导读:
10亿级,是微信用户的数量级。这个庞大数字的背后,是“看一看”、“微信广告”、“微信支付”、“小程序”等业务对数据库10亿级的读写需求。那么,在此场景下诞生的 FeatureKV,究竟是怎样强悍的一个存储系统呢?
背景:
两个十亿级的挑战
PaxosStore 是微信内广泛应用的强一致性的分布式存储系统,它广泛支撑了微信的在线应用,峰值过亿TPS,运行在数千台服务器上,
在线服务场景下性能
强悍
。但在软件开发中没有银弹,在面对
离线产出、在线只读
的数据场景,PaxosStore 面临了
两个新的
十亿挑战
:
10亿 / 秒 的挑战:
-
“看一看”团队需要一个存储系统来存放CTR过程需要用到的模型,实现存储和计算分离,使得推荐模型的大小不会受限于单机内存。
-
每次对文章的排序打分,ctrsvr 会从这个存储系统中拉取成千上万个特征,这些特征需要是
相同版本
的,PaxosStore 的 BatchGet 不保证相同版本。
-
业务方预估,这个存储系统需要支持
10亿/秒
的QPS,PaxosStore 的副本数是固定的,无法增加只读副本。
-
这个存储系统需要有版本管理和模型管理的功能,支持历史版本回退。
10亿 / 小时 的挑战:
-
微信内部不少团队反馈,他们需要把
10亿
级(也就是微信用户的数量级)信息,每天定期写到 PaxosStore 中,但 PaxosStore 的写入速度无法满足要求,有时候甚至一天都写不完,写太快还会影响现网的其他业务。
-
PaxosStore 是一个保证
强一致性
的存储系统,为在线业务设计,其性能也能满足在线业务的需求。
但面对这种离线灌库、在线只读、不要求强一致性保证的场景,就需要很高的成本才能满足业务的需求了。
-
基于数据的应用越来越多,这类的数据存储需求也越来越多,我们需要解决这个问题,把10亿级key量的数据写入时间控制在1个小时左右。
上述场景具有
定时批量写、在线只读
的特点,为了解决这些场景的痛点问题,我们基于性能强大的
WFS(微信自研分布式文件系统)
和稳如磐石的
Chubby(微信自研元数据存储)
,设计并实现了
FeatureKV
,它
是一个高性能 Key-Value 存储系统,
具有以下特点
:
高性能且易于扩展
-
优秀的读性能
: 在B70机型上,全内存的表可以有千万级的QPS;
在TS80A机型上,数据存放于SSD的表可以有百万级的QPS。
-
优秀的写性能
: 在远程文件系统性能足够的情况下,可以在1小时内完成十亿个key、平均ValueSize是400Byte的数据的写入。
-
易于扩展
: 水平扩容(读性能)和纵向扩容(容量)可以在数小时内完成,写性能扩容只是扩容一个无状态的模块(DataSvr),可以在分钟级完成。
对批量写支持友好
具有版本管理功能
当然,在软件开发中没有银弹,FeatureKV 在设计上它做了取舍:
FeatureKV 现在在微信内部已经广泛应用,包括看一看、微信广告、微信支付、小程序等业务,接下来会阐述 FeatureKV 的设计,并具体说明如何解决上述两个
十亿挑战
。
总体设计
1. 系统架构
FeatureKV 涉及的外部依赖有三个:
-
Chubby:用来保存系统中的元数据。FeatureKV 内很多地方是通过对 Chubby 内的元数据轮询来实现分布式协同、通信。
-
USER_FS:业务侧的分布式文件系统,可以是 WFS/HDFS ,因为 FeatureKV 的写接口是任务式的,输入是一个分布式文件系统上的路径。
-
FKV_WFS:FeatureKV 使用的分布式文件系统,用来存放 DataSvr 产出的、可以被 KVSvr 使用的数据文件。可以保存多个历史版本,用于支持历史版本回退。
这三个外部依赖都可以和其他业务共用。
FKV_WFS 和 USER_FS 可以是同一个模块。FKV_WFS 可以使用 HDFS 替代。Chubby 可以使用 etcd 替代。
DataSvr:
-
主要负责写数据,把 USER_FS 的输入,经过数据格式重整、路由分片、建索引等流程,生成 KVSvr 可用的数据文件,写到 FKV_WFS 中。
-
它是一个无状态的服务,写任务的状态信息保存在 Chubby 中,扩容 DataSvr,可以增加系统的写性能。
-
一般部署2台就好,部分场景写任务较多可以适当扩容。
KVSvr:
-
对外提供读服务,通过轮询 Chubby 来感知数据更新,再从 WFS 拉取数据到本地,加载数据并提供只读服务。
-
它是一个有状态服务,一个 KVSvr 模块会由 K 个 Sect 和 N 个 Role 组成,共 K * N 台机器。
-
每个 Sect 都有全量的数据,每次 BatchGet 只需要发往某一个 Sect,增加 Sect 可以扩容读性能,而并不会增加 BatchGet 的 rpc 次数。
-
相同的 Role 负责的数据切片都是一样的,单机故障时 Batch 请求直接换机重试就好。
-
K 最少是2,用以保证系统的容灾能力,包括在变更时候的可用性。
-
N 不能是任意一个数字,可以看下面第二部分。
写入流程:
FeatureKV 只支持批量写入数据,每次写任务可以是增量更新/全量更新的,每次写入的数据量大小无限制。
离线的批量写接口设计,我们踩过一些坑
:
-
一开始我们打算封一些类/工具,打算让业务端直接用我们的类/工具,打包Key-Value数据,直接写到 FKV_WFS 的目录上。该方案最省带宽,但是这样做让我们后续的数据格式升级变得很麻烦,需要让所有业务方配合,所以这个方案就废弃了。
-
然后,我们起了一个新模块 DataSvr,在 DataSvr 上面开了一个 tcp svr,业务侧输出 Key-Value,写入工具会把 Key-Value 数据发过来这个 tcp svr 完成打包,但是还是有下面这些问题:
-
写入的速度与业务方的代码质量、机器资源有关,曾经碰到过的情况是,业务方的代码里面用 std::stringstreams 解析浮点数输入,这个函数占用了 90%+ 的 CPU(用 std::strtof 会快很多),或者业务方跑写入工具的机器,被别的进程用了 90%+ 的 CPU ,最后反馈 FeatureKV 写得很慢。
-
DataSvr 的日常变更或机器故障,会导致任务失败。前端工具发包的方法无法对任务进行重试,因为 Key-Value 的输入流无法重放。
最终,
我们设计了一个任务式的接口,以 USER_FS 上的路径作为输入
:
-
业务侧把数据按照约定好的格式,放在 USER_FS 中,向 DataSvr 提交一个写任务。
-
DataSvr 流式读取 USER_FS 中的数据,对数据进行格式重整、路由分片、建索引,然后把数据写入 FKV_WFS 中,并更新 Chubby 中的元数据。其中写任务的分布式执行、失败重试等,也需要通过 Chubby 来同步任务状态。
-
KVSvr 通过轮询 Chubby 感知数据更新,把数据拉取到本地,完成加载并提供服务。
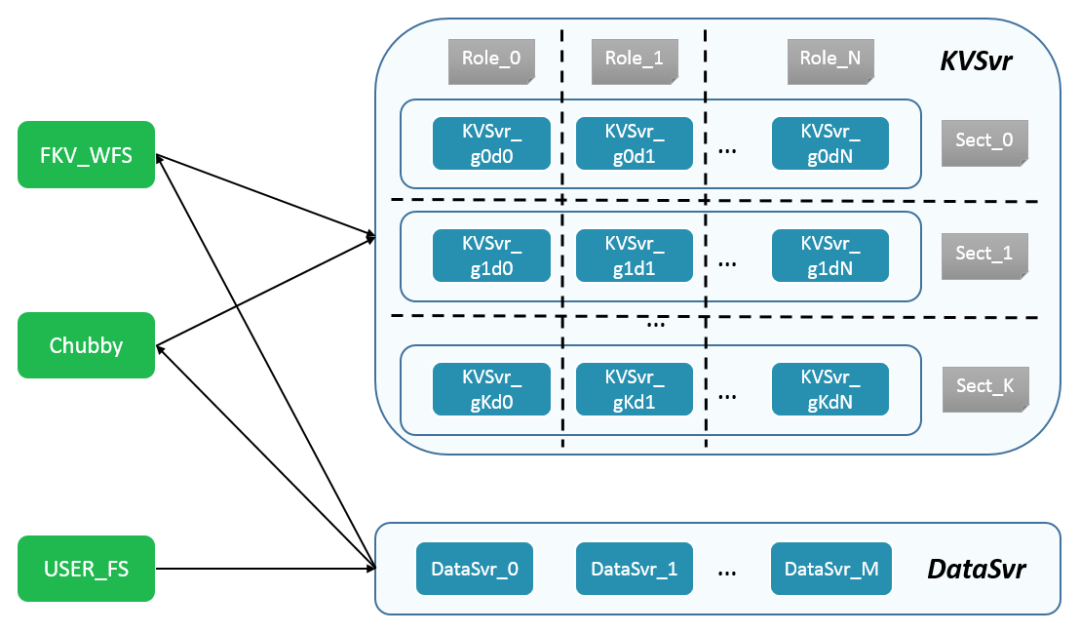
2. 数据路由
-
考虑扩缩容,FeatureKV 会把一个版本的数据切分为 N 份, N 现在是 2400,通过哈希 HashFun(key) % N 来决定 key 属于那份文件。
-
KVSvr 加载哪些文件是由一致性哈希决定的,角色相同的 KVSvr 会加载相同一批在扩缩容的时候,数据腾挪的单位是文件。
-
由于这个一致性哈希只有 2400 个节点,当 2400 不能被 sect 内机器数量整除时,会出现比较明显的负载不均衡的情况。所以 FeatureKV 的 sect 内机器数得能够整除2400。还好 2400 是一个幸运数,它 30 以内的因数包括 1,2,3,4,5,6,8,10,12,15,16,20,24,25,30 ,已经可以满足大部分场景了。
-
上图是 N=6 时候的例子,Part_00[0-5] 表示 6 份数据文件。从 RoleNum=2 扩容成 RoleNum=3 的时候,只需要对 Part_003 和 Part_005 这两份文件进行腾挪,Part_005 从 Role_0迁出至 Role_2,Part_003 从 Role_1 迁出至 Role_2。
-
由于现网所用的 N=2400 ,节点数较少,为了减少每次路由的耗时,我们枚举了 RoleNum<100 && 2400%RoleNum==0 的所有情况,打了一个一致性哈希表。
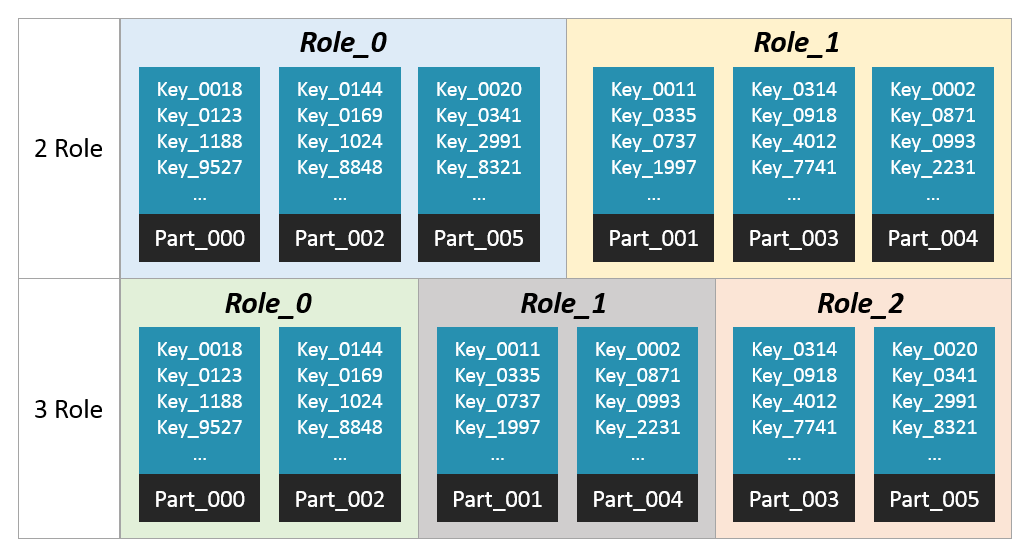
3. 系统扩展性
-
FeatureKV 的 FKV_WFS 上存有当前可用版本的所有数据,所以扩容导致的文件腾挪,只需要
新角色的机器从 FKV_WFS 拉取相应编号的文件,旧角色机器的丢弃相应编号的文件即可。
-
当 BatchSize 足够大的时候,一次 BatchGet 的 rpc 数量等价于 Role 数量,这些 rpc 都是并行的。当 Role 数量较大时,这些 rpc 出现最少一个长尾请求的概率就越高,而 BatchGet 的耗时是取决于最慢一个 rpc 的。上图展示了单次 rpc 是长尾请求的概率是 0.01% 的情况下,不同 Role 数量情况下的 BatchGet 长尾概率,通过公式 1 - (0.999^N) 计算。
-
增加 Sect(读性能扩容)
:
-
增加 Role(存储容量+读性能扩容)
:
-
假设每台机的存储能力是相等的,增加 Role 的数量便可以增加存储容量。
-
由于整个模块的机器都多了,所以读性能也会增加,整个模块在读吞吐量上的扩容效果等价于增加 Sect。
-
但当 Role 数量较大时,一次 BatchGet 涉及的机器会变多,出现长尾请求概率会增大,所以一般建议 Role 的数量不要超过30。
-
增加 DataSvr(写性能扩容)
:
-
数据迁移都是以文件为级别,没有复杂的迁移逻辑
,不考虑灰度流程的话,可以在小时级完成,考虑灰度流程一般是一天内。

4. 系统容灾
-
KVSvr 侧:
-
每个 Sect 的机器是部署在同一个园区的,只需要部署 2 个 Sect 就可以容忍一个园区的机器故障。
-
具体案例:2019年3月23号,上海南汇园区光缆被挖断,某个 featurekv 有 1/3 的机器在上面,故障期间服务稳定。
-
故障期间部分 RPC 超时,导致长尾请求增加。但是换机重试之后大部分请求都成功了,最终失败出现次数很低。后续全局屏蔽了南汇园区的机器之后,长尾请求和最终失败完全消失。
-
DataSvr/WFS 侧:
十亿每秒的挑战 在线读服务的具体设计
1. KVSvr 读性能优化
为了提高 KVSvr 的性能,我们采取了下面一些优化手段:
-
高性能哈希表:
针对部分数据量较少、读请求很高的数据,FeatureKV 可以用 MemTable 这一个全内存的表结构来提供服务。Memtable 底层实现是一个我们自己实现的只读哈希表,在 16 线程并发访问的时候可以达到 2800w 的 QPS,已经超过了 rpc 框架的性能,不会成为整个系统瓶颈。
-
libco aio:
针对部分数据量较大、读请求要求较低的数据,FeatureKV 可以用 BlkTable 或 IdxTable 这两种表结构来提供服务,这两表结构会把数据存放在 SSD 中。而 SSD 的读性能需要通过多路并发访问才能完全发挥。在线服务不可能开太多的线程,操作系统的调度是有开销的。这里我们利用了 libco 中对 linux aio 的封装,实现了协程级的多路并发读盘,经过压测在 value_size 是 100Byte 的情况下,TS80A 上 4 块 SSD 盘可以达到 150w+/s 的QPS。
-
数据包序列化:
在 perf 调优的过程中,我们发现 batch_size 较大的情况下(ctrfeaturekv 的平均 batch_size 是 4k+),rpc 数据包的序列化时耗时会较大,所以这里我们自己做了一层序列化/反序列化,rpc 层的参数是一段二进制 buffer。
-
数据压缩:
不同业务对数据压缩的需求是不一样的,在存储模型的场景,value 会是一段浮点数/浮点数数组,表示一些非 0. 特征。这时候如果用 snappy 这类明文压缩算法,效果就不太好了,压缩比不高而且浪费 cpu。针对这类场景,我们引入了半精度浮点数(由 kimmyzhang 的 sage 库提供)来做传输阶段的数据压缩,降低带宽成本。
2. 分布式事务 BatchGet 的实现
-
MVCC: 多版本并发控制,具体实现就是 LevelDB 这样的存储引擎,保存多版本的数据,可以通过 snapshot 控制数据的生命周期,以及访问指定版本的数据。这种方案的数据结构需要同时支持读写操作,后台也得有线程通过清理过期的数据,要支持全量更新也是比较复杂。
-
COW: 写时复制,具体的实现就是双 Buffer 切换,具体到FeatureKV的场景,增量更新还需要把上一个版本的数据拷贝一份,再加上增量的数据。这种方案的好处是可以设计一个生成后只读的数据结构,只读的数据结构可以有更高的性能,缺点是需要双倍的空间开销。
RoleNum>1 的情况:

-
数据分布在不同机器,而不同机器完成数据加载的时间点不一样,从分布式的角度去看,可能没有一个统一的版本。
-
一个直观的想法,就是保存最近N份版本,然后选出每个 Role 都有的、最新的一份版本。
-
N 的取值会影响存储资源(内存、磁盘)的开销,最少是2。为了达到这个目的,我们在 DataSvr 侧加入了这么两个限制:

拥有全局统一的版本之后,事务 BatchGet 应该怎么实现呢?
-
先发一轮 rpc 询问各 role 的版本情况?这样做会让QPS翻倍,并且下一时刻那台机可能就发生数据更新了。
-
数据更新、版本变动其实是很低频的,大部分时刻都是返回最新一个版本就行了,并且可以在回包的时候带上 B-Version (即另外一个 Buffer 的版本),让 client 端在出现版本不一致的时候,可以选出一个全局统一的版本 SyncVersion,再对不是 SyncVersion 的数据进行重试。
-
在数据更新的时候,数据不一致的持续时间可能是分钟级的,这种做法会带来一波波的重试请求,影响系统的稳定性。所以我们还做了一个优化就是缓存下这个 SyncVersion ,每次 BatchGet 的时候,如果有 SyncVersion 缓存,则直接拉取 SyncVersion 这个版本的数据。
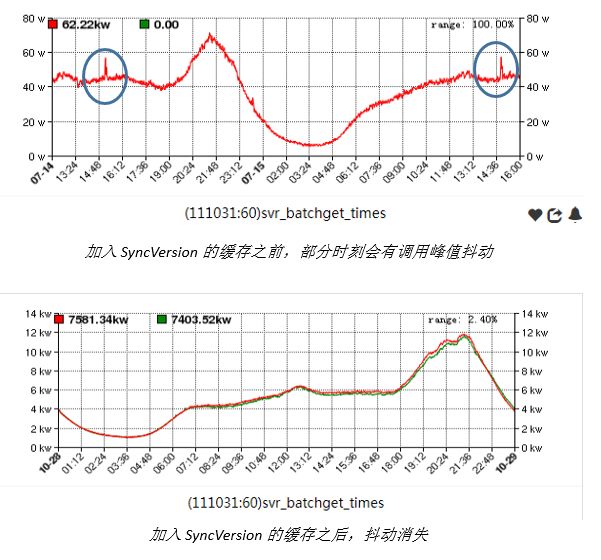
3. 版本回退
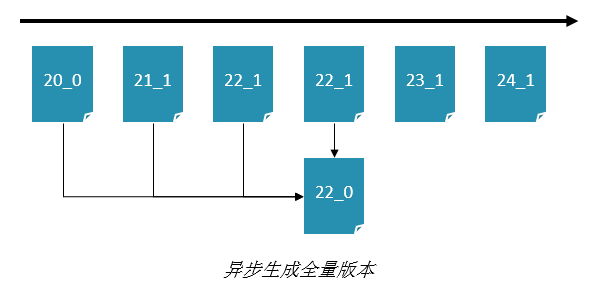
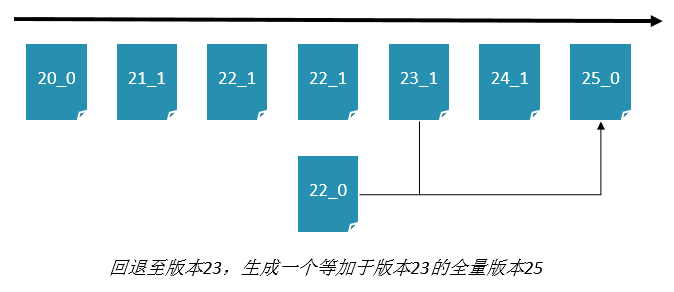
十亿每小时的挑战 离线写流程的具体设计
1. 背景
2. 单机的 DataSvr








