因为前者需要精确逼近泛函空间中的可逆映射,而后者需要逼近图像空间中的概率分布。
©本文为机器之心转载文章,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]










