标题:Real-Time Dense Monocular SLAM with Neural Radiance Fields
作者:Rosinol, Antoni and Leonard, John J and Carlone, Luca
来源:arxiv
编译:张海晗
审核:zhh
代码:https://github.com/ToniRV/NeRF-SLAM
摘要
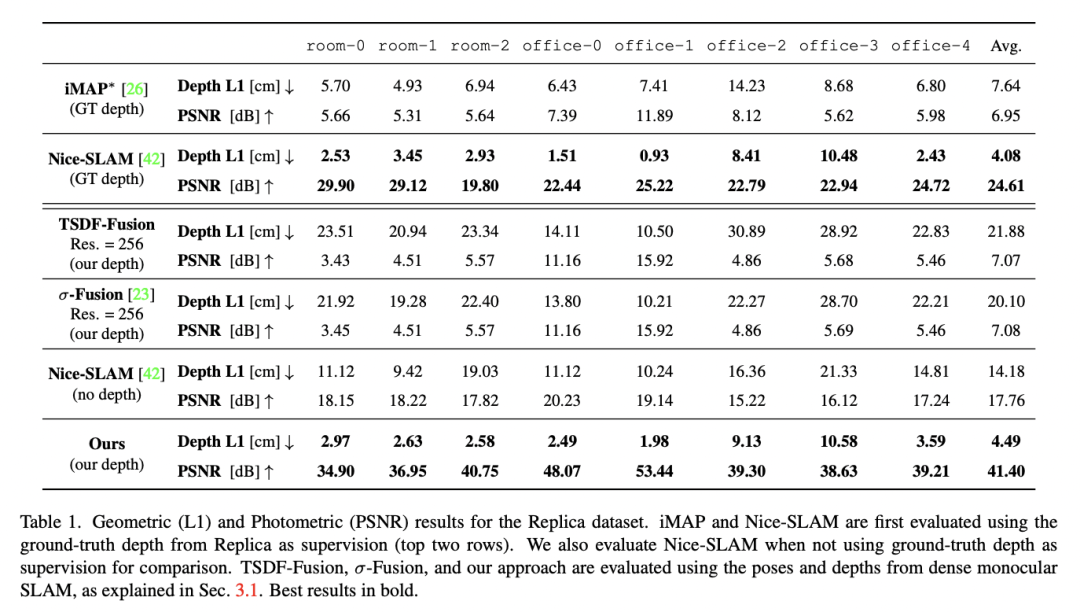
我们提出了一个新的几何和光度3D映射管道,用于从单眼图像中准确和实时地重建场景。为了实现这一目标,我们利用了最近在密集单眼SLAM和实时分层容积神经辐射场方面的进展。我们的见解是,密集的单眼SLAM通过提供准确的姿势估计和具有相关不确定性的深度图,为实时适应场景的神经辐射场提供了正确的信息。通过我们提出的基于不确定性的深度损失,我们不仅实现了良好的光度测量精度,还实现了巨大的几何精度。事实上,我们提出的管道比竞争对手的方法实现了更好的几何和光度测量精度(PSNR提高了179%,L1深度提高了86%),同时实时工作并只使用单眼图像。
主要贡献
我们提出了第一个结合密集单眼SLAM和分层体积神经辐射场优点的场景重建管道。
我们的方法从图像流中建立精确的辐射场,不需要姿势或深度作为输入,并且可以实时运行。
我们在Replica数据集上实现了单眼方法的最先进性能。
主要方法
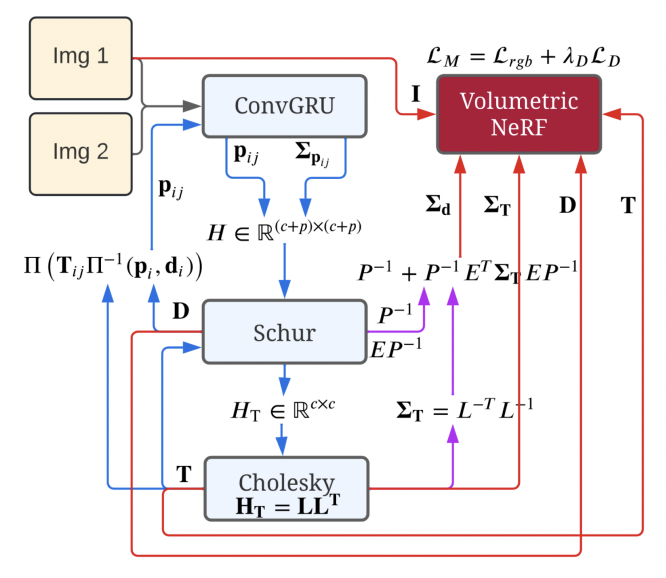
我们管道的输入包括连续的单眼图像(这里表示为Img 1和Img 2)。从右上角开始,我们的架构使用Instant-NGP拟合一个NeRF,我们使用RGB图像I和深度D对其进行监督,其中深度由其边缘协方差ΣD加权。受Rosinol等人[23]的启发,我们从密集的单眼SLAM计算这些协方差。在我们的案例中,我们使用Droid-SLAM。我们在第3.1节提供了关于信息流的更多细节。蓝色显示的是Droid-SLAM的贡献和信息流,同样,粉红色是Rosinol的贡献,而红色是我们的贡献。
1. 追踪
密集SLAM与协方差 我们使用Droid-SLAM作为我们的跟踪模块,它为每个关键帧提供密集的深度图和姿势。从一连串的图像开始,Droid-SLAM首先计算出i和j两帧之间的密集光流pij,使用的架构与Raft相似。Raft的核心是一个卷积GRU(图2中的ConvGRU),给定一对帧之间的相关性和对当前光流pij的猜测,计算一个新的流pij,以及每个光流测量的权重Σpij。
有了这些流量和权重作为测量值,DroidSLAM解决了一个密集束调整(BA)问题,其中三维几何被参数化为每个关键帧的一组反深度图。这种结构的参数化导致了解决密集BA问题的极其有效的方式,通过将方程组线性化为我们熟悉的相机/深度箭头状的块状稀疏Hessian H∈R (c+p)×(c+p) ,其中c和p是相机和点的维度,可以被表述为一个线性最小二乘法问题。
从图中可以看出,为了解决线性最小二乘问题,我们用Hessian的Schur补数来计算缩小的相机矩阵HT,它不依赖于深度,维度小得多,为R c×c。通过对HT=LLT的Cholesky因子化,其中L是下三角Cholesky因子,然后通过前置和后置求解姿势T,从而解决相机姿势的小问题。此外,给定姿势T和深度D,Droid-SLAM建议计算诱导光流,并再次将其作为初始猜测送入ConvGRU网络,如图2左侧所示,其中Π和Π-1,是投影和背投函数。图2中的蓝色箭头显示了跟踪循环,并对应于Droid-SLAM。然后,受Rosinol等人的启发,我们进一步计算密集深度图和Droid-SLAM的姿势的边际协方差(图2的紫色箭头)。为此,我们需要利用Hessian的结构,我们对其进行块状分割如下:
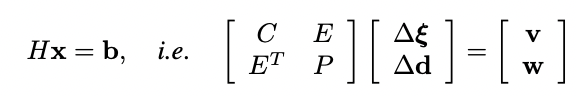
其中H是Hessian矩阵,b是残差,C是块状相机矩阵,P是对应于每个像素每个关键帧的反深度的对角矩阵。我们用∆ξ表示SE(3)中相机姿态的谎言代数的delta更新,而∆d是每个像素反深度的delta更新。E是相机/深度对角线Hessian的块矩阵,v和w对应于姿势和深度的残差。从这个Hessian的块分割中,我们可以有效地计算密集深度Σd和姿势ΣT的边际协方差:
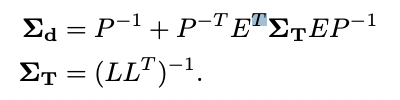
最后,鉴于跟踪模块计算出的所有信息--姿势、深度、它们各自的边际协方差以及输入的RGB图像--我们可以优化我们的辐射场参数,并同时完善相机的姿势。

2. 建图
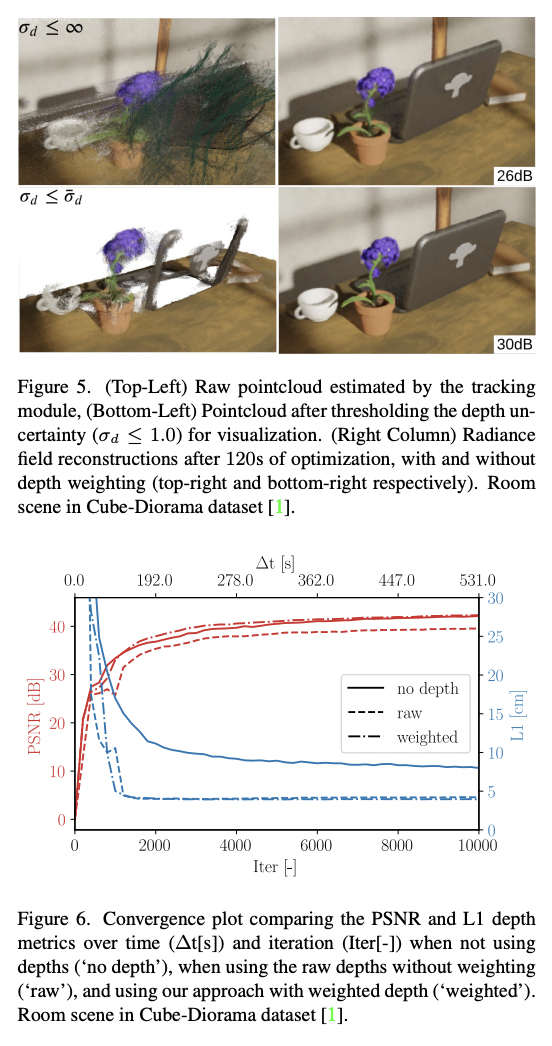
鉴于每个关键帧的密集深度图,有可能对我们的神经体积进行深度监督。不幸的是,由于其密度,深度图是非常嘈杂的,因为即使是无纹理的区域也被赋予了一个深度值。图3显示,密集的单眼SLAM所产生的点云是特别嘈杂的,并且包含大的离群值(图3的顶部图像)。根据这些深度图监督我们的辐射度场会导致有偏见的重建。
Rosinol等人的研究表明,深度估计的不确定性是一个很好的信号,可以为经典的TSDF体积融合的深度值加权。受这些结果的启发,我们使用深度不确定性估计来加权深度损失,我们用它来监督我们的神经体积。图1显示了输入的RGB图像,其相应的深度图的不确定性,所产生的点云(在用σd≤1.0对其不确定性进行阈值化以实现可视化),以及我们使用不确定性加权的深度损失时的结果。鉴于不确定性感知的损失,我们将我们的映射损失表述为:
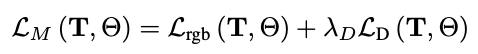
我们对姿势T和神经参数Θ进行最小化,给定超参数λD来平衡深度和颜色监督(我们将λD设置为1.0)。特别是,我们的深度损失是由以下公式给出的。
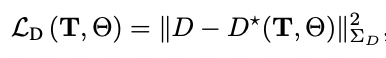
其中,D*是渲染的深度,D、ΣD是由跟踪模块估计的密集深度和不确定性。我们将深度D*渲染为预期的射线终止距离。每个像素的深度都是通过沿着像素的射线取样的三维位置来计算的,在样本i处评估密度σi,并将得到的密度进行alpha合成,与标准的体积渲染类似:
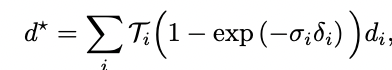
颜色的渲染损失如下:
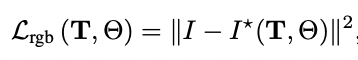
3. 架构
我们的管道由一个跟踪线程和一个映射线程组成,两者都是实时和并行运行的。追踪线程不断地将关键帧活动窗口的BA重投影误差降到最低。映射线程总是优化从跟踪线程收到的所有关键帧,并且没有一个有效帧的滑动窗口。这些线程之间的唯一通信发生在追踪管道生成新关键帧时。在每一个新的关键帧上,跟踪线程将当前关键帧的姿势与它们各自的图像和估计的深度图,以及深度的边际协方差,发送到映射线程。只有跟踪线程的滑动优化窗口中当前可用的信息被发送到映射线程。跟踪线程的有效滑动窗口最多包括8个关键帧。只要前一个关键帧和当前帧之间的平均光流高于一个阈值(在我们的例子中是2.5像素),跟踪线程就会生成一个新的关键帧。最后,映射线程还负责渲染,以实现重建的交互式可视化。
主要结果