雷锋字幕组获MIT课程团队授权翻译自动驾驶课程,视频链接:http://www.mooc.ai/course/483/info
我们为你整理了每一个 Lecture 的课程笔记,提炼出每一讲的要点精华,推荐结合课程笔记观看视频内容,学习效果更佳。
原标题 MIT 6.S094: Deep Learning for Self-Driving Cars 2018 Lecture 5 Notes: Deep Learning for Human Sensing
作者 | Sanyam Bhutani
翻译 | 陈涛、朱伟杰、Binpluto,、佟金广 整理 | 凡江

所有的图片皆来自课程中的幻灯片。
这次的课程将利用深度学习的方法来理解人类的感官功能。
其中研究的重点在于计算机视觉技术。
我们将了解到:如何使用计算机视觉技术,从拍摄于汽车场景下的视频中提取有用的信息。

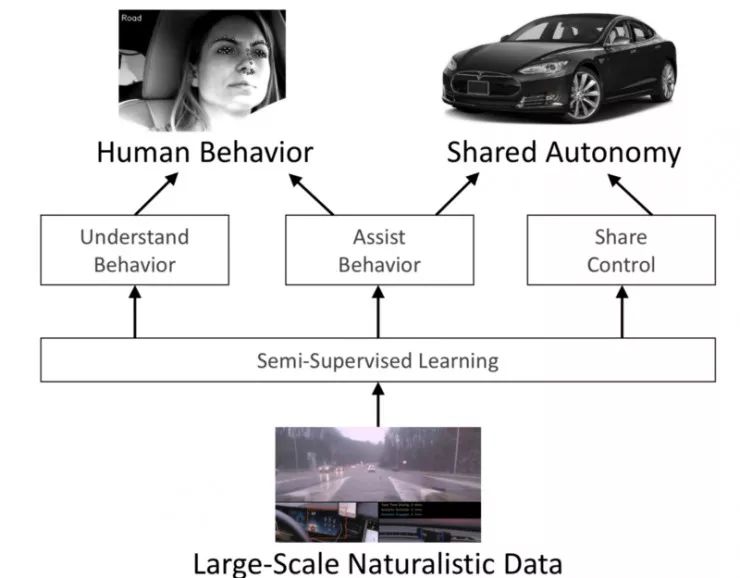
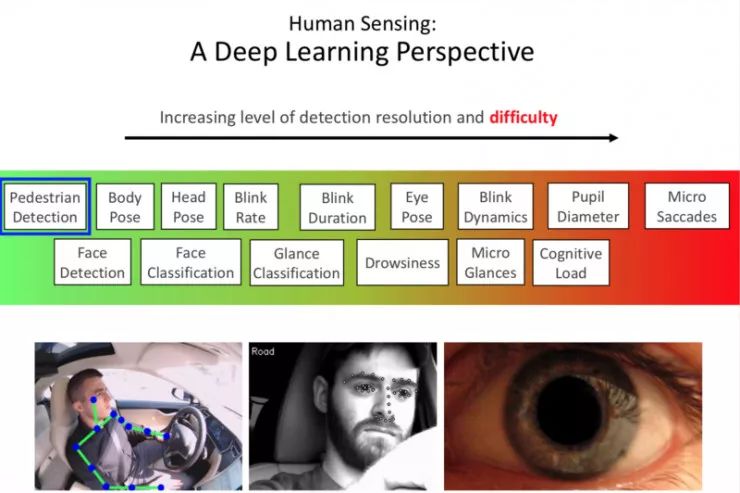
深度学习实现人类感知:
使用计算机视觉和深度学习的技术,创造可以在真实世界中发挥作用的系统。
达到此目的的要求是(按重要性排序):
我们需要大量的真实数据,其中数据收集是最困难且最重要的环节。
原始数据需要被归纳成有意义的、具有代表性的例子,这意味着原始数据需要被标注。
我们需要收集数据并采用半监督学习的技术,去找到其中可以被用来训练我们网络的数据。
良好的标注可以使模型表现出色。
对不同的场景,标注技术是完全不同的,比如:视线分类的标注、身体姿态估计的标注、SegFuse 比赛中图片像素级的标注。
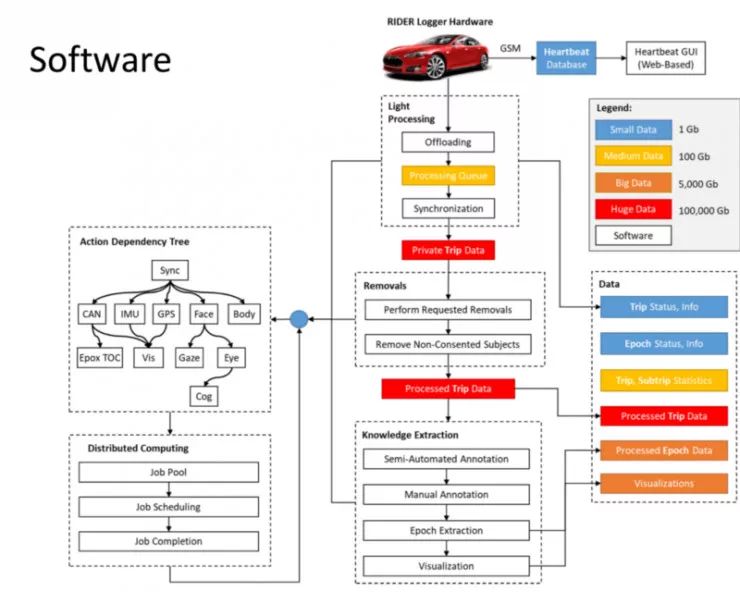
大批的数据需要得到大规模的分布式计算和存储。
我们希望算法能够自校准,从而得到泛化的效果。
目前深度学习中的算法都是基于单独的图像开发出来的,我们需要让算法能够处理一连串图像所组成的时间序列。
上述要求的重点是:数据收集及清理比算法本身更重要。
人类的缺点
2014 年,分心驾驶所引发的车祸导致 3179 人丧生,超过 431 万人受伤。
当你边开车边发消息时,平均每 5 秒钟,你的眼睛就会偏离路况。
在 2014 年中,30% 的交通死亡事件由酒驾造成。
在 2014 年中,23% 的夜间驾驶者都属于毒驾。
疲劳驾驶引发了 3% 的交通死亡事件。
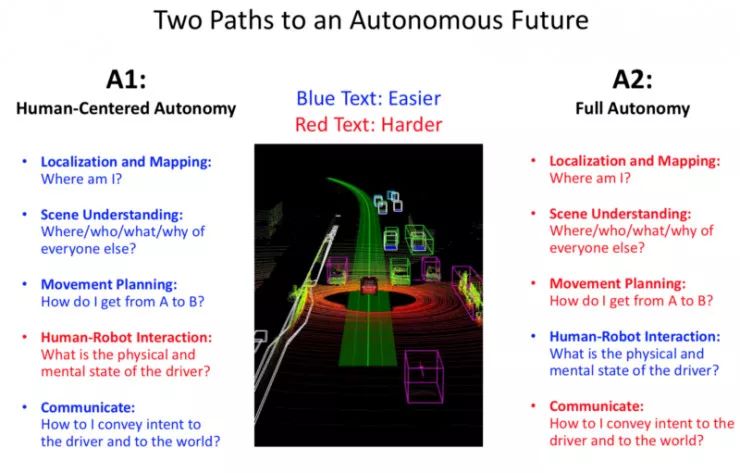
考虑到这些缺点,以及我们在前面课程中讨论过的未来实现自动化驾驶的两条路径(以人为中心的自动化和完全的自动化):
我们需要思考以人为中心的自动化驾驶的设想是否可行?



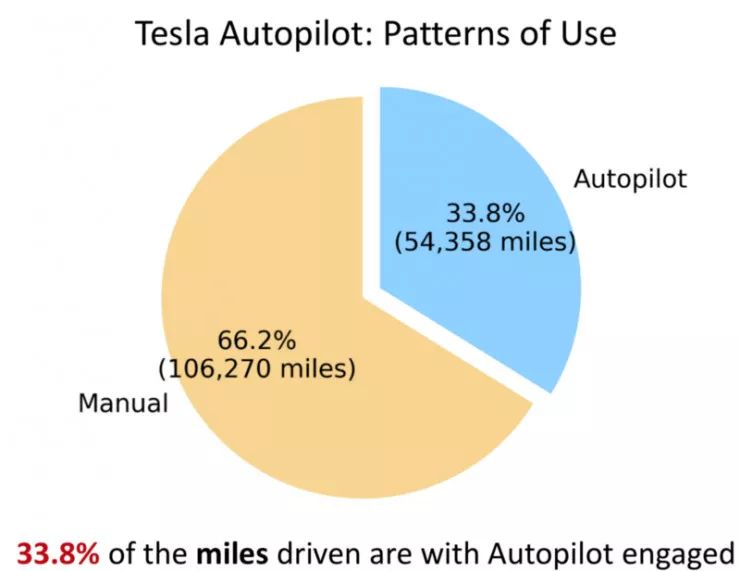
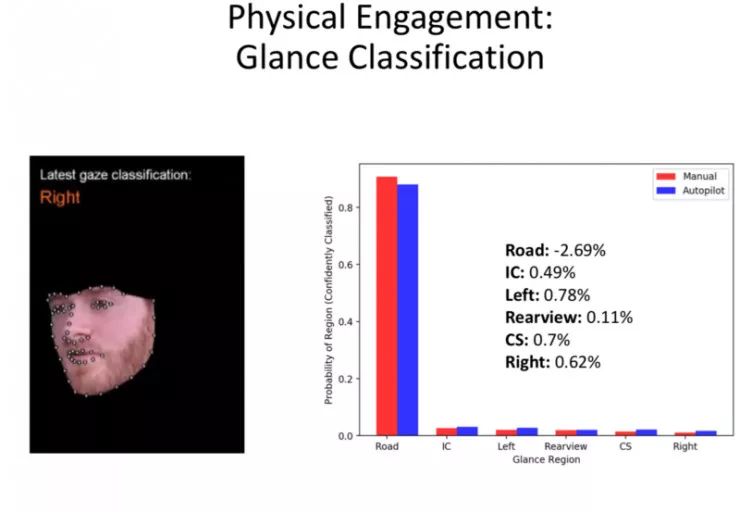
MIT-AVT 自然驾驶数据集

数据收集:
收集到的数据使得我们可以了解到如下信息:
安全性 Vs 针对自动驾驶的偏好
行人识别
面对的挑战:
-
不同的表现方式:类别内差异。
-
不同的清晰度。
-
造成视线遮挡的配饰。
-
行人间的互相遮蔽。
解决方案:
需求是从原始的像素图片中提取特征。
平滑移动图片:
更加智能化的网络:
-
快速区域卷积神经网络
-
薄膜区域卷积神经网络
-
Voxel 网络
这些网络生成的模型会被考虑用于整个方案的一个部分,而不是通过移动窗口的方式。
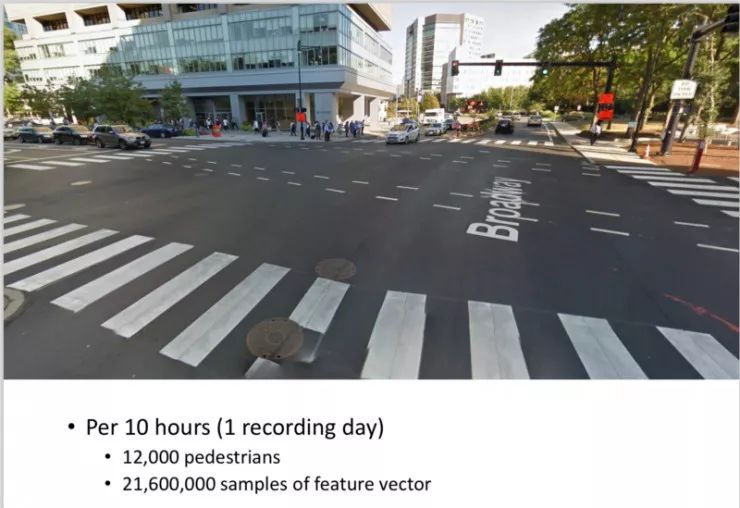

数据(从不同的交叉领域中得到的):
-
每天记录 10 个小时的数据量。
-
大约有 12000 个行人通过。
-
2100 万具有特征向量的采样数量。
-
区域卷积神经网络会对所有行人进行矩形区域的探测。
肢体姿势估计
内容包括:
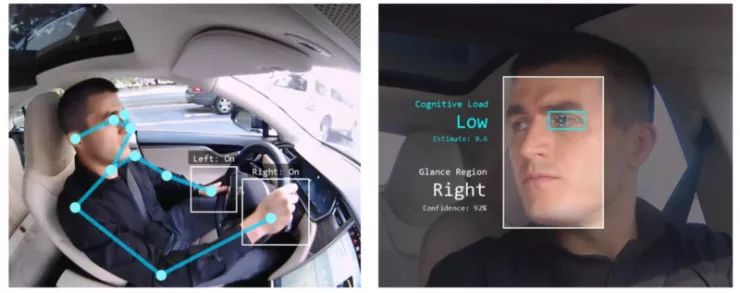
为什么它很重要?
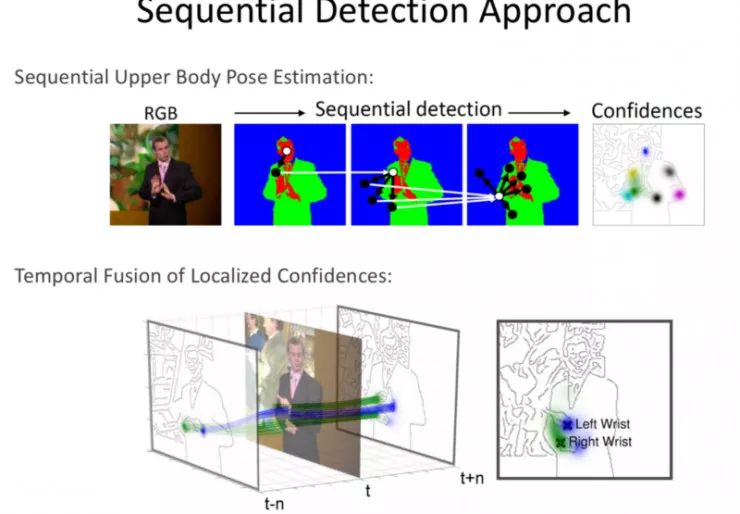
序列化探测法
-
先探测手,接下去是脚,然后是肩膀等等。
-
这是一种传统的方法。
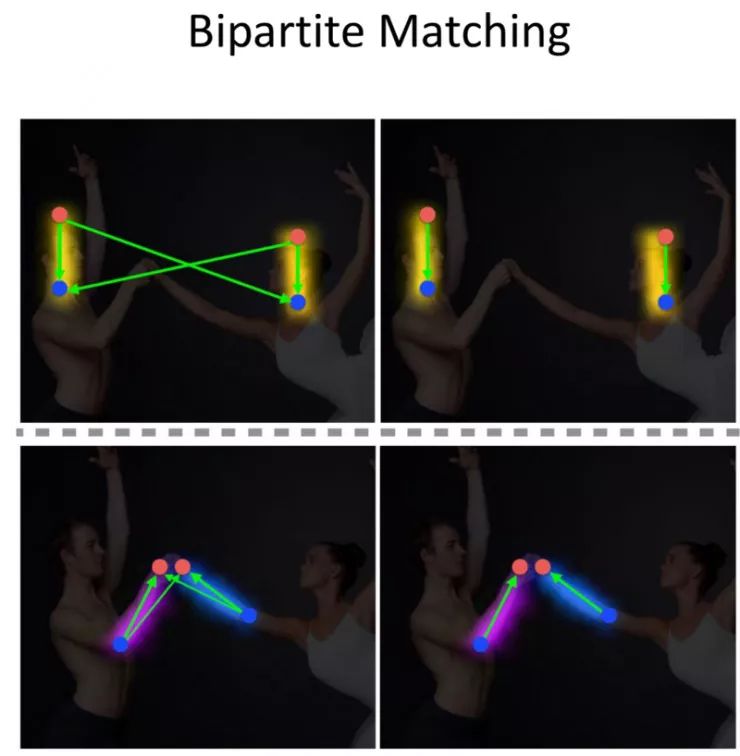
整体姿势洞悉:

级联姿态回归器:

身体部位探测法: