最近在整理数据结构和算法相关的知识,小茄专门在github上开了个repo:
https://github.com/qieguo2016/algorithm
后续内容也会更新到这里,欢迎围观加星星!
js对象
js中的对象是基于哈希表结构的,而哈希表的查找时间复杂度为O(1),所以很多人喜欢用对象来做映射,减少遍历循环。
比如常见的数组去重:
function arrayUnique(target) {
var result = [target[0]];
var temp = {};
temp[target[0]] = true;
for (var i = 1, targetLen = target.length; i < targetLen; i++) {
if (typeof temp[target[i]] === 'undefined') {
result
.push(target[i]);
temp[target[i]] = true;
}
}
return result;
}
这里使用了一个temp对象来保存出现过的元素,在循环中每次只需要判断当前元素是否在temp对象内即可判断出该元素是否已经出现过。
上面的代码看起来没有问题,但有点经验的同学可能会说了,假如目标数组是[1,'1'], 这是2个不同类型元素,所以我们的期望值应该是原样输出的。但结果却是1。
同理的还有true、null等,也就是说对象中的key在obj[key]时都被自动转成了字符串类型。
所以,如果要区分出不同的类型的话,temp里面的属性值就不能是一个简单的true了,而是要包含几种数据类型。比如可以是:
temp[target[0]]={};
temp[target[0]][(typeof temp[target[i]])] = 1;
在判断的时候除了要判断键是否存在之外,也要判断对应的数据类型计数是否大于1,以此来判断元素是否重复。
另外,上面的代码语法也有点问题,不知道你发现了没?
我们造的这个temp对象并不是完全空白,他是基于Object原型链继承而来的,所以自带了一个
proto
属性,如果你的目标数组里面恰好有"
proto
"这个值,返回的结果就有问题了,具体结果可以自己测试确认。解决方法有两种:
-
想办法去掉这个磨人的
proto
。显然,我们需要去掉原型链,那么可以使用
Object
.
create
(
null
)
的方式来创建一个完全空白、无原型的空对象。
-
obj
.
hasOwnProperty
(
__proto__
)
会得到false,但是假如我们的目标数组里面包含
__proto__
的话,就不能对
__proto__
进行去重了。
上面说了js中使用对象的一点小窍门,核心在于对象的
hashmap
结构,那
hashmap
是怎样的一个结构呢?且听小茄细细道来。
Hash Map
在真实世界中,我们描述一个事物最常用的方式是使用
属性
-
值
(
key
-
value
)这样的键值对数据,面向对象编程中对象的定义和js中的对象都是这种模式。比如我们描述一个人是这样的:
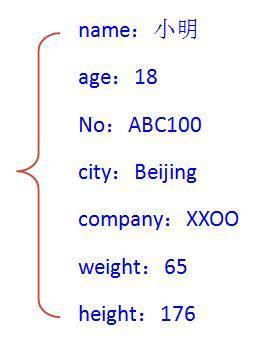
那在计算机中怎么保存这样的数据呢?
计算机存储空间有两个属性:
存储地址
和所存储的
值
,机器可以根据给定的
存储地址
去读写该地址下的
值
。根据这种结构,假如我们将一块存储空间分成一个一个的格子,然后将这些数据依次塞到每个格子里,接下来我们就可以根据格子编号直接访问格子的内容了。这种方式就是数组(也叫线性连续表):数组头保存整个数组储存空间的起始地址,不同下标代表不同的储存地址的偏移量,访问不同下标所对应的地址就能实现数组元素的读写。所以,很自然就会想到将上述的键值对数据的
key
映射成数组下标,接着读写数组就变成了读写
value
值。将
key
的字符串转换成代表下标数值比较简单,可以用特定的码表(如ASCII)进行转换。
上述小明的属性名(
key
)经过变换,可能就变成了这样:

由于key的值不同长度不一,所以转换后的下标的值也相差巨大,另外
key
的个数不确定,也就意味着下标的个数也有很大的范围,甚至无穷多,就有了下面的问题:
怎么将一组值相差范围巨大,个数波动范围很大的下标放入特定的数组空间呢?
如果我们直接取下标值作为存储数组的下标,虽然简单,但是你会发现这个长度为10010的数组只存了8个值,太浪费!如果我们想要缩短数组的长度,比如缩为10,最简单的方式可以使用取模的方式来确定下标:
69
%
10
=
9
,
7
%
10
=
7
,
198
%
10
=
8
……
。这个取模就是
哈希算法
、也叫
散列算法
。
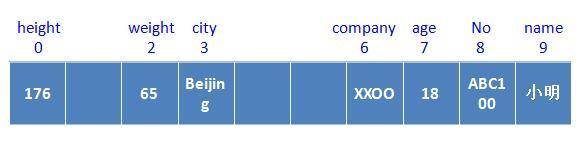
通过这样的方式得到的下标分别为
9
、
7
、
8
、
3
、
6
、
2
、
0
,可以得到保存小明数据的数组:
但是这种方式很容易出现重复,假如我们增加一个属性
phone
,对应的映射值是29,那么29跟69算出来的下标就重复了。也就是哈希算法中的
冲突
,也叫
碰撞
。好的哈希算法能极大减少
冲突
,但由于输入几乎是无穷的,而输出却要求在有限的空间内,所以
冲突
是不可避免的。
那如何处理冲突呢?
还是上面这个例子,29和69发生了冲突,但是我们可以将他们组成一个链表,链表的头部放在数组中,得到。链表结构中,每个元素(除单向链表的尾部)都包含了相连元素的内存地址和本身的值,上文中的冲突放入一个链表中,可以得到这样的结构:

最终得到的这个数据结构,也就是我们常说
哈希表
了。这种将数组与链表结合生成哈希表的方法,叫
拉链法
。
哈希表数据的查找
比如想知道小明的
name
属性,即
小明.
name
。流程是这样的:
-
根据字符映射关系得到映射值为69
-
使用哈希算法得到下标 index=hash(69)=9
-
遍历数组中下标为9的链表,链表的第一个元素的
key
刚好就是我们要找的
name










