图:pixabay
原文来源
:arxiv
作者:Wei-Han Lee、Jorge Ortiz、Bongjun Ko、Ruby Lee
「雷克世界」编译:嗯~是阿童木呀
大家都知道,近年来,物联网(IoT)的应用越来越受欢迎,其应用范围从构建能源监控到个人健康追踪和活动识别。为了利用这些数据,自动知识提取(automatic knowledge extraction)必须按比例进行。因此,我们可以看到,最近很多物联网数据集都包含一个人类专家指定状态的注释,记录为数据序列中的一组边界和相关标注。这些数据可以用来构建自动标注算法(automatic labeling algorithms),从而可以像专家一样生成标注。在这里,我们将人为指定的边界称为
breakpoints
(断点)。传统的变点检测(changepoint detection)方法只能查找统计学意义上可检测的边界,其中,这些边界被定义为数据序列的生成参数中的突变。然而,我们观察到断点往往出现在更细微的边界上,而用这些统计方法对其进行检测的效果并不是很好。在这项研究中,我们提出了一种新的,基于深度学习的无监督方法,它在性能表现上要优于现有的技术,并且能够以较高的精确度学习更微妙的断点边界。对各种真实的数据集(包括人类活动感知数据、语音信号和脑电图(EEG)活动轨迹)进行粗略的广泛实验,我们证明了我们所提出算法在实际应用中的有效性。此外,研究结果表明,我们的方法较之以往的方法具有更显著的有效性。
变点检测是时间序列数据分析中所使用的一项重要的基本技术。它已经被广泛应用于分析股票数据、物联网(IoT)部署中的传感器数据、生理数据、以及许多其他的数据。变点检测对于发现不同的值序列是如何与过程中的状态相关联的,具有至关重要的作用,其中,该过程是不可直接观察的。通过检查变点,分析人员可以构建这些序列的模型,或者在多个数据集中查找序列的模式。变点检测是构建状态空间过程模型的基本原理。
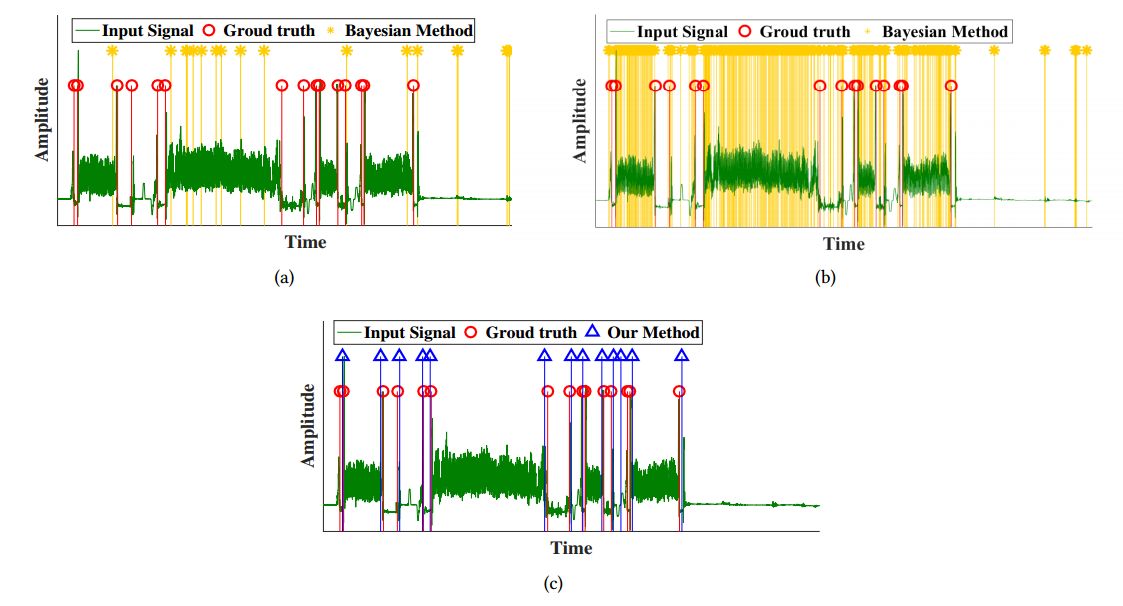
在不同的方法下使用智能手机传感器数据集进行活动识别的性能表现。绿线表示原始信号,红圈线表示断点的参照标准。(a)和(b)中的黄色星线分别表示使用现有具有伽玛和高斯先验分布的贝叶斯方法所检测到的断点。(c)中的蓝色三角形线代表使用我们的方法所检测到的断点。我们可以看到,我们的方法在寻找实际应用的断点方面要明显优于以前的方法。
随着可用数据量的增长,我们观察到,其中很大一部分现在是由领域专家所提供的人为标注进行注释的。这些标注对建模潜在状态和状态转换序列是很有用的。通过检查带有注释数据中指定状态的时间边界,分析人员可以寻找类似的转换模式,并提供更复杂的模型以捕捉这些状态之间的关系。例如,许多物联网移动电话应用程序可以使用内置传感器推断用户的活动。为了训练这些模型,用户必须提供关于他们活动的相关信息。这些信息被记录为数据中具有开始时间和结束时间的注释。同样地,专家花费大量的时间使用标注对心电图(ECG)数据进行注释,从而将追踪的轨迹标记为患者的各种心脏状态。
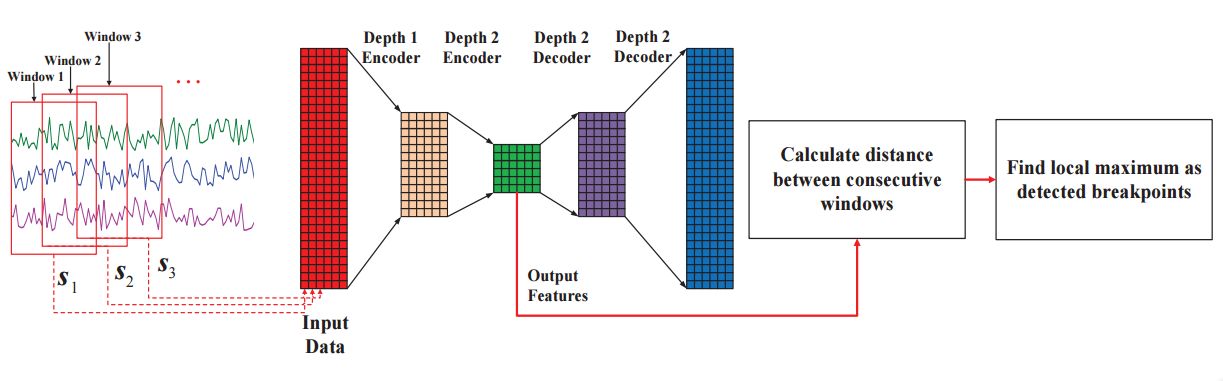
我们的断点检测系统的管道
变点是数据序列趋势的突然变化。贝叶斯技术通过查找生成序列的分布式参数的变化发现了这一点。考虑到这个问题的普遍性,文献中有很多涉及该问题的相关技术。该技术试图通过一个预先确定的模型捕捉生成过程,目的是寻找生成过程中参数的变化。在学习专家指定的边界方面,这些模型都失败了——因为使用生成过程预先指定的模型很难捕获这些变化,并且变点通常不会沿着参数移位边界产生。
当状态转换是预先指定模型底层过程中的潜时间属性的函数时,由专家指定的转换点出现,其中,这些属性很难在预先指定的模型中进行捕获。这些规则被编码为这些轨迹中的潜在特征,并且实际上来说,几乎不可能使用现有的基于生成模型的变点检测算法对其进行检测。我们观察到,现有的方法在识别人为指定的变点方面做得很差。综上所述,现有的变点检测方法存在两个主要缺陷:(1)依赖于时间序列数据的先验参数模型;(2)它们往往使用的是从输入数据中提取的简单特征,如均值、方差、频谱等。因此,以前的方法只能发现统计学意义上可检测的边界。为了区别于这些统计学意义上可检测的变点,我们在此处将由人为指定的变点称为断点。此外,我们提出了一种新的算法,使用深度学习技术对断点进行检测,而无需事先假设生成过程。我们的方法能够自动学习最有用的特征以表示输入数据,从而可以发现真实时间序列数据中的隐藏结构。需要注意的是,我们的方法在通用变点检测方面具有广泛的适用性,即使是超出此应用,在像本文所描述的断点检测中,它也有着广泛的适用性。
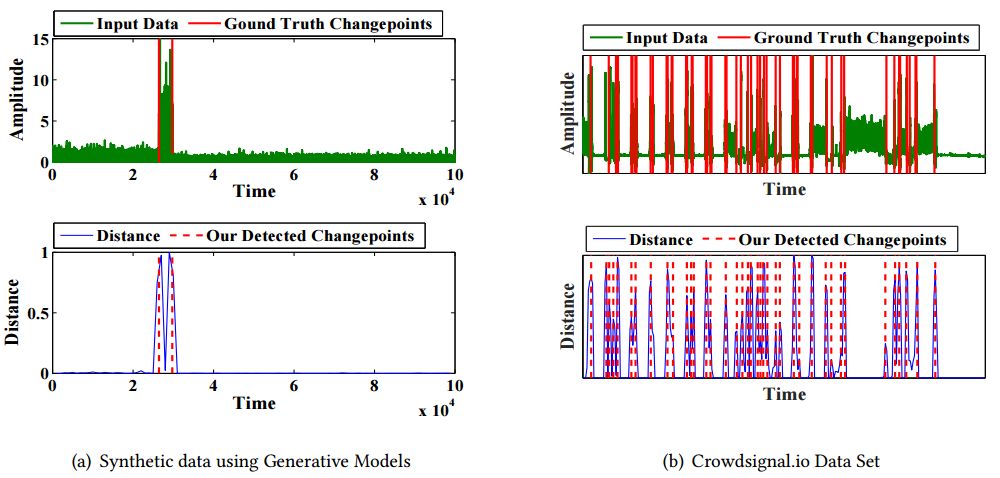
在一个由生成式模型和真实Crowdsignal.io数据集产生的合成数据上,使用我们的方法进行的实验。上面的数字显示原始输入信号(显示为绿线),而变点的参照标准显示为红线。底部的数字显示了两个连续时间窗口中特征之间的距离(如蓝线所示),检测到的变点显示为红色的虚线。我们可以看到,我们的方法在检测统计学意义上可检测的变点(使用合成数据)以及人为指定的断点(使用真实的Crowdsignal.io数据)方面是有效的。
在上文中,图1显示了在使用智能手机传感器数据集进行活动检测过程中,我们的方法与贝叶斯变点检测技术的比较。需要注意的是,在贝叶斯变点检测技术中,即使对参数进行仔细的调优后,该方法仍然不能准确地检测这些断点边界。此外,该技术对参数变化很敏感,人们可以轻易地就将断点的数量估计的过高或过低。此外,我们还并不清楚该如何调整参数以捕获真实分段的统计属性。相比之下,我们的方法能够自动学习这些属性。我们将通过从直观观察和分析真实轨迹学习到的一套简单的启发式,来解释我们是如何选择模型的超参数的。
总之,我们做出了如下贡献:
•我们引入一种称为
breakpoints
(断点)的新型变点,并标明几乎不可能用现有的变点检测技术对其进行检测。
•我们提出了一种全新的方法,它能够利用深度学习来自动学习有用的特征,而这些特征代表了专家指定的序列片段所生成的数据序列。相较于以往的方法,我们的技术并不依赖于假定变点是由生成过程中的参数的突然变化引起的,从而使其对于实际应用有着广泛的适用性。
•我们通过使用多个真实数据集进行了广泛的实验分析,证明了我们方法的有效性。此外,我们还展示了该如何从数据的统计属性与模型性能之间的关联启发式中选择模型的超参数。经实验分析表明,我们的方法可以作为实际应用的关键推动力。
•此外,我们将我们的方法与几种现有的方法进行了比较,并引入一个新的度量标准,用于衡量在预测变点数量的精确度及其与真实变点坐标的重叠方面,变点检测方案的有效性。实验结果表明,我相较于现有方法,我们的方法具有显著的优势。
在本文中,我们提出了一种检测人为指定断点的新方法,它利用深度学习技术自动提取特征值,从而可以很好地表示输入时间序列数据的特征。值得注意的是,我们的方法在通用的变点检测技术方面是很有效的,除此之外,即使是在本文所考虑的断点检测的背景下也具有很好的适用性。与以往方法不同的是,我们的方法不依赖于指定输入数据的先验生成模型。此外,我们通过对窗口大小、codebook码本大小以及网络深度进行仔细的敏感性分析,引入了一个简单的超参数调优标准。对包括人类活动感知、语音和脑电图轨迹在内的多种真实数据集进行粗略的广泛实验,证明了我们所提出的方法的有效性,并表明它显著优于现有的方法。我们的技术可以作为分析一系列广泛的真实时间序列数据的关键原语。
原文链接:
https://arxiv.org/pdf/1801.05394.pdf
欢迎个人分享,媒体转载请后台回复「转载」获得授权,微信搜索「ROBO_AI」关注公众号
中国人工智能产业创新联盟于2017年6月21日成立,超200家成员共推AI发展,相关动态:
中新网:
中国人工智能产业创新联盟成立





