【新智元发自中国乌镇】
乌镇人工智能峰会进入第二天,哈萨比斯、David Silver和Jeff Dean等谷歌高管纷纷发表演讲。他们对AlphaGo 2.0的新技术进行了详细解读。几位“谷歌人”纷纷提到一个关键词——TPU。Jeff Dean 甚至直接放出了与GPU的性能对比图。从昨天的赛后采访到今天的主旨演讲,哈萨比斯等人一直在强调TPU对新版本的AlphaGo的巨大提升。看来,TPU将会成为接下来一段时间内谷歌的战略重点,GPU要小心了。本文带来哈萨比斯、David Silver现场演讲报道(附PPT)。

在升级版AlphaGo首战柯洁后的5月24日,中国乌镇人工智能高峰论坛(The future of AI in Wuzhen)如期召开。一上来就是DeepMind CEO Demis Hassabis和AlphaGo团队技术负责人 David Sliver 的演讲,介绍AlphaGo的研发以及AlphaGo意味着什么。新智元第一时间为你带来精彩内容。
Hassabis和Sliver演讲后,谷歌大脑资深研究员Jeff Dean和Google软件工程师陈智峰一起介绍了《什么是AI?AI是如何工作的?》。不仅如此,还有很多耳熟能详的谷歌、DeepMind大牛出席了本次乌镇人工智能高峰论坛:Alphabet董事长Eric Schmidt(对话AI的潜能)、下午还有TensorFlow软件工程师Rajat Monga(开发者如何使用AI)、谷歌Cloud & AI 研发主管李佳(行业如何应用AI),以及DeepMind联合创始人Mustafa Suleyman和谷歌健康研究产品经理Lily Peng(如何应用AI应对挑战:健康、能源、教育等)。
在论坛最后,乌镇智库秘书长李小鸣将在大会上发布报告《全球人工智能报告2017》。
-
“AlphaGo 外交”,谷歌
向中国示好
彭博社对昨天的围棋大战进行报道时,形成“AlphaGo 和柯洁的围棋大战已经成了 Google 的‘AlphaGo 外交’”,算是 Google 改进和中国关系的最新努力。
报道称, Google 专家和中国著名学者将展开交流讨论,议题是 DeepMind 的不可战胜的围棋 AI AlphaGo 和柯洁之间的对局。谷歌在中国缺席已久。它最初退出源自对审查制度和网络攻击的担忧,而今这种缺席成了其在全球搜索和视频方面霸主地位的最大短板。虽然 Android 是中国最受欢迎的手机软件,有一定的广告收入,但其他服务,比如搜索、Gmail、应用商店和地图都被中国大陆的防火墙所禁止。然而,关于其卷土重来、和 Android 应用商店或其可搜索的学术知识数据库 Google Scholar 建立伙伴关系的猜测,从未停止。
“很高兴回到中国,我对这个国家深表钦佩。” 施密特在峰会上向来宾和行业高管们表示,“呈现在大家眼前的是一个改变世界的非凡机会。”
外媒普遍认为,此次围棋峰会是谷歌向中国示好的一个标志。
由施密特担任主席本次活动是在政府举办年度世界互联网大会的同一地点举行的,选择这里是政府要进一步表达对互联网的认识。峰会标志着一系列 Google 重新融入中国的最新努力:2016年,Google 首席执行官Sundar Pichai 表示,该公司想要重新为中国本地用户服务。同时,Google 在中国各个城市定期举办活动,吸引开发者。
去年,AlphaGo 赢得了与李世石的围棋比赛,在中国的社交媒体引发了 AI 系统是否可以击败中国顶尖棋手的讨论。
谷歌希望本周在乌镇展示出机器智能的最新成就,Google DeepMind 的联合创始人兼 CEO 哈萨比斯在最近一篇博文中写道:峰会的目的是讨论AlphaGo 背后的机器学习方法如何帮助解决现实世界的问题,如能源消耗。
施密特则在会上表示:“ Google和 Alphabet 呈现给大家的是我们一直在做的事情——AI。”
2. 哈萨比斯,David Silver 和 Jeff Dean 的关键词——TPU
上周的I/O大会上,谷歌CEO Pichai 宣布推出的第二代 TPU,既能够加速推理,也能够加速训练。
据介绍,第二代 TPU 设备单个的性能就能提供高达 180 teraflops 的浮点计算量。不仅如此,谷歌还将这些升级版的 TPU 集成在一起成为 Cloud TPU。每个 TPU 都包含了一个定制的高速网络,构成了一个谷歌称之为“TPU pod”的机器学习超级计算机。一个TPU pod 包含 64 个第二代TPU,最高可提供多达 11.5 petaflops,加速对单个大型机器学习模型的培训。
昨天,在升级版的阿老师(AlphaGo)半目优势取胜柯洁之后,DeepMind CEO 哈萨比斯和AlphaGo项目总负责人David Silver 在新闻发布会上接受媒体采访时表示,
AlphaGo实际上是在谷歌云端的单一一台机器上运行的,建立于TPU上。
这和去年使用的谷歌云端多台机器分布式结构有很大区别。因为现在有了一个运行起来更好、更简单的更加强大、高效的算法,它能够用十分之一的运算力来得到更强大甚至更好的结果。
5月24日的峰会论坛主旨演讲中,David Silver 再次提到,新版AlphaGo(DeepMind称之为 AlphaGo Master)是在单个TPU上进行游戏。他还提到了新版本的AlphaGo与去年对战李世石的旧版使用的计算资源的区别,由此看出TPU的强大。


David Sliver之后,谷歌大脑负责人Jeff Dean出现在舞台上,他的演讲话题也没离开TPU。




从DeepMind和谷歌的几位负责人的演讲中可以看到的关键词有三个:AlphaGo、TPU和谷歌云。在提到TPU时,直接放出了与GPU的性能对比,形象生动。这个广告,可以打99分吧。
首战击败柯洁后,DeepMind在发布会上说了6件大事
5月23日,在AlphaGo 首战以四分之一子的优势战胜柯洁之后,双方参加了新闻发布会。
柯洁赛后感言
:
遇到了
“
围棋上帝
”,
比赛中早就预料到结果
柯洁在赛后发布会表示,自己印象最深的,是AlphaGo自己“断”的那手棋,在人类的对局中几乎不可能,但他后来思考发现那步棋“太出色”,“让人输得没脾气”。另外,这次的AlphaGo让他感觉像是遇到了围棋“上帝”,与之前的Master都不同。最后,他对自己“永远有信心”,会全力以赴去下接下来的两盘棋。
柯洁在数子时被媒体捕捉到“笑”了一下,在发布会上坦言那是“哭笑”。实际上他很早就知道结果了,主要是AlphaGo下棋是匀速的,因此在单关也花费比较多时间思考,所以柯洁在这个空档拼命数子,料到自己会输,最后果然输了1/4子。
DeepMind:算法比数据量更重要,AlphaGo 的架构细节稍后会全面公开
DeepMind的赛后感言可归纳为以下几点:
1.
DeepMind对于“机机大战”没有兴趣
——要衡量 AlphaGo 的实力,必须让它跟人类对弈。这次比赛的目的也是为了发现AlphaGo的更多弱点。李世石上次赢了AlphaGo,他们回去以后就对架构和系统做了升级,希望能弥补这种“knowledge gap”。当时的弱点或许被“Fix”了,但AlphaGo还有更多弱点,这是AlphaGo自己(通过自我对弈)和他们这些开发人员都不知道的。
2.
AlphaGo不会控制输赢差距,它只想赢。
AlphaGo总是尽量将赢棋的可能性最大化而不是将赢的目数最大化。它每次面临决策的时候,总是会选择它自己认为更稳妥、风险更小的路线。AlphaGo在争取赢棋时的一些行为,它可能会放弃一些目数以求降低它感知到的风险,即使这个风险非常小。
3.
没有完全弃用人类棋谱。
当然在最初的版本中,AlphaGo从人类棋谱中学习,后来到现在它大部分的学习材料都来自于自我对弈的棋谱。新版本AlphaGo的一大创新就是它更多地依靠自我学习。在这个版本中,AlphaGo实际上成为了它自己的老师,从它自己的搜索中获得的下法中学习,和上一个版本相比大幅减少了对人类棋谱的依赖。
4.
AlphaGo这次强大的地方在于算法。
去年和李世石对战后,他们提出了更强大的算法,而且发现算法比数据量更重要,这也是为什么Master的训练速度是初代AlphaGo的十分之一。这次AlphaGo的硬件支撑是统一通过谷歌云来的,跟上次对战李世石的时候不同。
5.
AlphaGo实际上是在谷歌云端的单一一台机器上运行的,建立于TPU上。
这和去年使用的谷歌云端多台机器分布式结构有很大区别。因为现在有了一个运行起来更好、更简单的更加强大、高效的算法,它能够用十分之一的运算力来得到更强大甚至更好的结果。
6.
还会公布一些AlphaGo自我对弈的棋谱
,这周稍后会正式宣布。
哈萨比斯:AlphaGo 研发介绍, AlphaGo 意味着什么?
“希望这周的比赛能够激发中国的围棋棋手和世界的人工智能科学家”。哈萨比斯介绍了DeepMind在做的事情,以及他们的目标——“发现智能的本质”(slove intelligence),他将最新版 AlphaGo 的技术细节留给了 David Sliver 具体阐释。

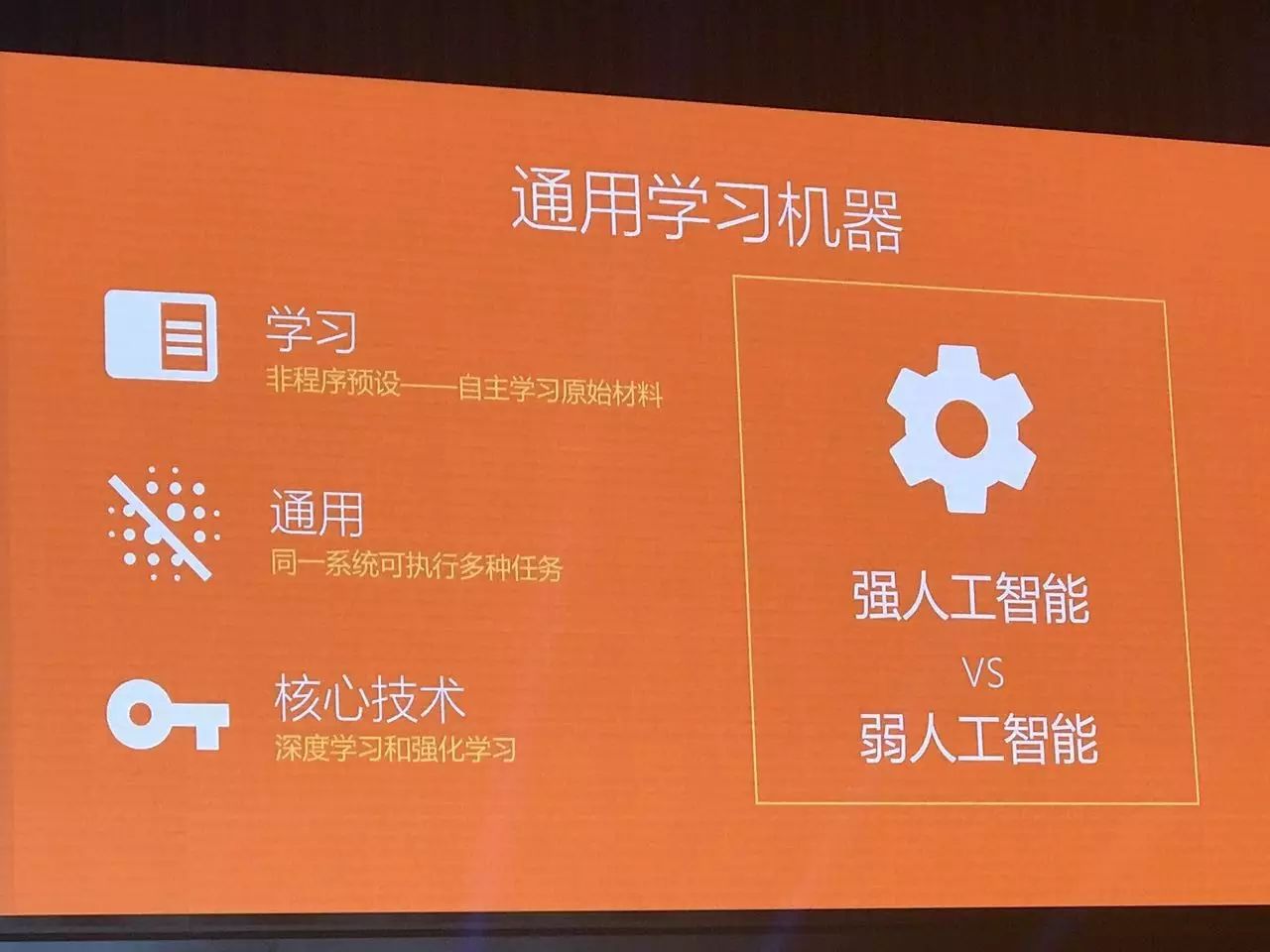
哈萨比斯提到,在DeepMind,他们研究的不是一般的人工智能(AI),而是通用智能,或者说通用的学习机器。这种机器具有自主学习的能力,可以执行多种任务,而其技术核心就是深度学习和强化学习。哈萨比斯认为,只要创造出通用的学习机器,就能够解决很多现在所无法解决的问题。他以载入史册的IBM深蓝对战国际象棋大师卡斯帕罗夫为例,深蓝当时获胜的根本原因是暴力计算。
哈萨比斯认为,与围棋不同,国际象棋是一种盘面已知的游戏,也就是说,最开始所有的棋子都在棋盘上,当你判断局势时,所有的信息都已经有了。而围棋则是不断构筑的游戏,要判断在哪里落子,很多时候顶尖围棋手会告诉你,他们依靠的是直觉,“就感觉这样走是对的”。
刚开始的不经意一步,很可能对未来的形势造成巨大乃至根本性的影响。














Sliver首次揭露了AlphaGo Master版本的新架构和算法


Sliver还是先从最初的AlphaGo讲起,为什么DeepMind团队会选择围棋攻克呢?Sliver表示,围棋是人类最古老最有智慧的游戏,也是测试、构建并且理解人工智能最好的方式。实际上,游戏被用于测试人工智能由来已久,计算机科学家先从国际象棋入手,到了现在的围棋。。而且,这些游戏AI的很多算法后来也被应用于各种各样的AI程序和应用。最后,围棋为誉为AI的圣杯,就像Demis刚刚说的那样。
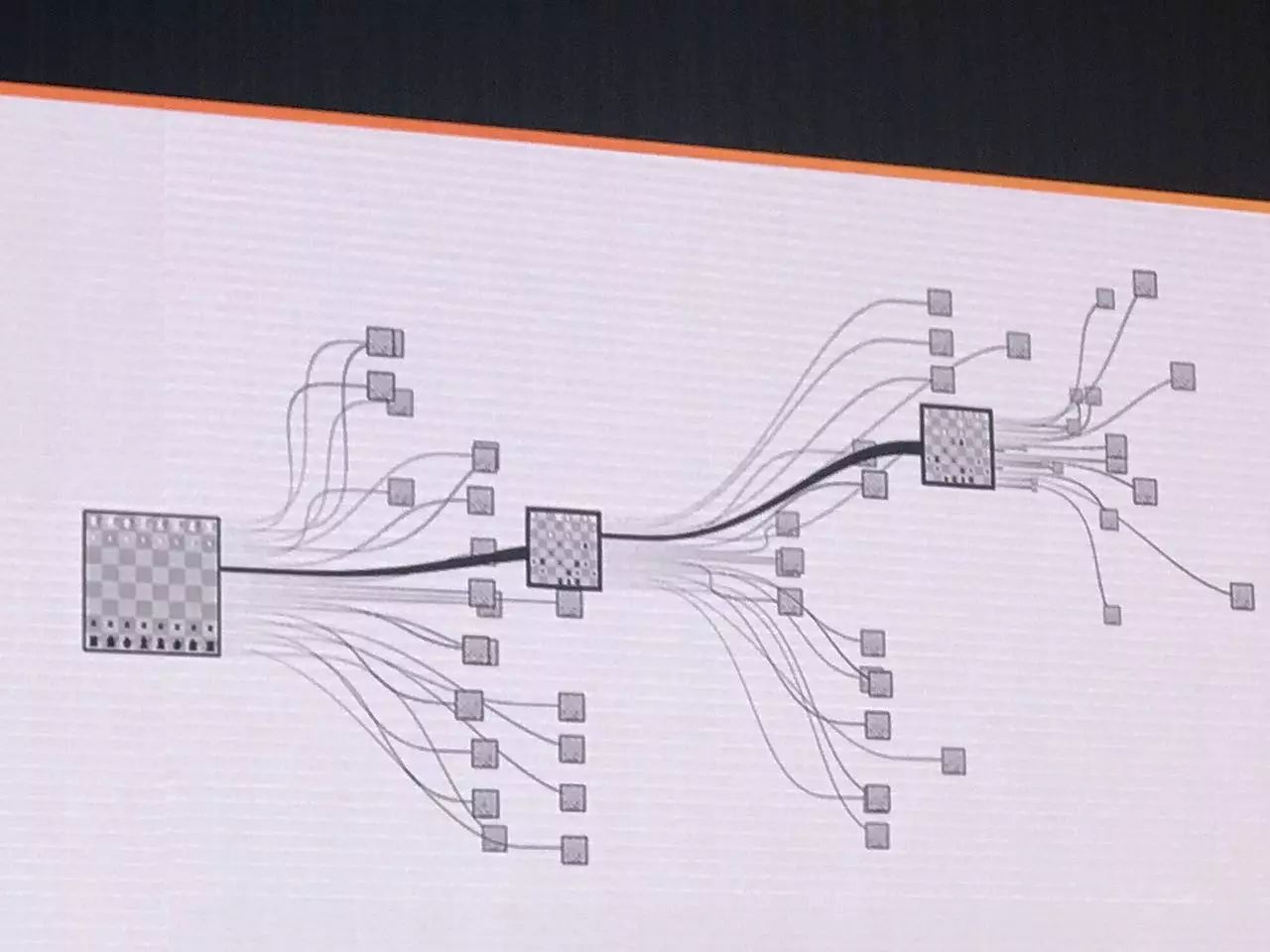
形象化的比较,国际象棋的选择是有限的,每一步都大约有30多种选择,然后再下一步又有30多种选择,以此类推。实际上,国际象棋的这种树形结构很适合用传统的计算机方法去搜索并解决。而围棋的选择则要多得多,每一步都有几万种走法(several hundreds),而下一步又有几万种……由此形成的排列组合,对于传统的计算机或人工智能而言是无解的。

DeepMind是如何解决这个问题的呢?初版AlphaGo,也就是战胜了李世石的那个版本,核心是两个深度神经网络。深度神经网络有很多参数,这些参数可以通过训练进行调整,从而很好地对知识进行表征,真正理解领域里发生了什么事情。我们希望AlphaGo能够真正理解围棋的基本概念,并且全部依靠自己学习这些概念。

具体说,AlphaGo用了卷积神经网络,可以从每一层的一小块当中,得出一些更高层的理解,你可以简单理解为表示棋子在这种局势下会赢还是会输的特征,然后每一层以此类推,最终得到高层表征,也就是AlphaGo学会的概念。初版AlphaGo使用了12层网络,而Master版本的使用了40层。
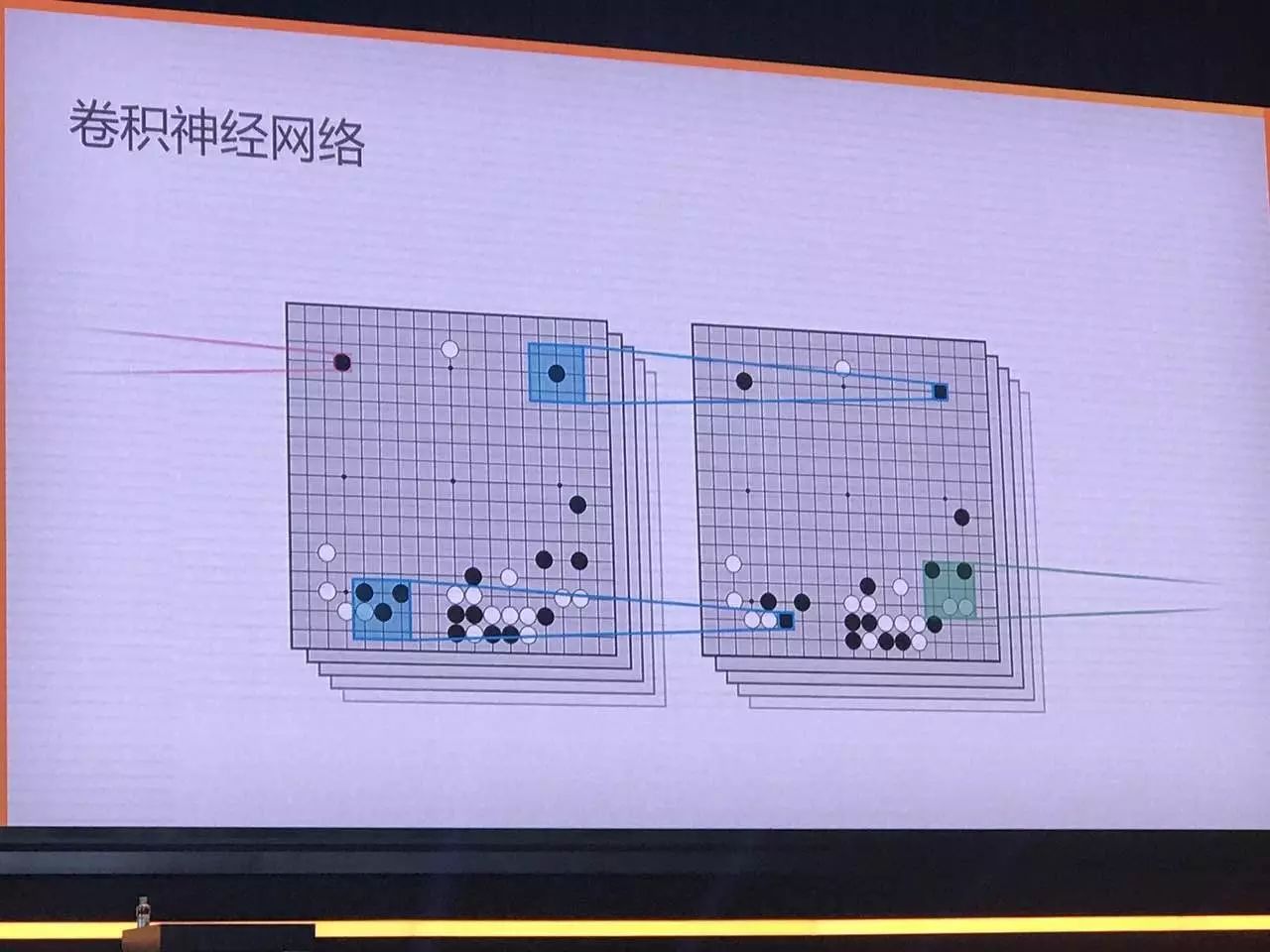
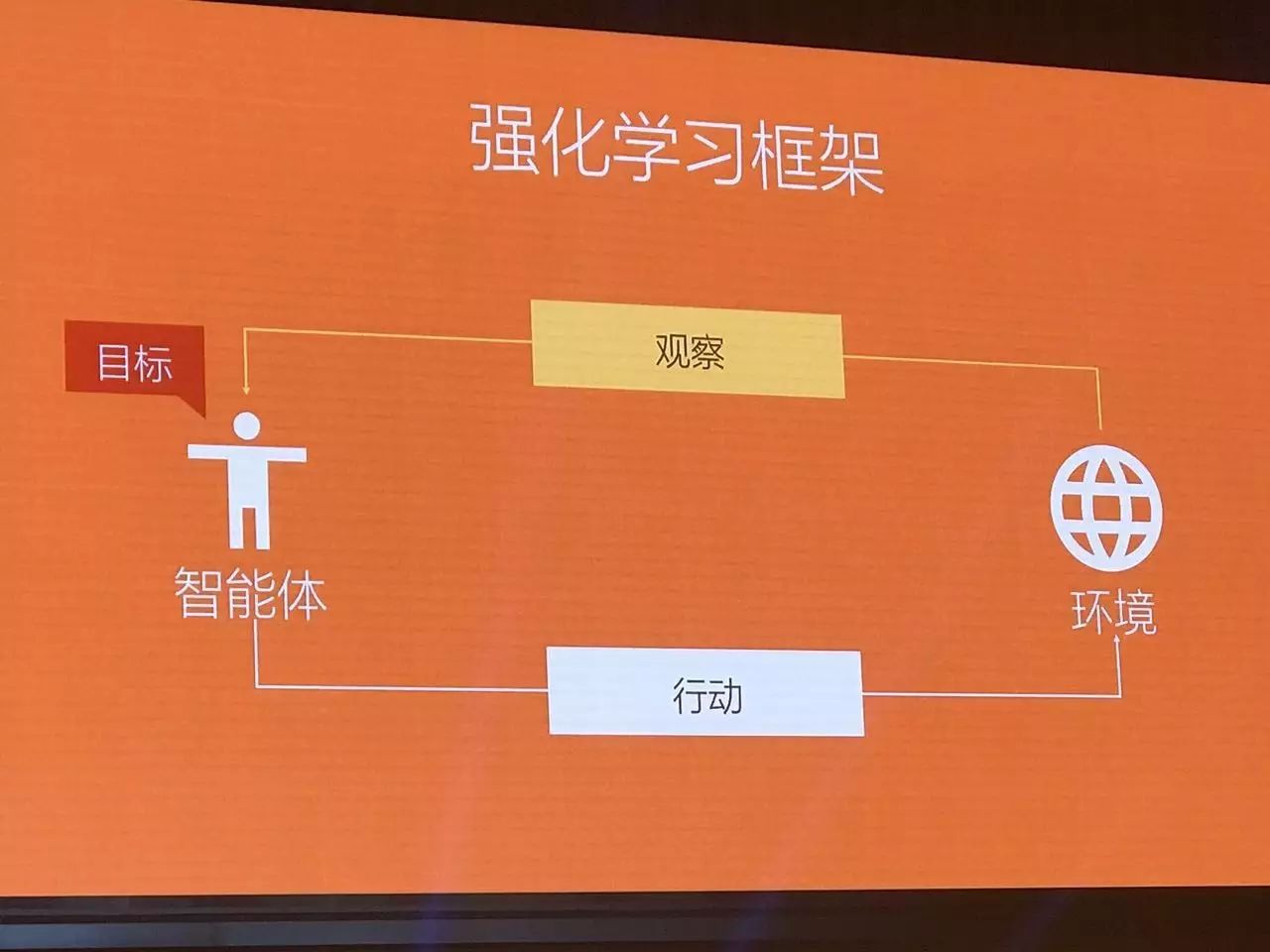
AlphaGo使用两种不同的深度神经网络,第一种是策略网络,目标是选择在哪里落子。第二种则是价值网络,价值网络的作用是衡量走这一步对最终输赢的影响:棋盘的局部(patches)经过很多层很多层的表征处理,最终得出一个数字,这个数字就是代表这步棋会赢的概率,概率越大(接近1),那么AlphaGo获胜的概率就越大。
AlphaGo训练的过程,实际上结合了两种机器学习,首先是监督学习,其中人类棋谱被用作训练数据,然后结合强化学习,在强化学习过程中,系统通过试错不断提升自己,弄清哪种策略最好。这张图显示了AlphaGo的训练过程,先从大量的人类专家下棋的训练数据集开始,我们让策略网络所做的,就是学习人类专家的走法,不断调整参数,最终在每个位置走出跟人类专家一样的走法。









