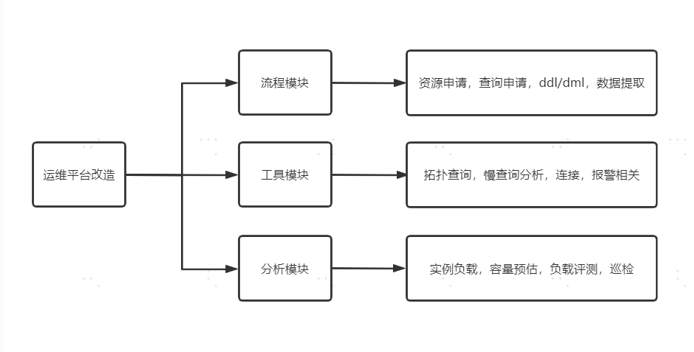
大概在一两年前,我们京东到家在进行容器化前面临着以下这些问题:
容器化也可以理解成迁移上云的过程,当然这个云指的是私有云。大家在使用云端产品的时候,其实会发现和迁移上公有云的思路也是一样的,只不过私有云的资源我们是可以完全把控的。
1)容器化的优缺点
容器化只能解决容器可以解决的问题:
优点:
缺点:
随着技术发展,做技术选型也要适配公司业务发展和扩张变化,我们需要不断思考可能会遇到的问题和随时进行业务迭代。
2)Docker
考虑到以上的问题,我们觉得容器化改造很有必要性,并且它能满足我们当时的一些需求。
因为我们的Docker针对MySQL运用,当时也需要考虑在Docker里需要注意哪些问题,所以我们在这几个方面做了相对于应用来说不太一样的适配,以宿主机为概述:
①配置选择
②镜像管理
最开始有一些比较老的MySQL版本,大版本加上小版本总共八个版本,这时候使用Docker可以根据需求定制化镜像,最终我们统一改成了5.6、5.7这两个版本。
③部署流程
对于应用来说,数据库的部署对于K8s的需求来说并没有那么强烈,底层可能是一个库或者几个库,而应用的机器是几十或者几百个。最主要的区别是,应用是一个无创产物,研发人员来思考它的开启和关闭不会考虑太多问题,但对数据库来说就不是这样的:
网络模式需要根据自身条件取舍,由于我是DBA出身,而且团队对网络这一部分也不太熟悉,在当时的条件下经过了测试后发现没有什么问题就选用了套索模式。
3)为什么没选择k8s


基于到家业务场景下的部署和流程
这套自动化的流程需要自己把控,现在到家这一套流程保证在5分钟之内完成,可以给研发提供一个生产交付。
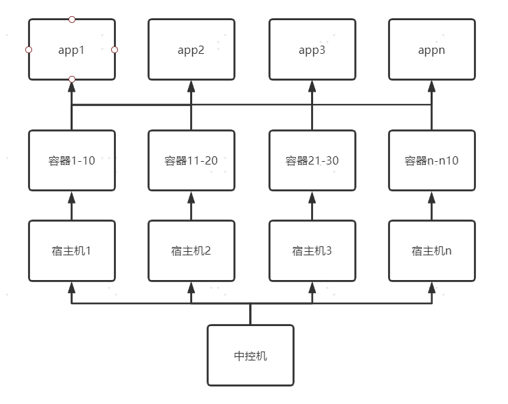
我们刚买的机器和宿主机的规格还是比较匹配的,配置是128核、256g、xxx(18:56)这个样子。
我们当时的规划是平均所有业务线的数量,以8核16g作为一个技术(基础)标准,所以一个宿主机上部署了10个容器,每10个容器会预留一些资源以备扩容缩容的需求。如果布局过多的话,IO有可能扛不住,因为有一些业务可能比较特殊。
比方说从elk中把数据同步到数据库,然后再从数据库中处理,但是有一些业务比较特殊,有一定几率影响到宿主机上的其他业务,导致启动延迟、延迟调用的问题。所以部署也要看利用场景的标准规格。
图里展示的是一部分的管理拓扑,其实和现在的线上业务类似,后续随着业务场景的更变,更重点关注的是宿主机和容器,但对应用来说他们是没有什么区别的。而站在研发的角度上看,他们并不关心你们底层运用了什么技术,他们只关心这个运维产品是否能保证数据库稳定操作。
当然更重要的是,我们要保证自己hold得住新技术,再落实使用,这样才能更好地推动新技术或者架构的改变。
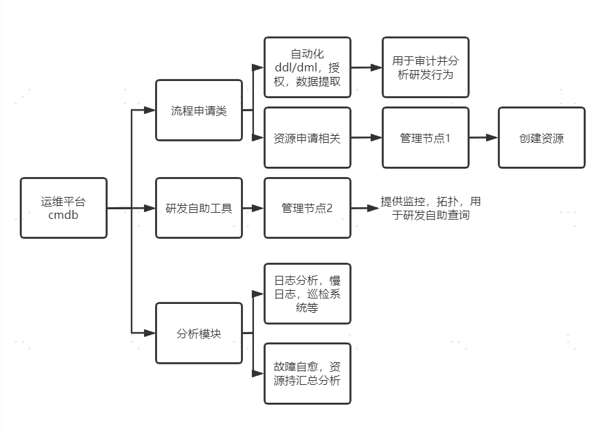
我们之前的运维平台没有进行容器化的改造,几乎所有流程都是断断续续的。但进行容器化改造之后,所有的宿主机和资源都在我们自己手上,这样起码能够满足我们的审计要求。
为什么我们要做容器化改造呢?因为当时从简单管理上选择了host的模式,而使用这个模式有一个问题,就是创造的IP是宿主级的IP。简单点说就是,主从节点上看到的IP不是真实容器节点上的IP,而是宿主机的IP,这就导致了在拓扑上查询是有些不太准确的。所以基于此我们就做了一些定制化的改造。
可能每个公司的具体情况不同,但是运维平台的建设都是大同小异的,都分为:
对于单实例承载能力,我们到家的在MySQL运维方面上单实例承载能力是30000 QPS。每家公司业务团队的方向不同,如果想要达到30000 QPS的话就需要考虑重构和分拆。
我们用的是非常大的ssd。虽然我们在容量上不是特别着急,但还是那句话,在引入新技术后压测能力最起码要达到95%。虽然我们都知道从应用中直接访问数据库,中间通过了一层容器,就算它是万兆网卡、没有延迟问题,但是等到哪天被研发人员告知数据库访问慢,就不得不去怀疑是容器的问题了。
这样的情况我们也遇到过,如果之前连接速度是0.1毫秒,但是现在变成了0.2毫秒,中间0.1毫秒的误差还会出现放大倍数和增减,就很让人怀疑确实是容器的问题。我们觉得引入了能解决问题的新技术,但是其他问题也要纳入考虑范围,像是上面也提到了的“容器化只能解决容器可以解决的问题”,所以网络问题也是我们需要留意的重点。
1)整块大规格ssd解决io不满足问题
最开始在认为数据库容量在1T~2T的情况下,我们考虑的一个数据库大约放10个Docker,所以把一个大盘分成4个小盘,相当于分散部署。
在这种部署情况下,我们认为在io方面是不会有问题的。但这样就会涉及到一些其他的问题,比如说随着业务场景的变化,在凌晨的业务模式下的活动可能导致非常高的io,这样就拖慢了这个盘上另外的实例。
所以早期出现这个问题之后,我们觉得把一整块ssd全部合并在一起相对来说更好。
2)指定数据库版本解决数据库版本过多问题
我们是在多个数据库版本中制定了两个版本,在这个问题上不建议大家跨多个版本使用。比如说,从5.5升级到5.7对各个方面人员来说都是没有大问题的,但是从5.5升级到5.7的话对研发人员来说实现环境和代码上就有可能会出现问题。
3)核心库分散部署解决单一宿主机多个核心库问题
在单机上部署多个实例,不可避免地出现多个核心库部署在一台宿主机上的情况,如果这个宿主机挂了,虽然数据库有高频解决方案,但是不免会遇到核心业务宕掉的特殊情况。
因为每条业务线的情况都不同,所以最好在早期规划的时候就做好数据库定级,解决核心库聚集的问题。
4)冷热实例分散部署解决io压力大的实例聚集部署问题
实例分散不算是特别紧急的问题,因为比起热实例,冷实例相对更加重要,这也需要从业务层面上配合界定。
当然我们也有遇到过最极端的情况,有一些实例的业务特殊性导致写入实例非常频繁,运维团队有负责日志中转这一块业务的同学,它们中写入非常频繁,每天产生的binlog高达几百,这时候我们在和业务协定之后采取了最极端的做法——关闭binlog。
当然我们是大规格的ssd,但是对于80这种相对来说规格比较小的ssd来说可以尽量避免容量上升的问题,如果到后期真的涉及到容量问题,就需要考虑迁移。