实践思路解读
赛题背景
作为电动汽车和混合动力汽车的主要驱动核心,永磁同步电动机常常面临着运行温度过高的问题。该问题会导致永磁体退磁以及线路损伤等危险,从而导致驱动能力下降甚至失去驱动力的后果。
获得电机的实时温度,从而采取相应的降温方法来保障永磁同步电动机的安全,成为公司及车主不可忽略的诉求。
赛事地址 & 数据下载:
https://challenge.xfyun.cn/topic/info?type=electric-car&ch=ds22-dw-gx06
赛题解析
这是一个时间序列预测的回归问题,本题任务是根据从永磁同步电机收集的多个历史传感器数据,预测电机永磁体接下来12个单位的温度(pm),其中单位间隔是为 20 Hz(每 5 秒一行)。
解题方案
ARIMA模型是一种随机时序分析,是一个经典的时间序列模型。该模型实质是差分运算和ARMA模型的组合。但由于ARIMA模型需要调整的参数比较多且网格寻优速度比较慢,所以Auto-ARIMA应运而生。
Auto-ARIMA只需自定义参数范围并自己寻找最佳参数,故比较容易实现的。所以这里我们选择Auto-ARIMA。
在解决机器学习问题时,一般会遵循以下流程: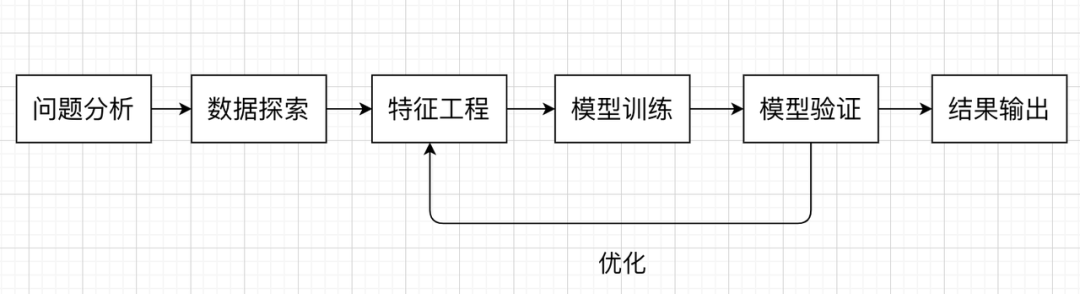
实践完整代码
运行环境:
#----------------环境配置----------------
#安装相关依赖库 如果是windows系统,cmd命令框中输入pip安装,参考上述环境配置
#!pip install pandas
#!pip install pmdarima
#---------------------------------------
#-----------------导入库-----------------
# 数据探索
import pandas as pd
import numpy as np
from tqdm import tqdm
# 核心模型
from pmdarima.arima import auto_arima
# 忽略报警
import warnings
warnings.filterwarnings('ignore')
#---------------------------------------
#---------------数据预处理----------------
# 读取训练数据和测试数据
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
sample_submit = pd.read_csv('sample_submit.csv')
# 数据量
# print(train.shape, test.shape)
# 训练集信息,快速了解数据基本情况,包含column(列名)、Non-Null Count(非缺失样本数)、Dtype(特征类型)等
train.info()
# 运行结果可以看出:数据比较干净,不存在缺失值和异常值。
#---------------------------------------
#----------------训练模型----------------
# 分测量会话session_id进行预测
for session_id in tqdm(sample_submit['session_id'].unique()):
# 获取对应session_id的pm,并按rank从大到小排序
train_y = train[train['session_id']==session_id]['pm'].tolist()[::-1]
# 训练模型
model = auto_arima(train_y, start_p=1, start_q=1, max_p=9, max_q=6, max_d=3,max_order=None,
seasonal=False, m=1, test='adf', trace=False,
error_action='ignore',
suppress_warnings=True,
stepwise=True, information_criterion='bic', njob=-1)
# 把训练数据放入auto_arima得到最优模型,ARIMA里的三个参数PDQ都是可以进行自动调参的,就是通过调整start_p和max_p
# 它会自动对这三个参数进行调整,这里m=1的意思是不考虑季节性。
# 预测未来12个单位的pm
pred_res = model.predict(12)
# 保存对于session_id的pm
sample_submit.loc[sample_submit['session_id']==session_id, 'pm'] = pred_res
#---------------------------------------
#----------------结果保存----------------
sample_submit.to_csv('result.csv', index=False)










