计算机视觉研究院专栏
作者:Edison_G

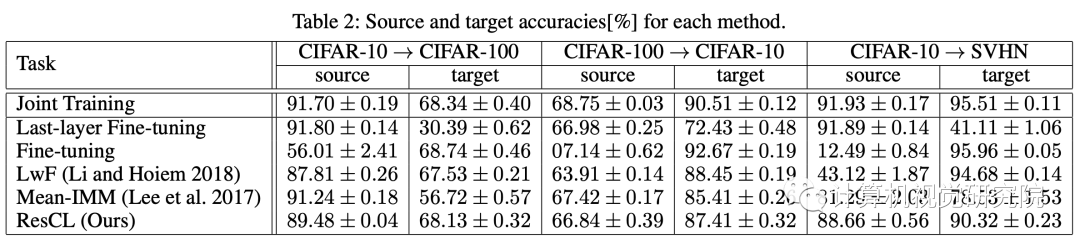
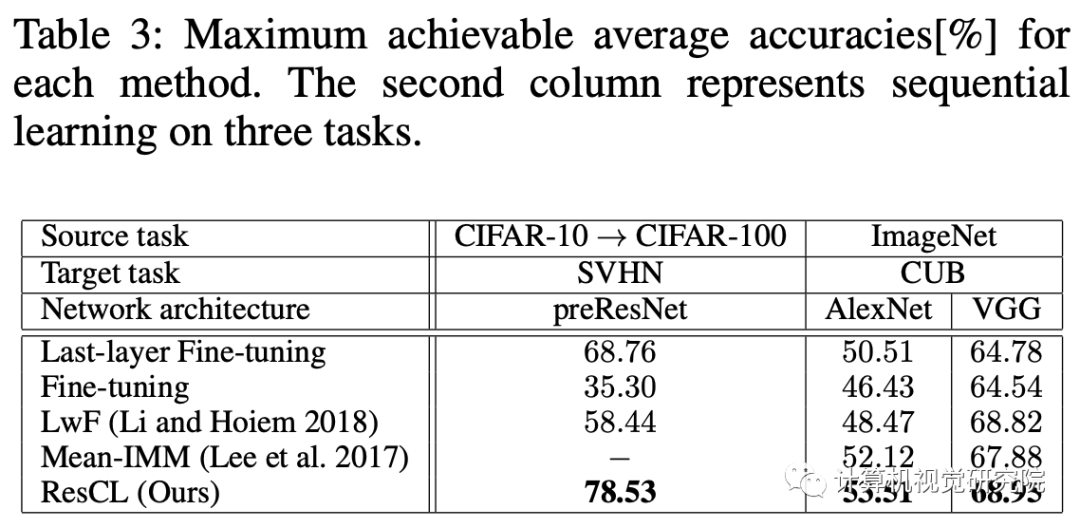
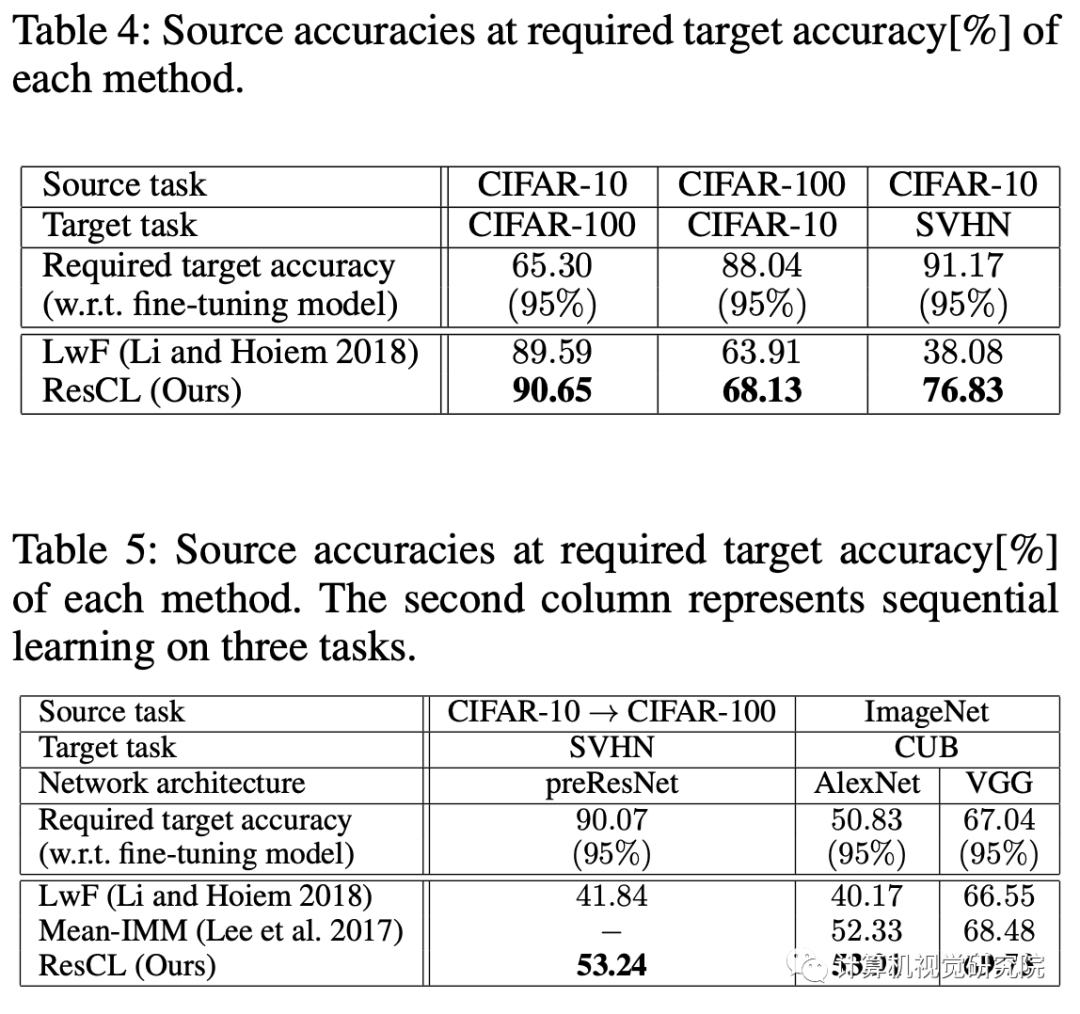
提出了一种新的连续学习方法,称为“Residual Continual Learning”(ResCL)。新提出的方法可以防止多个任务的顺序学习中的灾难性遗忘现象,除了原始网络之外,没有任何源任务信息。通过将原始网络的每一层和一个微调网络线性地结合起来,ResCL重新测量网络参数;因此,网络的大小根本不会增加。


为了将该方法应
用于
一般卷积神经网络,还考虑了批归一化层的影响。
通过利用类-残差学习再参数化和特殊的权重衰减,
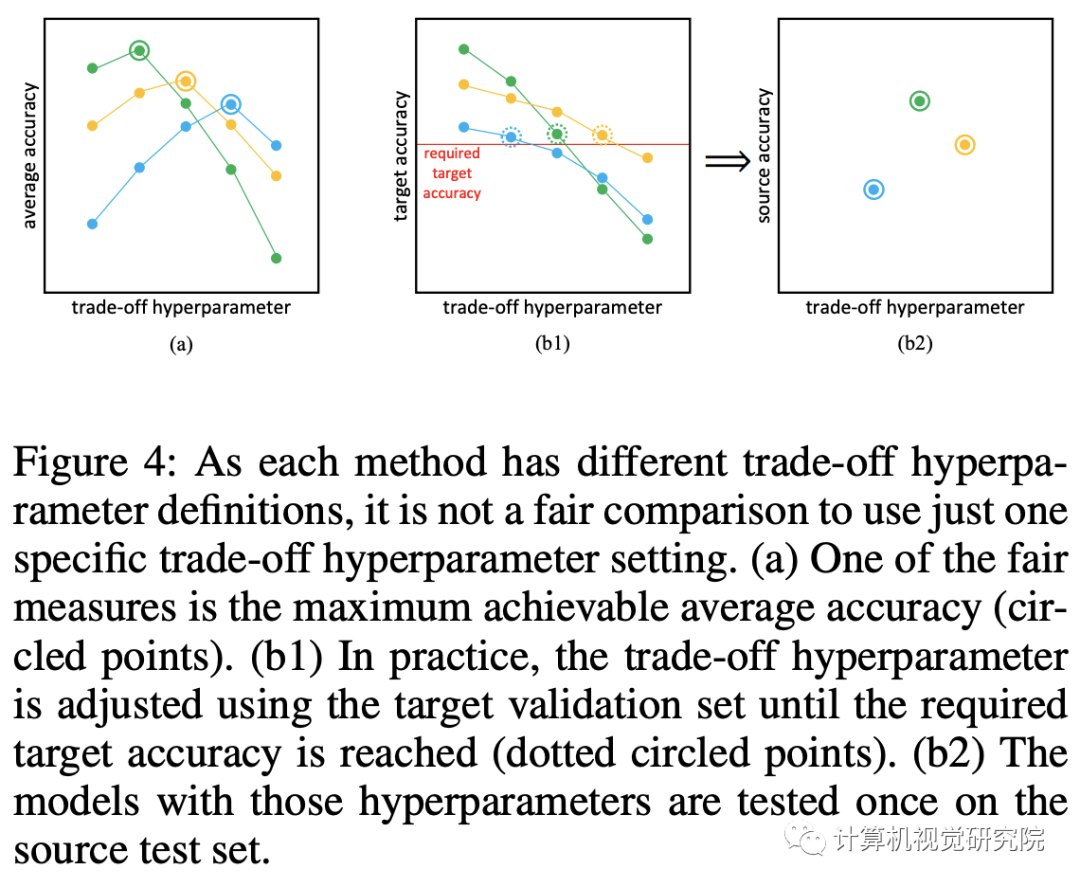
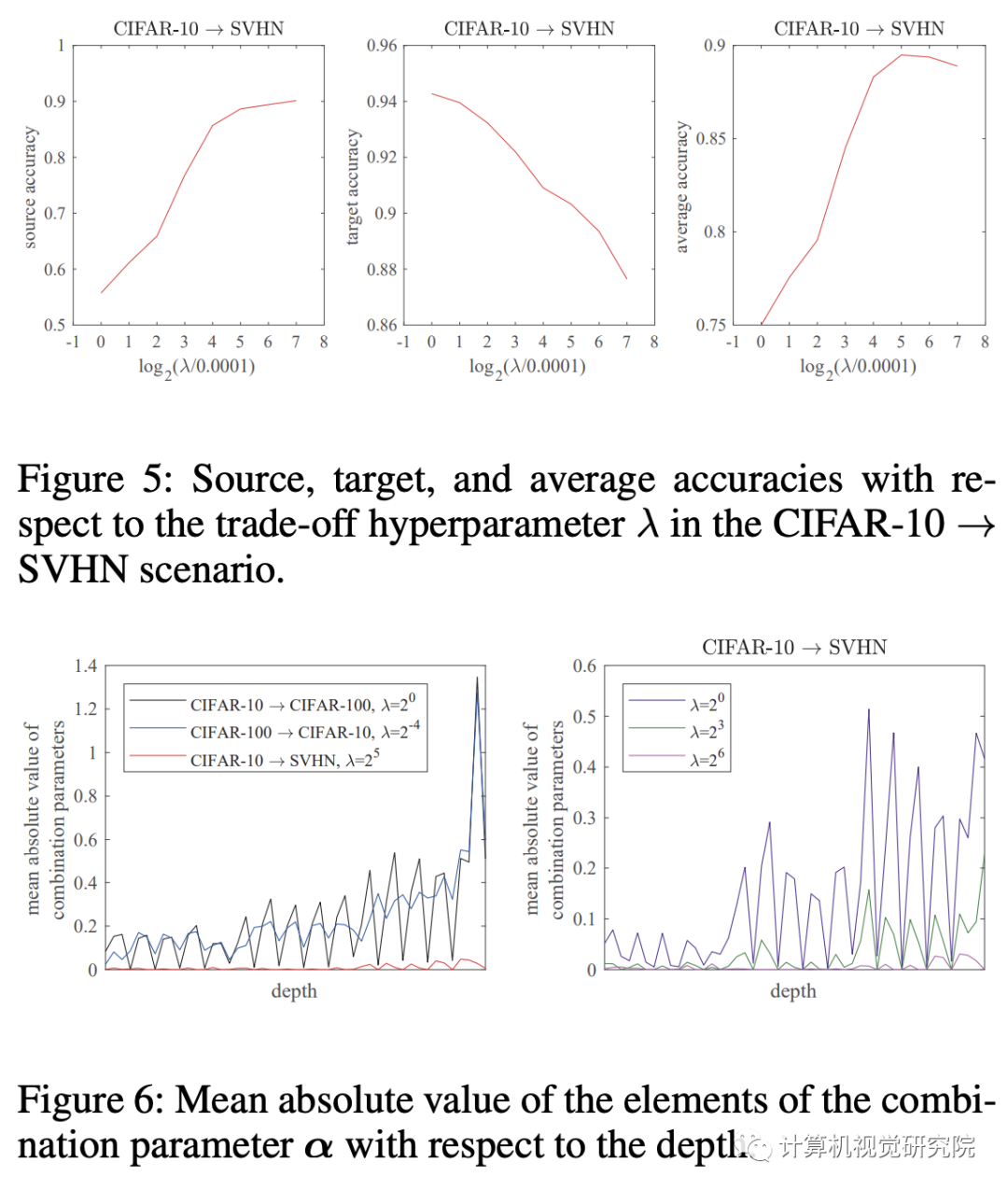
有效地控制了源性能与目标性能之间的权衡。
该方法在各种连续学习场景中表现出最先进的
性能。
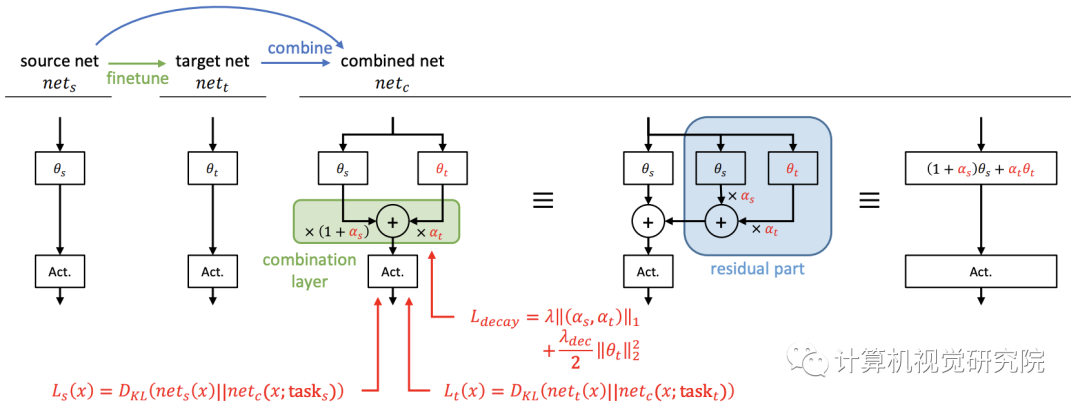
持续学习本质上是在两个任务之间达到一个很好的中点。一个简单的想法是将每一层源网络和目标网络线性地结合起来,以获得它们之间的中间网络,其中源网络是对源任务进行训练的原始网络,目标网络是从原始网络中为目标任务进行微调的网络。通过将它们结合起来,我们可以获得位于源和目标任务解决方案之间的网络。
这个基本思想类似于IMM,本次技术也从这里开始。然而,线性组合网络的性能没有得到保证,因为神经网络不是线性的或凸的。因此,在两个网络组合后,我们对组合网络有一个额外的训练阶段,以确保它能够正常工作。由于额外的训练会伤害源知识,所以在组合网络中应该冻结原始权重。在本文中,我们经常把源网络称为原始网络。
-
Linear Combination of Two Layers


在ResCL框架中,Ws是源网络的权重,Wt是
从原始网络中为目标任务进行微调的网络
权重,
此外,Wt还接受了训练,以完善其以便与Ws很好地结合起来,而Ws是固定的,以防止灾难性遗忘。
此外,还通过反向传播来学习组合参数,以最优地混合两个特征。
因此,组合网络中的可学习参数为Wt和α=(αs,αt)。
人们可以很容易地发现,两个全连接层和组合层可以等价地表示为一个全连接层,其权重是:

这就是为什么可以新提出的方法为一种类型的重新参数化;因此,一旦训练完成,网络的大小就不会增加用于推理。任何非线性层,如sigmiod或ReLU,不应包括在组合中,如上图和下图所示。 否则,这些层不能合并为一个层;然后,随着任务数量的增加,网络大小增加。
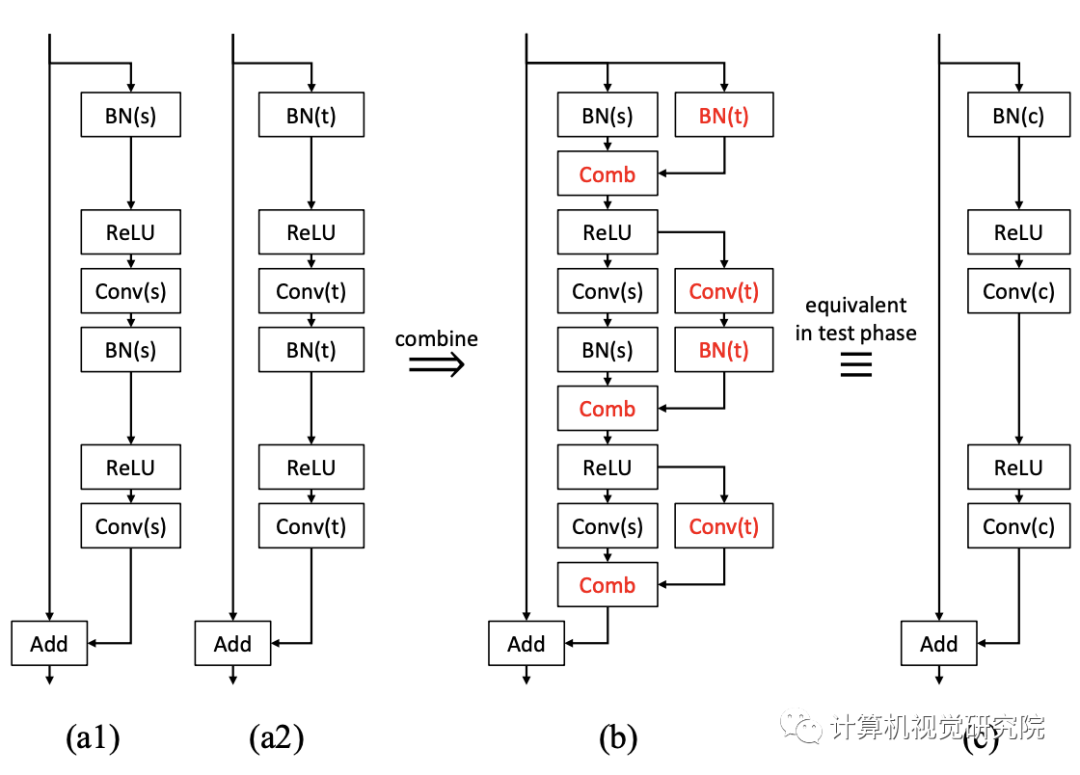

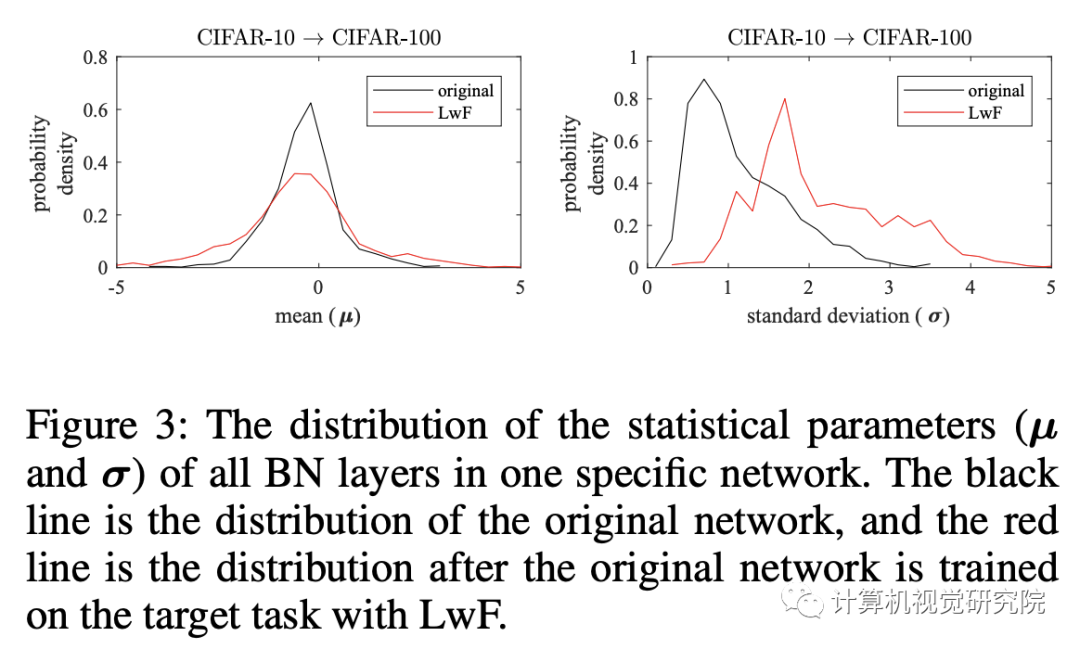
新提出的方法可以自然地应用于BN层。我们不需要担心分布的变化,因为每个子网都有自己的BN层来完成自己的任务。具体地,图中的原始BN层(下图的BN(s))应在额外的训练和测试阶段使用其源任务的人口统计。否则,一些源知识就会丢失,因为联合网络在额外的训练中无法看到和利用原始统计数据。具有组合层的两个BN和两个卷积层在训练后也可以合并成一个等效卷积层,因为BN层在推理阶段是确定性的线性层,卷积也是线性运算。

我们开创“
计算机视觉协会
”知识星球一年有余,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。