
当您为一个数值目标变量构建预测模型时,经典的Python库如Scikit-learn、XGBoost、LightGBM、CatBoost和Keras通常只能提供点预测。遗憾的是,点预测总是不准确的。
假设您有一个模型,它预测某个房屋的销售价格。模型预测某一房屋将以746,632.15元的价格出售。但这个价格到最后一分钱都准确的可能性有多大呢?几乎为零。实际上,更有用(也更安全)的是知道这栋房子将在70万元到80万元之间出售,且具有95%的置信度。95%置信度大致意味着——如果我们能观察所有可能的宇宙——在95%的情况下,销售价格将实际在70万元到80万元之间。这被称为区间预测。
那么,如何在Python中将点预测转换为区间预测呢?这就是MAPIE派上用场的地方。

什么是MAPIE及其使用方法
MAPIE是一个用于获取区间预测的Python库。MAPIE的全称是“模型无关的预测区间估计器”(Model Agnostic Prediction Interval Estimator),其中重要的部分是“模型无关”。事实上,与分位数回归或贝叶斯推断等更传统的方法相反,MAPIE允许您继续使用您最喜欢的高精度模型。

MAPIE的示例
为了在一些真实数据上测试MAPIE,接下来将使用来自StatLib的加州房价数据集,该数据集在Scikit-learn中直接可用(根据BSD许可证)。
from sklearn.datasets import fetch_california_housingfrom sklearn.model_selection import train_test_splitX, y = fetch_california_housing(return_X_y=True, as_frame=True)X_train_and_cal, X_test, y_train_and_cal, y_test = train_test_split(X, y, test_size=1/3)X_train, X_cal, y_train, y_cal = train_test_split( X_train_and_cal, y_train_and_cal, test_size=1/2)
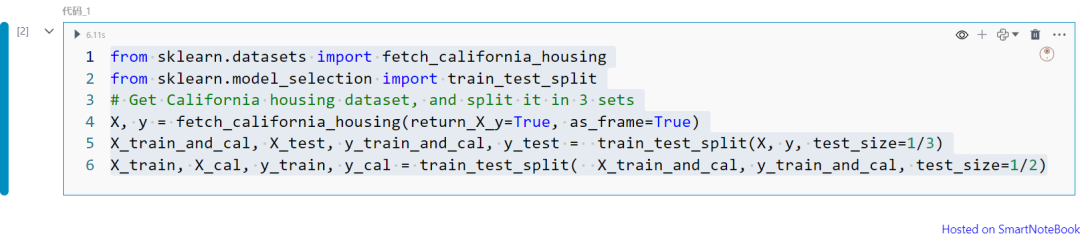
上面代码准备三个数据集:
-
训练数据:用于预测模型学习的数据。
-
校准数据:MAPIE用于校准区间的数据。
-
测试数据:用于评估区间预测效果的数据。
接下来在训练数据上拟合预测模型(将使用Scikit-learn中的随机森林回归器),并在校准数据上使用MAPIE回归器。
from sklearn.ensemble import RandomForestRegressorfrom mapie.regression import MapieRegressormodel = RandomForestRegressor().fit(X_train, y_train)mapie = MapieRegressor(estimator=model, cv="prefit").fit(X_cal, y_cal)
y_test_pred_interval = pd.DataFrame(mapie.predict(X_test, alpha=.05)[1].reshape(-1,2), index=X_test.index, columns=["left", "right"])y_test_pred_interval

上面代码是使用MAPIE回归器的“predict”方法,该方法为观测值生成预测区间(为了方便将其存储在Pandas DataFrame中)。每个区间由区间的左端和右端定义。
“alpha”的含义:如何解释这个参数呢?alpha代表容忍度。它回答了这样一个问题:“我们愿意接受多少个‘错误’?”这里的“错误”指的是落在预测区间之外的观测值。例如,如果alpha设置为10%,这意味着我们期望不会有超过10%的观测值落在MAPIE预测的区间之外。
我们如何确保MAPIE预测的区间实际符合容忍度呢?这就是测试集存在的意义。只需计算y_test的观测值有多少次落在预测区间之外,然后将其与alpha进行比较:
out_of_interval = ((y_test < y_test_pred_interval["left"]) | (y_test > y_test_pred_interval["right"]))\ .sum() / len(y_test)out_of_interval

对不同的alpha值重复此过程。结果如下:

区间外观测值的百分比实际上非常接近相应的alpha值。
MAPIE 内部原理
MAPIE 背后的理念是从模型对一组数据(称为校准数据)产生的误差中学习。一旦我们知道我们应该预期什么误差(对于给定的公差),就足以将其添加到点预测的两侧以获得区间预测。
MAPIE 基本算法包含 6 个步骤:

步骤如下:
-
根据训练数据拟合模型。
-
对校准数据进行预测。
-
计算模型对校准数据产生的绝对误差。
-
alpha
从上一点获得的绝对误差分布中获取 1 分位数。
-
对测试数据进行预测。
-
通过将点 4 处获得的分位数减去(加)到点 5 处获得的预测中来计算区间的左(右)端。
我们可以用几行 Python 代码轻松重现该算法:
import numpy as npmodel = RandomForestRegressor().fit(X_train, y_train)y_cal_pred = model.predict(X_cal)y_cal_error = np.abs(y_cal - y_cal_pred)quantile = y_cal_error.quantile(q=.95, interpolation='higher')y_test_pred = model.predict(X_test)y_test_interval_pred_left = y_test_pred - quantiley_test_interval_pred_right = y_test_pred + quantileprint(y_test_interval_pred_left)print(y_test_interval_pred_right)

y_cal_error的直方图如下:

当alpha为5%时,分位数等于1.18。这意味着随机森林回归器在5%的情况下的误差高于118k元(在95%的情况下误差低于118k元)。此时,通过在随机森林预测值上简单地加上和减去118k元即可获得区间预测:

MAPIE是一个 Python 库,可用于将模型的点预测转换为区间预测。它与模型无关,因此您可以保留自己喜欢的算法模型,同时仍具有强大的统计保证,即预测区间符合您设置的容差。





