在五月底与柯洁等人的系列对局之后,人工智能围棋大师 AlphaGo 已经功成名就,金盆洗手了,参阅《现场报道 | AlphaGo 被授职业九段,DeepMind 将公开其所有版本细节》;但这并不意味着计算机围棋研究已经走到了尽头。近日,北京大学的一组研究团队宣称在计算机围棋研究上取得了另一个方向的研究成果。
和 AlphaGo 等目前领先的围棋程序不同,北京大学 Wang Jinzhuo、王文敏、王荣刚、高文等人提出的新方法没有使用蒙特卡洛树搜索,而是使用了由深度交替网络(DANN)和长期评估(LTE)组成的系统。而且研究者还通过实验表明该系统的棋力也强于目前大多数基于蒙特卡洛树搜索的方法。
并不完美的蒙特卡洛树搜索
围棋是一种古老的智力游戏,规则简单,但变化复杂。由于棋局变化的可能性是海量的,在大多数情况下,我们很难对棋盘上的落子位置构建价值函数。此前,大多数计算机围棋程序都着重于模拟未来棋局可能的变化,从而选择最佳落子位置。在这种思路下,蒙特卡洛树搜索(MCTS)(Gelly & Silver 2011)是最为流行的方法,它构建了一个广泛而深入的搜索树来模拟和评估每个落子位置的价值。利用这种方法构建的围棋程序已经获得了很大成功。
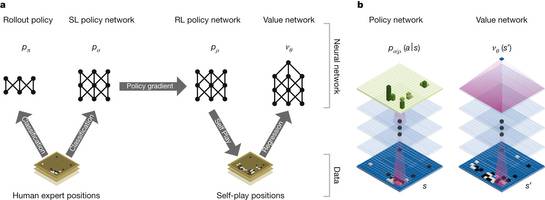
AlphaGo 结合了监督学习与强化学习的优势。通过训练形成一个策略网络,将棋盘上的局势作为输入信息,并对有所可行的落子位置形成一个概率分布。然后,训练一个价值网络对自我对弈进行预测,以-1(对手的绝对胜利)到 1(AlphaGo 的绝对胜利)的标准,预测所有可行落子位置的结果。AlphaGo 将这两种网络整合进基于概率的蒙特卡罗树搜索(MCTS)中,实现了它真正的优势。
然而,蒙特卡洛树搜索的方法并不是完美的,性能不平衡是这种方法的主要限制。人们发现,利用蒙特卡洛树方法构建的围棋程序在对杀、劫争和关子时时常会出现错误的选择。人们将这些缺陷归于两种原因:1. 剪枝搜索是基于先验知识的动作,距离完美的计算还相去甚远;2. 由于围棋的棋盘是广阔的,对于大部分可能性的计算是无用的。此外,蒙特卡洛树的叶子输出难以得到精确评估。
而最重要的是,MCTS 的方法和人类棋手并不相同,因为人类并不会对每一个可能的点位进行粗暴的模拟。相反,人类在落子时会首先通过特征分析选择几个可能的点位,并通过评估这些点位从中选择一个最优的下法。
随着近年来深度学习在图像识别等领域的兴起,研究人员开始引入深度学习的方法来构建新一代围棋程序。与视觉信号相比(如 224x224 像素的图片),围棋棋盘的尺寸更小(19x19),而各点的相对位置十分重要,这与围棋牵一发而动全身的理念相类似。另一方面,现有的 DCNN 通常通过堆叠更多的卷积层以利用低级特征的高阶编码来进行推理,层数的增加不仅使参数负担增加,也无法嵌入局部特征及其演化。
基于上述讨论,北京大学的研究者们提出了由两个主要部分构成的新型计算机围棋系统。
论文:超越蒙特卡洛树搜索:使用深度交替网络和长期评估下围棋(Beyond Monte Carlo Tree Search: Playing Go with Deep Alternative Neural Network and Long-Term Evaluation)

论文链接:https://arxiv.org/abs/1706.04052
摘要
在计算机围棋领域,蒙特卡洛树搜索(MCTS)是一种极其流行的方法,其可以通过在一个宽阔且深度的搜索树中进行巨量的模拟来确定每一步动作。但是,人类专家是通过模式分析和精心的评估来选择大多数的动作,而非对未来数百万次互动进行暴力搜索来完成。在这篇论文中,我们提出了一种可以像专家一样思考和下棋的计算机围棋系统。我们的系统由两部分组成。
第一部分是一个全新的深度交替神经网络(DANN/deep alternative neural network),用于生成下一步的候选项。和已有的深度卷积神经网络(DCNN)相比,DANN 会在每个卷积层后插入一个循环层,以一种交替的方式将它们堆叠在一起。我们表明这样的设置可以保留更多局部特征及其演化的背景信息(context),这有助于做出走子预测。
第二部分是一个长期评估(LTE/long-term evaluation)模块,用于提供对候选项的可靠评估,而不仅仅是来自走子预测器的单个概率。这与人类专家下棋的本质是一致的,因为他们可以预见未来数十步并对候选项给出一个准确的评估。在我们的系统中,对于每个候选项,LTE 会在局部变化确定了之后计算未来几次交互的累积奖励。
结合来自这两个部分的指标,我们的系统可以确定下一步的最优选择。为了更加全面的实验,我们引入了一个新的职业围棋数据集(PGD),其包含了 253233 局职业对弈记录。在 GoGoD 和 PGD 数据集上的实验表明,相对于 DCNN,DANN 可以显著提升走子预测的表现。当结合了 LTE 后,我们的系统的表现优于大多数基于 MCTS 的相关方法和开放引擎。

图 1:研究人员提出使用深度交替神经网络(DANN)和长期评估(LTE)的计算机围棋系统。给定一个局面,该系统可通过 DANN 生成多个候选项——DANN 在职业对弈记录上学习过。LTE 会对这些候选项进行进一步的分析,考虑了未来回报后确定最终的动作。
深度交替神经网络
深度交替神经网络以当前的棋盘情况作为输入,生成可能的未来变化分布。研究人员将 19x19 的棋盘视为带有不同通道的 19x19 像素图片,每个通道的编码承载一种棋盘信息。
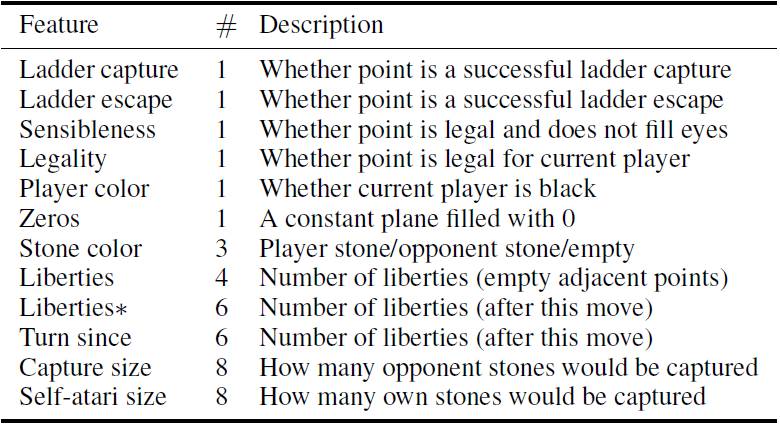
表 1. 用于 DANN 的输入特征通道
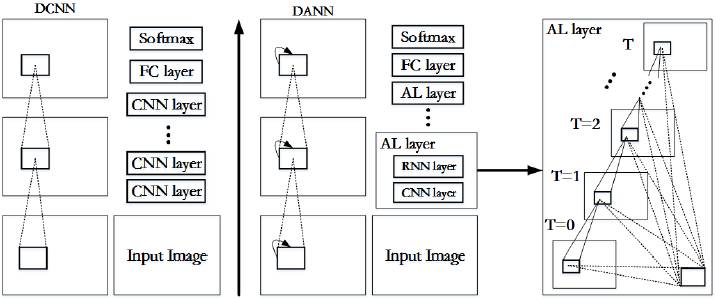
图 2:DANN(右)和 DCNN(左)的比较。
长期评估模块
DANN 给出了下一步的可能性分布,而长期评估模块则进一步加强了模型的性能,因为仅预测下一步会限制低层神经网络的信息获取。此外,在激烈的局面和对杀情况下,很多情况会让系统难以评估。当局部变化得到解决后,我们需要准确的判断。此前已有一些研究将游戏视为视觉环境下人工智能代理面临的连续决策过程。在这里,研究人员使用了类似的理念,通过计算未来可能交互行动的累积奖励来评估下一步的位置。结合此前的概率评估,系统得到了下一步可能的分数,并确定最终的落子位置。
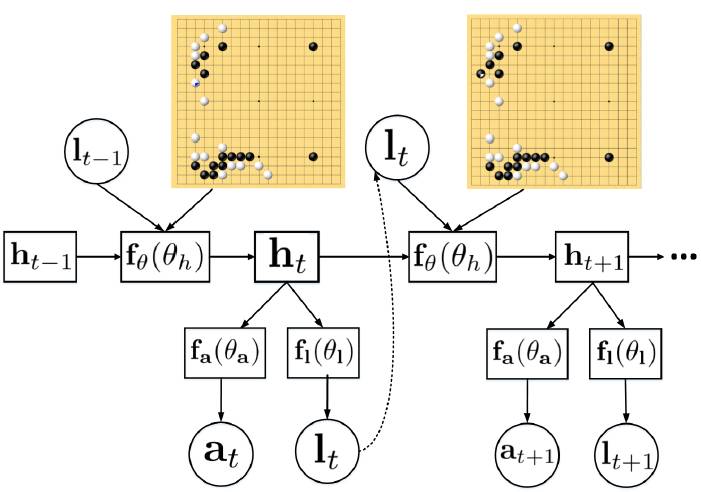
图 3:用于长期评估的循环模型

表 3:新系统和之前的成果(开源引擎)之间的胜率比较
棋力
研究人员使用了一些开源的围棋程序对新方法和基准方法进行了测试。所有对战程序都被调至了最高难度,每步的 rollout 数量固定。在实验中,新的方法与 GnuGo 3.8 level 10、MoGo、Pachi 11.99(带有模式文件)以及 Fuego 1.1 等方法进行了比较。在每类对战中,共进行三组 100 场的对弈。上表显示了对战的胜率,所有比赛均采用中国围棋规则。结果显示,新的方法在大多数情况下占据优势,但性能略低于田渊栋等人 2016 年在 Facebook 的研究。
作者表示,未来的研究方向包括进一步改进 DANN 的结构以更好预测未来步骤,更可靠的 LTE 应用等。此外,来自计算机视觉领域的残差网络也有可能帮助 DANN 获得性能提升。在长期评估方面,围棋知识可为下一步棋的选位提供更有效的估计。 
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]
点击阅读原文,查看机器之心官网↓↓↓









