写在前面
一年一度的春运已经悄然来临,不知道身在异乡的你是否抢到一张回家的火车票
又有多少人因为一张小小的火车票而不能回家过春节。漂泊在外的游子在这个时候的乡愁就是一张小小的火车票
近日在朋友圈被一波抢票加速包疯狂刷屏了
加群:864573496 获取源码!
小编在群里看得干着急,现在市面上各种平台的抢票软件都是收费的的,而且不能保证百分百能抢到票,很多小伙伴甚至被一些钓鱼网站骗钱了。这不是得不偿失了嘛。
作为一个技术控,我喜欢通过自己的技术去解决问题,下面小编将制作一个12306抢票软件,实现自动抢票,一起期待吧~
代码编写
1、程序效果图

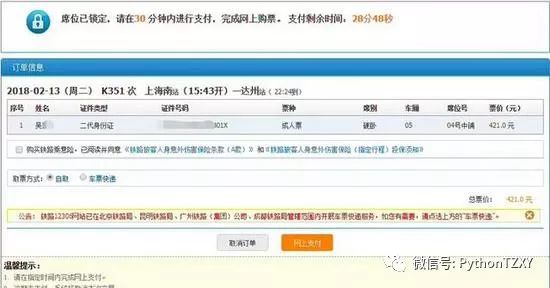
没错,抢到票之后还是需要手动付款的,这个对大家来说还是轻轻松松的吧~
废话不多说,下面就直接开始技术主要部分阐述。
2、主要代码及调试
理论部分
:首先我们需要代码实现一个浏览器功能,那么模块基本上可以确定urllib.parse、urllib.request,这两个包都是和网址有关的模块,那么咱们去登录一个网址,特别是有验证码这些的网址,我们登录进去是不是就行了?答案是对的,但是我们用代码实现的话,这个网址可能每次都有可能被代码去请求,那么服务器怎么知道我们是一个人,而不是多个浏览器不同的用户呢?
此时cookie就非常重要了,在代码中设置好cookie,那么对方服务器自然就知道我们是一个人,比较服务器都是这么区分的。python3中 cookie这个功能是封装在http.cookiejar这个模块之内。好了,代码如下:
# coding=utf-8# author: Jason# time:2018/1/16
20:00:00#version:1.0importurllib.requestasulimporturllib.parseasuzimporthttp.cookiejarascookielibfromjsonimportloadsc=cookielib.LWPCookieJar()#先把cookie对象存储为cookiejar的对象cookie
= ul.HTTPCookieProcessor(c)#把cookiejar对象转换为一个handleopener =
ul.build_opener(cookie)#建立一个模拟浏览器,需要handle作为参数ul.install_opener(opener)#安装一个全局模拟浏览器,代表无论怎么访问都是一个浏览器操作而不是分开获取验证码等msg
接下来就是进入网络分析部分
首先可以使用google浏览器或者搜狗浏览器(本人用的搜狗),打开F12,也就是开发者模式,登录12306的登录地址https://kyfw.12306.cn/otn/login/init
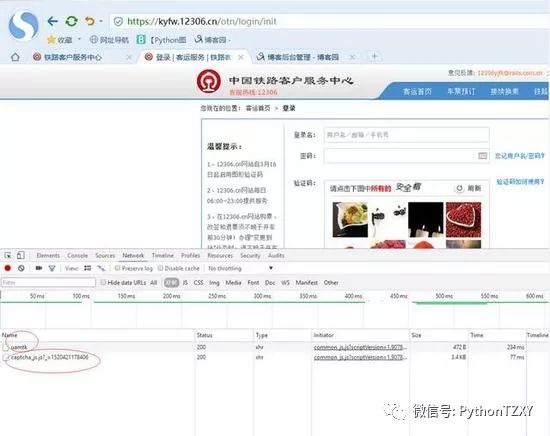
两个红圈中第二个是验证码来源,此时我们只需要记录这个网页(点进去)的详细情况,写入代码当中,python3中urllib.request这个模块打开既可。
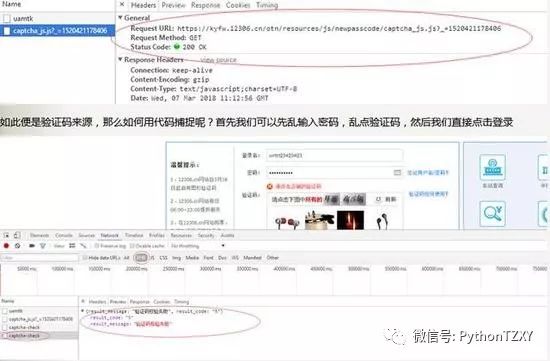
这时候多了一个很奇妙的东西,此时,这里就是验证码验证的网址,那么我们是不是应该记录下来呢?很简单,到Headers里面就全都看得到了

上面那个是服务器验证网址,下面就是我们回复给他的东西,那么那个163,121其实就是我乱点的验证码坐标了。至于为啥是坐标,因为它是用鼠标去点图片,那么他只可能是记录坐标,除非他自己搞了一套人工智能验证图片,但基于他几年前就这么玩了,人工智能根本没有怎么开始,他自然只能是最原始的技术而已。
那么这代表了他是先验证验证码,那么验证密码的在哪?自然是需要验证码这关能过,那我们输一个正确的验证码,再写个错密码,登录。
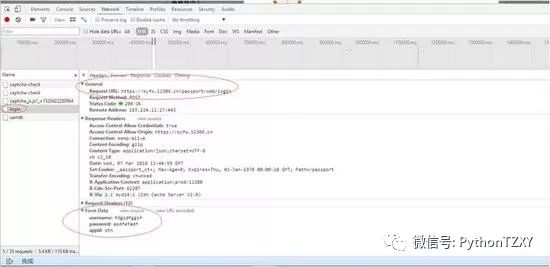
此时可以看到,和验证码一样的方法,我们的回复与验证都在这几个圈了,还记得上面验证码失败的时候回复给我们的code是不是有个数字?这个也很重要,那么可以看看我们的验证成功的验证码返回给我们的是什么东西。
这次我们看到了,验证码成功,显示是4,好,那我们不就可以进行条件判断了么?
那么如何打开一个网址然后把我们点的东西一起发过去呢?上代码
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84
Safari/537.36'}#先写个头,表示我这是浏览器用户登录而不是代码登录,如果不写,代码默认用的签名之类的是编程语言的标识,这样对方服务器很容易就发现你是个脚本了defget_code():#获取验证码的步骤req
=
ul.Request('https://kyfw.12306.cn/passport/captcha/captcha-image?login_site=E&module=login&rand=sjrand&0.6758635422370105')
req.headers = headers code_file =
opener.open(req).read()#此时为浏览器的open而不再是ul.urlopen,下同withopen(r'C:\Users\Administrator\Desktop\12306自动抢票\code.png','wb')asf:
f.write(code_file)
把验证码直接下载后方电脑上,后面要坐标只需要打开这个图既可输入,坐标的输入方式我用字典表示给大家看{1:(45,45)}{2:(120,45)}{3:(180,45)}{4:(255,45)}{5:(45,120)}{6:(120,120)}{7:(180,120)}{8:(255,120)}
根据这个验证码的排序,我相信读者应该知道顺序怎么来的吧,比较坐标就能懂了。
咱们继续往下写
def main_(): get_code() code =input('输入验证码:') req =
ul.Request('https://kyfw.12306.cn/passport/captcha/captcha-check')
req.headers = headers data =
{'answer':code,'login_site':'E','rand':'sjrand'} data =
uz.urlencode(data).encode()#把字典转换为URL querystring,此时是str,要把它变为byts。 html
= opener.open(req,data=
data).read().decode()#读取出来是byts格式,转换为‘utf-8(默认)print(html) result =
loads(html)ifresult['result_code']=='4':print('验证码通过')rep=
ul.Request('https://kyfw.12306.cn/passport/web/login')rep.headers =
headers data =
{'username':'这里就是你用户名','password':'这里就是你的密码','appid':'otn'} data =
uz.urlencode(data).encode() #看到了吗,这就是你给服务器回复的东西 html1 =
opener.open(rep,data = data ).read().decode() result1 =
loads(html1)ifresult1['result_code']
==0:print('账户密码验证通过')else:print(result1['result_message'])else:print('验证码校验失败,重来')if__name__
=='__main__': main_()
此时,咱们就过了验证码密码这一关,后面是不是又要查票?那么同样的方法,我们就可以以此类推到最后一步,这里就不一一贴代码了
ps:查代码这几步的信息可是很重要喔,我们要把它记录好,并且这里面的信息包含了各种作为信息以及他们的顺序,多测试几次基本都能搞出来,这里就是提醒一点
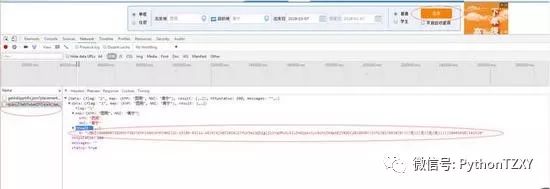
找找规律,然后用split的方法完全就可以切割出来,然后一个循环,就可以得到第几个元素是我们要的,那么后面就可以标志判断返回值如果是无,就没票可以继续查询,直到有票就可以下一步;
那么有票的话,后面一样也是以此类推的方式,代码我就不重现了,很简单,我就把后面出现需要请求的网址都发出来供大家观摩
查询车票信息
url
='https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=%s&leftTicketDTO.from_station=%s&leftTicketDTO.to_station=%s&purpose_codes=ADULT'%(train_data,from_station,to_station)
req = ul.Request('https://kyfw.12306.cn/otn/leftTicket/submitOrderRequest')#确定订单信息
req = ul.Request("https://kyfw.12306.cn/otn/confirmPassenger/initDc")#验证订单
req = ul.Request('https://kyfw.12306.cn/otn/confirmPassenger/getPassengerDTOs')#准备跨到下单中的过度
req = ul.Request('https://kyfw.12306.cn/otn/confirmPassenger/checkOrderInfo')#检查订单信息
req = ul.Request('https://kyfw.12306.cn/otn/confirmPassenger/getQueueCount')#信息提交给服务器,准备进入下单步骤
req = ul.Request('https://kyfw.12306.cn/otn/confirmPassenger/confirmSingleForQueue')#正式进入下单步骤
req =
ul.Request('https://kyfw.12306.cn/otn/confirmPassenger/queryOrderWaitTime?random=%s&tourFlag=dc&_json_att=&REPEAT_SUBMIT_TOKEN=%s'%(numb,time.time()))#下单确认中,此时这个网址一般是进行两次访问,不知为何,我还是做了两次访问,numb是前面查询车票点击预定回复我们的信息中的一条,有点难找喔,我曾经找了三天。。。当然是因为自己不仔细而已
zreq = ul.Request("https://kyfw.12306.cn/otn/confirmPassenger/resultOrderForDcQueue")#最后的结果回执,如果一切都顺利,那么票就已经订了。我一般是打印他返回的内容
'''
zreq = ul.Request("https://kyfw.12306.cn/otn/confirmPassenger/resultOrderForDcQueue")
zreq.headers = headers
data ={"REPEAT_SUBMIT_TOKEN":"%s"%numb,
"_json_att": "",
"orderSequence_no":orderId
}
data = uz.urlencode(data).encode()
html = opener.open(zreq,data=data).read().decode()
result = loads(html)
print('代码全部过完,回去登录下是否搞定')










