
左边是原图,右边是修图。是不是觉得美女与右边图片的背景搭在一起,更有动感和帅气。可是不会修图啊,肿么办?
今天让我们来看一个有意思的AI应用,让不会PS的你,也能立马拥有吊炸天的修图超能力,没准还能分分钟修完上万张图,秒杀所有PS修图大神。
以下是机器学习大神Gidi Shperber讲述,他是到底一步步把这个模型给搞出来的详细过程。你要不要自己也来训练一个呢?
作者 | Gidi Shperber
编译 | AI科技大本营(rgznai100)
在机器学习领域摸爬滚打的这几年中,我一直想开发一个实用的机器学习产品。
几个月前,我学完了 Fast.AI深度学习课程,期待已久的机会终于闪现在我眼前:深度学习技术近几年突飞猛进,许多之前无法实现的事情现在也有了实现的可能。新的工具开发成功后,应用的实现变得比以往更加容易。
在学习Fast.AI课程期间,我遇到了经验丰富的网站开发者Alon Burg。我俩一拍即合,决定一起追求这一目标。因此,我们一起设定了以下小目标:
提高我们在深度学习上的能力
提升我们的AI产品应用能力
开发一个有市场需求的使用产品
(让我们和我们的用户)享受到乐趣
分享我们的经验
鉴于以上目标,我们开发的产品需要满足以下要求:
别人还没开发出来(或者别人开发的不够好)
计划和实现起来不是很难——我们计划在2-3个月内完成,每周工作一天。
用户界面简单有趣——我们想开发一个既有演示作用又有实用价值的产品。
要求的训练数据能轻易获得——机器学习从业人员都知道,数据有时候要比算法贵很多。
使用先进的机器学习算法(谷歌、亚马逊等公司仍未在其云平台上提供的),但不要太过先进(这样我们就还能在网上找到一些实例)
有实现“生产就绪”的潜力。
我们早期的想法是从一些医疗项目下手,因为这个领域深得人心,我们(仍然)感觉深度学习在医疗领域有很多容易实现的应用。但是,我们意识到我们会在数据采集和法律及法规方面遇到一些问题,解决起来不会很容易。
这样背景移除产品就成了我们的第二选择。
如果使用某种“标识”和边缘识别工具,手动完成或半手动完成背景移除任务就相当容易 。但是,全自动背景移除却极具挑战。据我们所知,有人做过尝试,但是现在还没有哪个产品能够得出令人满意的结果。
我们要移除什么样的背景?这是个很重要的问题,因为模型在目标、角度等元素上针对性越强,背景分离质量就越好。在刚开始时,我们的野心很大:目标是开发出一个可以自动识别前景(foreground)和背景的通用背景移除模型。但是在训练了第一个模型后,我们发现最好还是将工作集中在某一系列的图像上。因此,我们决定专攻自拍和人类肖像。

(类)人类肖像背景移除
自拍图像有一个既明显又明确地前景(一个或多个“主角”),这样我们就能很好地将对象(脸部和上身)和背景分离开来。此类图像往往角度单一,显示的对象也相同(人)。
有了这些假设,我们开始进行研究、实现以及长达数小时的训练,以期做出一个简单易用的背景移除产品。
虽然我们的主要工作是训练模型,但是我们不能低估正确实现的重要性。好的背景分离模型仍然不像分类模型那样结构紧凑,我们积极研究了产品在服务器和浏览器上的应用。
如果您想了解更多关于产品实现的内容,欢迎查看我们在server side和 client side上发表的文章。
如果您想了解该模型及其训练过程,请继续阅读。
在研究与本任务类似的深度学习和计算机视觉任务时,我们很快发现最好的策略是语义分割。
就我们的目的而言,其他策略(如通过深度检测实现分割)好像不够成熟,例如通过深度检测实现背景分离。
除了分类和目标检测,众所周知的计算机视觉任务还有语义分割。从像素分类的角度来看,语义分割实际上是一个分类任务。不同于图像分类或图像检测,语义分割模型在一定程度上能够“理解”图像,它不只能检测出“图像中有一只猫”,而且还能在像素级别上指出这只猫的品种以及它在图像中的位置。
语义分割模型的工作原理是什么?为了得到答案,我们研究了该领域的一些早期成果。
我们最早的想法是采用早期的分类网络,如VGG和Alexnet。回溯到2014年,VGG是当时最先进的图像分类模型,而且VGG结构简单易懂,时至今日仍十分有用。当观察VGG较浅的层时,可以看到要进行分类的对象周围聚集有激活单元,而且层越深上面的激活单元就越强。由于重复的pooling操作,VGG得出的结果在本质上比较粗糙。理解了这些,我们假设分类训练在经过一些调整后也可以用于搜寻/分割对象。
分类算法出现后,语义分割的早期成果也应运而生。这篇文章给出了一些使用VGG得出的粗糙的语义分割结果。
这篇文章
http://warmspringwinds.github.io/tensorflow/tf-slim/2016/11/22/upsampling-and-image-segmentation-with-tensorflow-and-tf-slim/

输入图像
靠后层的结果:
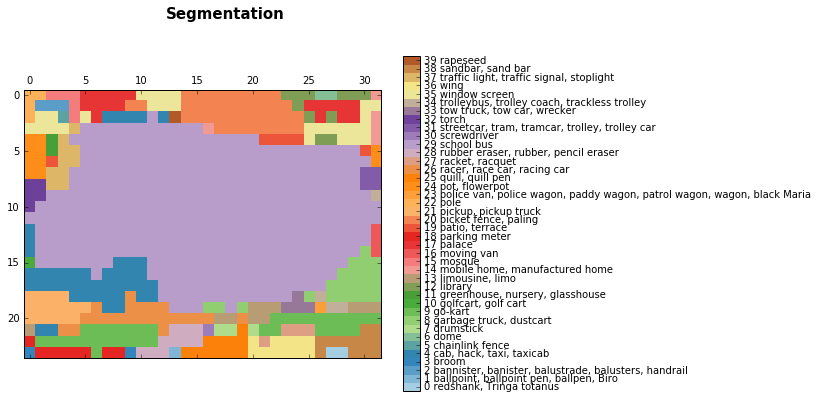
公共汽车图像分割,亮紫色(29)代表校车类别
在双线性升采样后:

这些结果是这样得来的:将全连接层转化为(或维持)它的原始形状,维持其空间特征不变,得出一个全卷积神经网络(FCN)。在上面的例子中,我们将一个768*1024的图像输入到VGG中,结果得到了一个24*32*1000的卷积层。24*32的图像是池化后的图像(1/32大小),1000是图像网络类别数,据此我们可以推导出上文中的语义分割。
为了让模型能顺利地进行预测,研究人员使用了一个简单的双线性升采样层(bilienar upsampling layer)。
在这篇FCN论文(https://arxiv.org/abs/1411.4038)中,研究人员改进了上述方法。为了解释得更详细,他们将一些层连接在一起,根据升采样率的不同将它们分别命名为FCN-32、FCN-16 和FCN-8。
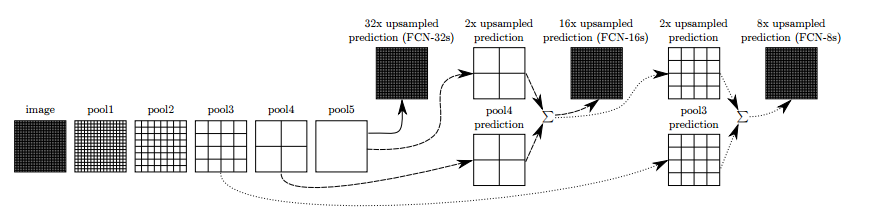
在层之间加一些skip connection,可以使预测模型对原始图像中更细微的细节进行编码。经过进一步训练,得出的结果会更好。
试验证明,这种方法的效果并不像想象的那样糟糕;而且利用深度学习完成语义分割任务的确有实现的可能。

图4. 通过整合不同步长的跨层信息来改善全卷积网络,改进分割细节。前三张图展示的分别是步长为32、16和8像素的网络的输出。
论文中得出的FCN 结果
FCN的提出揭示了语义分割的概念,为了解决这个任务研究人员尝试了很多不同的架构。从一些新的模型可以看出,他们的主要思路仍然类似:使用已知的架构,进行升采样,采用skip connection。
您可以通过阅读 文章1、 文章2 和文章3来了解该领域的一些进展。您会发现,大多数架构采用的仍然是编码器—解码器架构。
我们的项目
在做了一些研究工作后,我们最终确定了三个模型:FCN、Unet和Tiramisu 。这三个模型都是非常深的编码器—解码器架构,而且都能找得到。我们还有一些关于mask-RCNN的想法,但是这种模型的实现似乎不在我们项目涵盖的范围内。
由于FCN的结果不如我们预期的那样好(甚至不及格),因此暂不考虑这种模型。另外两种模型的结果则相对不错:tiramisu 在CamVid 数据集上表现良好;Unet的主要优点在于结构紧凑、速度快。在实现方面,Unet实现起来很简单(我们使用的是keras),Tiramisu 也能够成功实现。开始进行项目前,我们在Jeremy Howard的深度学习课程的最后一课中使用过一个很好的Tiramisu应用。
获取了两个模型(一个Unet和一个Tiramisu)后,我们用一些数据集对它们进行了训练。值得指出的是,第一次试验我们用的是Tiramisu模型,结果对我们而言很理想,因为它可以捕捉图像中的尖锐边缘。而Unet模型处理得似乎不够精细,得出的图像有点糊。

Unet 得出的结果有点糊
在确定了该使用哪种模型这个大方向后,我们开始寻找合适的数据集。语义分割数据不像分类数据或者检测数据那样常见。而且,手动标记并不可行。语义分割最常见的数据集是COCO(http://mscoco.org/)数据集(大约包含8万张图像,90种类别)、VOC pascal(http://host.robots.ox.ac.uk/pascal/VOC/%22)数据集(大约包含11000万张图像,20种类别)以及相对较新的ADE20K数据集。
我们选择使用COCO数据集训练模型,因为它包含更多“人”像,这正是我们感兴趣的一类图像。
针对任务,我们思考了是只使用相关性很强的图像,还是使用涵盖范围较广的数据集。一方面,涵盖范围较广的数据集往往包含更多的图像和类别,使用这种数据集的话,模型可以处理更多的场景和问题。另一方面,模型一整夜的训练图像数超过15万张。如果我们用整个COCO数据集训练模型,同一张图像模型最后(平均)会学习两次,因此稍微修剪一下数据集会有所帮助。另外,这样做的话我们还可以得到一个目标性更强的模型。
还有一个问题有必要指出——Tiramisu模型原本是用CamVid数据集训练的,这个数据集虽然存在一些弊端,但是最大的问题是它的图像千篇一律:所有图像都是在车内拍摄的路景图。很显然,学习这样的数据集(即使图像中有人)对我们的任务没有任何帮助。因此,我们只用该数据集完成了一个简短的试验。

CamVid数据集中的图像
COCO数据集支持非常简单的API,这使得我们可以知道目标在每张图像中的具体位置(根据预先设定的90个类别)。
在进行了一些试验后,我们决定对数据集进行稀释:首先我们过滤了只显示有一人的图像,这样就只留下了4万张。然后,我们剔除了所有显示有多个人的图像,留下只显示一人或两人的图像,此类图像就是我们的产品应该识别的对象。最后,我们只留下了20%-70%的内容都被标记为“人”的图像,剔除了那些显示有某种奇怪的巨物或者背景中有一个很小的人像的图像(可惜没有剔除掉所有此类图像)。最后,该数据集留下了11000张图像,我们感觉在这个阶段这么多就足够了。

左图:符合要求的图像 ___ 中图:人物过多___ 右图: 对象太小
如上文所述,我们曾在Jeremy Howard的课程中使用过Tiramisu模型。它的全名是“100层Tiramisu”,听起来像是一个很大的模型,但是它实际上很简洁,只有900万个参数。相比之下,VGG16的参数则多达1.3亿多。
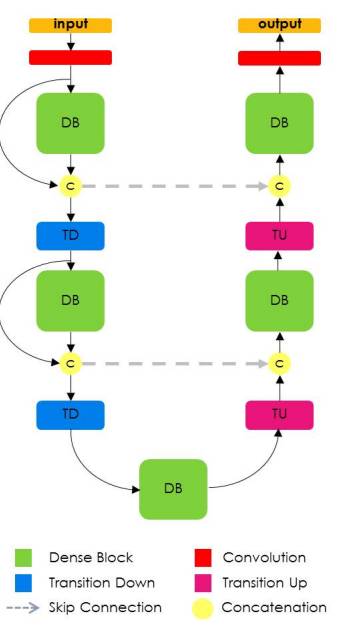
Tiramisu模型基于DensNet,后者是近期提出的一种所有层都是全连接层的图像分类模型。而且同Unet一样,Tiramisu也在升采样层上添加了一些skip connection。
这种架构与FCN论文中阐述的想法相契合:使用分类架构,升采样,添加skip connection以改善模型。
我们可以将DenseNet(https://arxiv.org/pdf/1608.06993.pdf%22)模型看作为Resnet模型的自然进化版,它记忆的是整个模型的所有层,而不是只在到达下一层之前“记忆”所有层。这些连接称为“highway connection”。这种连接会导致过滤器数量增加——定义为“增长率”(growth rate)。Tiramisu的增长率为16,因此我们在每层上都添加16个新的过滤器,直到抵达过滤器总数为1072个的层。您可能会说模型是100层tiramisu模型,那不就是1600层吗。但事实并不是这样,因为升采样层会损失一些过滤器。
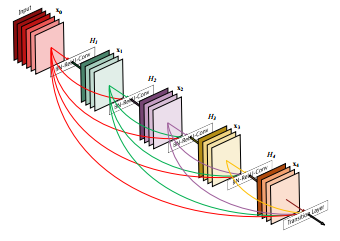
Densenet模型简图——模型前面层的过滤器堆叠在一起
我们按照原论文中阐述的训练安排训练我们的模型:标准交叉熵损失函数,学习率为1e-3而且衰减很小的RMSProp优化器。我们按比例这11000张图像分为训练图像(70%)、验证图像(20%)和测试图像(10%)。下文中的所有图像都来自于我们的测试数据集。
为了使我们的训练安排与原论文保持一致,我们将epoch大小设为500张图像。这样的话,用于训练模型的数据就更多(本文中所用的CamVid数据集包含的图像数少于1000张),我们可以通过改进结果周期性地改进模型。
另外,我们只使用了2个类别的训练图像:背景和人像,原论文使用了12个类别。起先我们用的是COCO的一些类别,但是却发现这对训练没有多大帮助。
某些数据集缺陷影响了结果:

动物、身体部位、手持物体

带物体的运动图像

原图像和(非常)粗糙的ground truth
我们的结果虽然令人满意,但还是不够完美:我们用测试数据集测试模型所得到的IOU值为84.6,而当前最优秀的模型的IoU值为85。这个数字很难统计,因为只要遇到不同的数据集和类别,它就会波动。有些类别本身较为容易分割,例如房屋、道路等,模型处理这些类别时的IOU值可以达到90。较难处理的类别则包括数和人类,模型在处理这些类别时的IOU值在60上行波动。为了限定困难程度,我们使模型只关注一个类别以及一定类型的图像。
我们仍然感觉我们的产品并未实现预期的“生产就绪”,但是我们认为这时候停下来讨论试验结果会更好,因为约50%的图像会得出好的结果。
以下是一些较好的实例,以便您了解我们App的性能:



原图像、Ground truth、我们的结果(来自于测试数据集)
调试是训练神经网络的一个很重要的环节。当刚开始进行工作时,很容易就会想直接获取数据和神经网络,开始训练,然后看看会得出什么样的结果。但是我们发现,追踪每步操作极其重要,这样做的话我们就可以对每一步的结果进行检查。
以下是一些常见的挑战以及我们的应对方法:
以下是一些通过调整参数和增加训练而对模型实现的一些改进:

保存目前为止的最佳验证IoU:(Keras提供了一个非常好的工具——callbacks-https://keras.io/callbacks/%22 ,用于简化工作)
callbacks = [keras.callbacks.ModelCheckpoint(hist_model, verbose=1,save_best_only =True, monitor= ’val_IOU_calc_loss’), plot_losses]
除了对可能的代码错误进行的常规调试,我们发现模型错误是“可以预测的”,比如“切割”不属于广义身体范畴的身体部位、大分割图像上的“缺口”、不必要的身体部位持续延伸、光线不好、质量差以及等等细节错误。有些错误在从不同数据集中提取特定图像时得到了处理,但是有些问题仍然未得到解决。为了改进下一版产品的结果,我们将专门针对模型“难处理”的图像使用数据增强 (Data Augmentation)法。
上文探讨了这个问题以及数据集问题,现在我们来看看我们的模型遇到的一些问题:

衣服和缺口

光线不足问题
进一步训练
在用训练数据完成了约300 epoch的训练后,我们得出了生产结果。在此阶段结束后,模型开始过度拟合。我们在发布产品前不久才得出了这些结果,因此我们还没机会应用基本的数据增强操作。
在将图像尺寸调整为224X224后,我们对模型进行了训练。使用更多的数据和更大的图像(COCO数据集图像的原始尺寸为600X1000)训练模型预计也可以改进结果。
CRF和其他增强
在有些阶段中,我们看到得出的图像在边缘有少许噪点。可以使用CRF模型解决这个问题。在这篇博文中(http://warmspringwinds.github.io/tensorflow/tf-slim/2016/12/18/image-segmentation-with-tensorflow-using-cnns-and-conditional-random-fields/),作者给出了CRF。但是,CRF对我们的工作帮助不大,也许是因为通常只有在结果较为粗糙时它才能有所帮助。
Matting
即使是我们现在得出的结果,其分割效果也不完美。我们永远也不能完美地分割头发、细致的衣服、树枝和其他精细的物体,就是因为ground truth分割图像不涵盖这些细节。分割此类细致分割图像的任务称为matting,这是一种不同的挑战。这是一个优秀matting方案的实例(https://news.developer.nvidia.com/ai-software-automatically-removes-the-background-from-images/),发表在今年上半年内的NVIDIA会刊上。
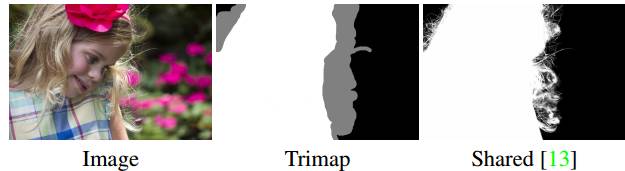
Matting 示例——输入图像也包含trimap
Matting任务不同于其他图像处理任务,因为它的输入不仅包含一张图像,还有一个trimap——图像边缘的轮廓线,这使matting任务成了一个“半监督”问题。
我们将分割图像作为trimap,进行了一些matting试验,但是得出的结果并不好。
还有一个问题时缺乏训练所需的合适数据集。
正如文章开头说的那样,我们的目标是开发一个有意义的深度学习产品。Alon在其文章中指出,机器学习的应用正变得越来越简单及快速。但是,模型训练却是一个棘手的问题——训练(尤其是夜间训练)时需要仔细地进行计划、调试和记录结果。
要想平衡研究和创新、训练与改进之间的关系也不容易。因为使用的是深度学习方法,我们总感觉最好的模型或者最适合我们的模型近在咫尺,也许谷歌再发布一项的研究或一篇论文,我们就能找到实现的方法。但是实际上,我们模型的改进实际上是从原始模型中一点一点地“挤出来”的。就像我上文所说的,我们仍然感觉进步的空间还很大。
原文地址
https://medium.com/towards-data-science/background-removal-with-deep-learning-c4f2104b3157?nsukey=HjVxf540wVOL13ThjgEVgqK6yTM0j%2BlZf%2B56cPoPdFCFk%2F6NrblQg0ftuvs82azzYzUhxR4SKluuDZW6Hpk5849qrjCLB8VJg0ULIGW9dHP0nuecErk37IqJ%2Ff3A%2Bip8DzhS1EkpoXYPded2mOJbdA%3D%3D

CSDN AI热衷分享 欢迎扫码关注










