
作者:DataGirls 中国最智慧的女性科技社区等来撩

“被杰伦占据的青春,似乎很温暖,很有力量,很美好!仿佛回到了十几年前简单爱的夏天,用听英语的复读机播着他的歌,把歌词抄在日记本的最后一页,边抄边想着喜欢的女生,这种初恋般的幸福感只有周杰伦能给。时间似乎倒转回那个有七里香有园游会有简单爱有骑着山地车带着风的气息的少年,终于发现时间已经走了这么远。”
“如今我们很难再见面,但我们都还会听周杰伦的新歌。周杰伦是星晴,是园游会,是手写的从前,是告白气球。拥有你就拥有全世界。”
“老子梦想就是有个男生跟我一起看周杰伦演唱会,给我唱周式情歌。”
“原来一首歌里充满了过往记忆是这样的感受,很多时候都不敢听,前奏一起,瞬间就是泪点。”
“那些好听的情话,只想说给你听。你好,JAY”

网友们告白,每当那些年爱过的周杰伦的歌声响起,总是能唤回我们无限的回忆。9月24日周日下午,北京丹棱街微软大厦1层,DataGirls主办了数据可视化实操课“探索杰伦世界里那些不能说的秘密”,听说还有极客音乐才子现场演奏杰伦的经典歌曲,作为Jay的铁粉我是一定不能错过的。
果然一来到现场,独立音乐人,火柴救援队主唱兼吉他手陈岑正吉他弹唱周杰伦经典歌曲,高潮迭起。什么都不说了,先一起来重温回忆~

这次我们搜集了周杰伦生平的所有音乐作品和歌词,希望能对周杰伦的音乐生涯做一个很好的总结,并探索周杰伦歌词里面的秘密。现在来分析下他的歌词,看看是不是时常在你耳畔响起的那些。
从网易云音乐上下载Jay's songs,歌名,专辑名,作词人,作曲人,发布时间,单曲OR专辑,每个单曲的所有信息。
首先使用R语言对周杰伦歌词数据进行分词及添加词性信息处理,下载最新版R语言以及RStudio IDE工具,并安装install.packages(jiebaR)、 install.packages(jiebaRD)包,用library(jiebaRD)、library(jiebaR)加载包,并读取网上下载好的周杰伦所有专辑歌词.txt文件。
在分析文本的时候,需要首先构建分词器。worker()函数的作用是构建一个分词器,通常构建分词器的语句如下,不添加任何参数的话,使用函数中默认的参数。
worker(type="mix",dict =DICTPATH, hmm=HMMPATH, user=USERPATH, idf=IDFPATH, stop_word = STOPPATH, write = T, qmax = 20, topn = 5,encoding = "UTF-8", detect = T,symbol = F, lines = 1e+05,output = NULL, bylines = F, user_weight = "max")
worker()函数的参数介绍如下:
type(mix):分词模型,有好几个可选项:
1.mp 基于词典的最大概率模型。负责根据Trie树构建有向无环图和进行动态规划算法,是分词算法的核心。
2.hmm 基于HMM模型,可以发现词典中没有的词。隐式马尔科夫模型是根据基于人民日报等语料库构建的HMM模型来进行分词,主要算法思路是根据(B,E,M,S)四个状态来代表每个字的隐藏状态。HMM模型由dict/hmm_model.utf8提供。分词算法即viterbi算法。
3.mix 混合模型,先用mp分词,分完以后调用hmm把剩余的可能成词的单字拿出来。是四个分词引擎里面分词效果较好的类,结合使用最大概率法和隐式马尔科夫模型。
4.query 索引模型,对大于一定长度的词再进行一次切分。先使用混合模型进行切词,再对于切出来的较长的词,枚举句子中所有可能成词的情况,找出词库里存在。
5.tag 标记模型,基于用户词典的词性标注。
6.keywords 关键词模型,TF-IDF抽去关键词。
7.simhash Simhash模型,在关键词的基础上计算simhash。
dict(DICTPATH):系统词典,默认路径为jiebaR::DICTPATH,文件名为jieba.dict.utf8。系统词典的默认数据结构为三列:词语、词频、词性。
我们这里使用tag模型标记词性,并导出不同词性的分词结果:
这次我们还是使用Power Query插件对导出的基础数据进行处理。将R里导出的文本文件数据导入到Power Query中,展开分词列表,拆分字段列,替换、删除不必要信息及错误行及空行。
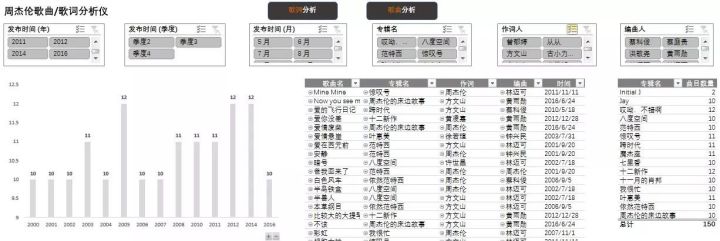
先做歌曲分析吧,柱形图及表格为数据透视图支持图表,直接与切片器关联以实现互动效果。
1. 用切片器选择观测范围
2. 用柱形图展现时间维度下发表歌曲数量情况
3. 用表格信息展示歌曲相关信息
4. 用表格信息展示专辑相关信息
再接着做歌词分析,使用名称定义连接切片器与组合图,直接连接切片器与词语信息透视表。
1. 用切片器选择观测范围
2. 用组合图展现词语出现次数比较情况
3. 用下拉列表选择所需要显示的词语数量
4. 用表格展示词语详细信息

最后用VBA代码实现不同显示内容间的切换功能,代码处理逻辑为显示需要展示内容所在的列以及隐藏不需要展示内容所在的列。
可以看到从2000年开始周杰伦平均每年至少会出一张专辑,每张专辑里有10-12首新歌,共150首歌曲,大都在下半年发布,御用作词人方文山为他写了82首歌词,远超作词第二多的黄俊郎,写了13首。每张专辑里至少有2首歌是自己作词,才女徐若瑄为她做了5首歌词。
作曲最多的是林迈可43首,其次是黄雨勋35首,曾经的御用作曲人钟兴民29首,还有18首歌是自己作曲,其中《爸我回来了》《借口》《可爱女人》《懦夫》《晴天》《梯田》《土耳其冰淇淋》《外婆》这8首词曲歌都是Jay创作哦。
歌词里面”我你都在说不爱是啦”这类代词等出现频率最多,出现最多的两字动词是”知道,不能,离开,不用,开始,回忆”,基本上是:我和你的一段伤感回忆。和你印象中的杰伦是不是一致呢,大家都动手试着自己做个吧。可分析的内容还有很多,比如最常用的中国风元素?最常提到的亲人等等。
原来数据分析还可以这样学,从小习惯了苦行僧试的应试教育,根深蒂固地认为学专业的知识要一本正经,原来有趣和有料并不矛盾,结合起来才是真正的快乐学习。希望DataGirls继续推出新的趣味分析课程,让我们认识大千世界的同时,也掌握数据分析思路和技巧。

公众号后台回复关键字即可学习
回复 R R语言快速入门免费视频
回复 统计 统计方法及其在R中的实现
回复 用户画像 民生银行客户画像搭建与应用
回复 大数据 大数据系列免费视频教程
回复 可视化 利用R语言做数据可视化
回复 数据挖掘 数据挖掘算法原理解释与应用
回复 机器学习 R&Python机器学习入门










