所谓爬虫,我理解是对网络数据的定制化抓取。运用Python强大的网页处理能力进行爬虫,能为我们的债市交易及研究提供很多便捷,比如
开发交易员培训报名的抢位外挂;到从业公示网爬取同业小姐姐们的证件照;
实现对中债登、上清所、货币中心
、交易所
、统计局、央行等常用网页内信息的批量抓取、监控、分析等。
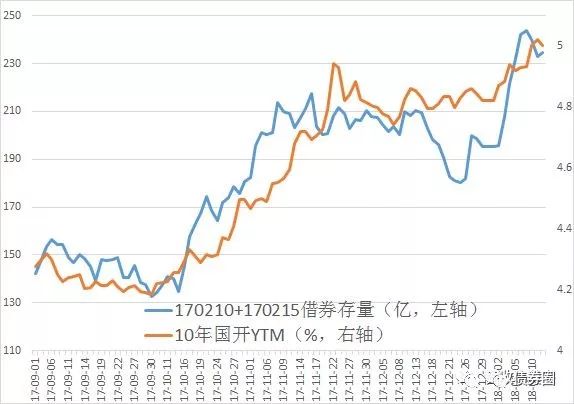
以17年四季度至今的10年国开行情和10年国开借券存量为例。从下图可以看出,在17年国庆后,10年国开的借券存量先于收益率上行,且于17年11月中旬早于收益率筑顶;空方在17年底部分平仓后,18年开年借券量再度上行,随后现券则对应呈现最近的“破5”行情,存在一定的领先性:
先不论上述研究的意义和缺陷,今天要讨论的是,如果想复制上面的研究,该怎么做?首先我们很容易拿到10年国开的收益率序列,难点是对170215和170210借券存量序列的获取,这个数在中债登官网的中债数据→结算行情→风险监测→债券借贷风险监测里可以找到:

然而,很坑爹的是,这个数在中债登上只能按日查询,我们每次的点击,能且只能查询到指定某一日的数值。如果想要连续区间的时间序列?不存在的。

也即是说,通过人工的方法,如果要获取从17年9月至今每个交易日的10年国开借券存量数据,必须重复打开中债登网、选券(210和215各一次)、改日期、点击查询、记录下结果这个操作将近200次。这个时候,我们可以选择请个实习生,又或者写个Python爬虫以代劳上面的操作。

在开始爬虫前,需要做些准备工作:
首先,安装Python并瞄几眼语法入门···
然后,观察刚刚查询所用的中债登地址:http://www.chinabond.com.cn/jsp/include/EJB/jdtj_dzzq.jsp?sel4=1&tbSelYear6=2018&tbSelMonth6=1&calSelectedDate6=4&ZQFXRJD1=00&FUXFSJD1=00&JXFSJD2=00&JDQX2=00&ZQFXRJD3=00&ZQFXRJD4=00&I_ZQDM_JD=170215
地址结尾里熟悉的170215告诉了我们,这个查询网页返回的结果,是由网页地址所控制的。刨除那些冗杂信息,就能看出这个网址的规律所在(这也是选这个作第一篇例子的原因,下一篇将提到如果网址不变的情况如何处理)。网址中 “...Year6=2018 ...Month6=1 ...Date6=4 ...JD=170215”的这串字符,顾名思义,是对2018年1月4日的170215借券存量的提取,大家可以试试保持其他内容不变,只改变网址中这几个关键数字,就能实现对网址中指定日期/券代码借券存量的查询。
在掌握了网址规律后,接下来就是对网页中想要的内容——借券存量进行提取。虽然在我们眼里,中债登的查询结果网页是长这样的:
而在浏览器和Python君的眼里,网页其实是下图这样的一堆“串串”(这些“串串”可以通过在Chrome里打开网页后右击“检查”获取到,其中,每一行都叫做一个tag,下图里tr、td等是tag的名称;class、bgcolor、align等是tag的属性;最关键的“170215”、“758,000.00”则分别是两个相邻的名为td的tag里的内容):
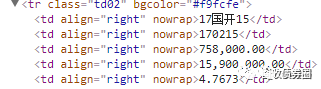
虽然和平常看到的网页不太一样,但这些tag内含的信息和我们所见的是一致的。可以看到,此次的目标数值——170215的借券余额75.8亿,是藏在了
758,000.00这个tag里,就在那里,不悲不喜。就像Word里可以Ctrl+F查找一样,我们也可以通过Python,从这堆tag里把含有170215这个数的tag用Ctrl+F找出来,也即170215 ,再在往下一行的tag里,就藏着我们想要查询的18年1月4日170215的借券余额数值,75.8亿。
所以问题就已经非常简化了。现在已知了两个事情:1、中债登查询借券余额的地址是有规律的;2、这些规律网址里的内容可通过Python被简化为多个tag的形式并被查找。接下来的思路就是,让Python自动地根据网址规律读取每天的网页,接着让Python把每天查询的网页剥皮成上面那堆tag,再从中Ctrl+F找到在170215和170210所在tag的下一个tag里的借券量数值,提取出来并储存。
要如何指挥Python完成了上面的工作呢?这里用到两个Python的包:urllib(这个包将在下一篇中变成selenium + phantomjs以抓取更复杂网页)和BeautifulSoup。
urllib负责把网页中的内容读进Python里,可以看做是个浏览器;BeautifulSoup则负责Ctrl+F处理那些tag的信息。所以,这个案例里实际要做的工作,就是按查询日期批量把网页内容通过urllib拉扯进Python,然后用BeautifulSoup把想要的东西Ctrl+F出来。
urllib包里,我们主要用到urllib.request.urlopen('网址')的函数,从名字可以看出来,就是把目标网页请求并打开读取的函数,读取完丢进Python后就可以把工作交给BeautifulSoup了。
BeautifulSoup则是网页爬虫的核心,建议大家多熟悉其官方文档
,这可能是刚接触Python爬虫时最常查阅的参考书。
在这个案例里,主要用到BeautifulSoup的三个功能:
.find('td', text=‘170215’):顾名思义就是找到名称为td,且内容写作170215的tag
.next_sibling:和字面意一样,就是定位到下一个tag身上的意思
.string:把tag里的内容拎出来
仅用这三个语句,就实现了“寻找170215所在地方,并下移到下一个tag里抓数”的需求。
是不是很简单?所以我已经帮大家写好了,并且标注上了可能遇到的坑。把下面代码复制进装好相关包和万得接口的Python3.6可以直接运行。(看不全的代码可左右滑动屏幕查看,我的代码效率较低,供参考):
from urllib import request
from bs4 import BeautifulSoup
from WindPy import w
from xlwt import Workbook
from os import system
def jqye(year, month, day, bond_list):
page = request.urlopen("http://www.chinabond.com.cn/jsp/include/EJB/jdtj_dzzq.jsp?sel4=1&tbSelYear6="
+ str(year) + "&tbSelMonth6=" + str(month) + "&calSelectedDate6=" + str(day)
+ "&ZQFXRJD1=00&FUXFSJD1=00&JXFSJD2=00&JDQX2=00&ZQFXRJD3=00&ZQFXRJD4=00&I_ZQDM_JD=")
global soup
soup = BeautifulSoup(page, "html.parser", from_encoding="gb18030")
jqye_list = []
for bond_name in bond_list:
bond_position = soup.find('td', text=bond_name)
if bond_position is None:
bond_jqye = 0
else:
bond_jqye = int(bond_position.next_sibling.next_sibling.string.strip().replace(',', '').replace('.00', ''))
print(str(year) + str(month).zfill(2) + str(day).zfill(2) + ':' + bond_name + ':' + str(bond_jqye))
jqye_list.append(bond_jqye)
return jqye_list
w.start()
trade_day_list = w.tdays("2017-9-1").Times
w.stop()
bond_list = ['170215', '170210']
total_jqye_list = []
for trade_day in trade_day_list:
jqye_list = jqye(trade_day.year, trade_day.month, trade_day.day, bond_list)
total_jqye_list.append(jqye_list)
output_workbook = Workbook()
sheet1 = output_workbook.add_sheet(u'jqye_data', cell_overwrite_ok=True)
sheet1.write(0, 0, 'Date')
for i in range(len(bond_list)):
sheet1.write(0, i + 1, bond_list[i])
for i in range(len(total_jqye_list)):
sheet1.write(i + 1, 0, trade_day_list[i])
for j in range(len(total_jqye_list[i])):
sheet1.write(i + 1, j + 1, total_jqye_list[i][j])
output_workbook.save('jqye_output.xls')
system('jqye_output.xls')
可以发现,哪怕基于我十分糟糕的语法,除去注释,Python也只需30行,就能把这次的需求完整表达。上述程序开动后,一般10分钟以内能爬完一个季度的数。运行时,Python会是这样的:
是不是很excited?
如果还想想练手,可以试试把中债登上每日买断回购的210和215余额也一并爬了,操作与上面类似。这样就能更全面统计做空力量了。





