
文 | 王启隆
出品丨AI 科技大本营(ID:rgznai100)
在全球开发者纷纷投向 Claude 和其他优秀模型的时候,OpenAI 终于动了!
今天凌晨,OpenAI 正式官宣了
GPT-4o mini
,号称“
迄今为止最具成本效益的小模型
”。GPT-4o mini 在 MMLU(
大规模多任务语言理解
)测试中得分高达 82%,超越了同级别的其他小模型。目前它的定价方案是
每处理一百万个 token 仅需 15 美分,约等于人民币的
1 块钱
(
按当前汇率应该是1.09
)。
这一定价比之前的顶级模型便宜了一个数量级,比 GPT-3.5 Turbo 更是便宜了 60% 以上。而 OpenAI 的首席执行官 Sam Altman 在自己的 X 上也是感慨:两年前世界最好的模型还是 GPT-3(
text-davinci-003
),现在性能不仅提升了好几倍,价格也降到了原来的 1%。

据说,GPT-4o mini 在 OpenAI 的内部项目代号是「
韭菜
」,而此前发布的 GPT-4o 则被称为「
海王星
」和「
大葱
」。

至于 GPT-4o mini 的实际定位,其实是取代原本的“老古董”
GPT-3.5 Turbo
,成为客户端三大模型中的一员。
回想 2022 年 ChatGPT 横空出世,全世界从此记住了 GPT-3.5 这个名字。随着时间发展,国产的很多模型全面超越了 GPT-3.5,转而将 GPT-4 视为目标;国外的闭源模型如 Claude 在出到 3 代的时候就已经开始对标 GPT-4-Turbo,而造福世界的开源模型 Llama-3 更是以超越 GPT-3.5 作为宣传口径;再到最近的许多 2B、3B 的端侧模型(比如
苹果自研的那个 3B 模型
),都已经“以小博大”超越 GPT-3.5 了。
曾经震撼全世界、引领了 AI 对话这一全新交互范式的这款模型,终于在今天迎来了正式退役,颇有当年 Windows XP 风光大葬的感觉。
GPT-3.5 已经从客户端界面消失
不过,底下的用户和开发者如何看待这次发布呢?
部分“直抒胸臆”的评论,继续表达他们这几个月一直以来的诉求:“
我们不要这些小更新,快把
G
PT-
5 放出来
!
”“做得很好,再接再厉。那请问 GPT-5 什么时候发布?”

还有人吐槽,GPT-4o mini 这个命名应该改一改。由于 GPT-4o 的“o”意味着“omni”(全能),所以这款新模型的全称就变成了“GPT-4 omni mini
”,读起来像是咒语一样。
这个评论直接引起了 Sam Altman 本人的回复:“
哈哈,我们会的
。
”

有许多用户仍在催 OpenAI 发布那个
在今年春天惊艳了所有人的语音模式
,而 Sam Altman 透露,
这个月就会开启 Alpha 测试,随后再向公众发布
。如果未来每个人都能用上 OpenAI 在春季演示中的那种实时交互 AI,那大家对 GPT-5 的期待想必会减少很多。

目前,OpenAI 欠的“债”有二月份的 Sora,五月份的 GPT-4o 语音模式和不知什么时候才会发布的 GPT-5。许多用户实在等了太久,已经逐渐消磨了热情,或是转向了其他更好用的模型,比如这篇《
OpenAI 明明封的是中国 API,国外开发者却先转向了 Claude
》就介绍了其中的一种情况。
更有开发者直接表示,这是他见过最冷清的一次 OpenAI 发布:
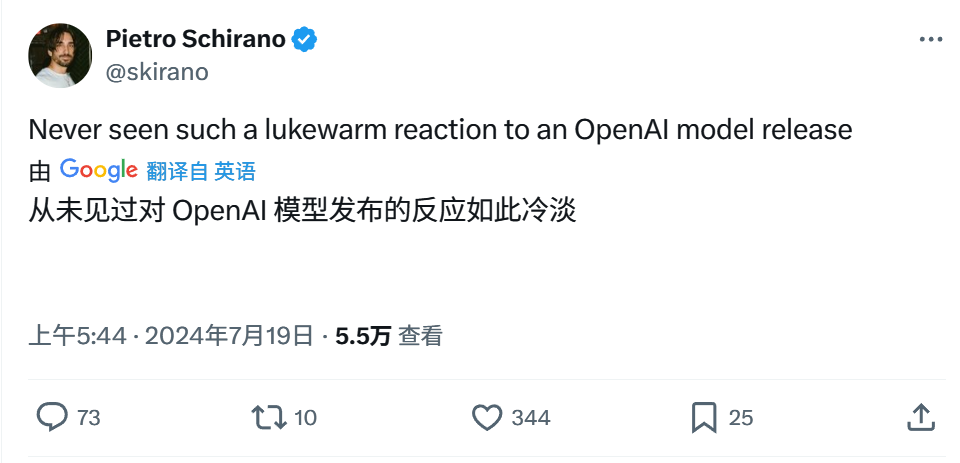
甚至还有人观察到,OpenAI 发布 GPT-4o mini 之后,现在相当于又多了一个可用的免费模型,个人用户给 ChatGPT Plus 充值的意愿逐渐下降,所以倒戈 Claude 的反而变得更多了……
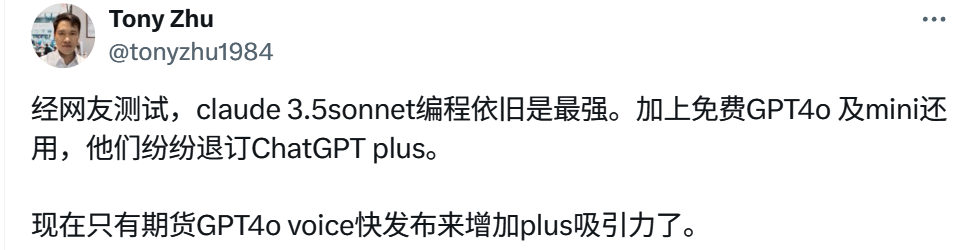
总而言
之,还是让我们先进一步了解 GPT-4o mini 的具体水平,看看它在变便宜之后,还具备多少的性能。

“中杯”竟比“大杯”强?
今天稍早的时候,彭博社等外媒就已经等不及 OpenAI 的官宣,抢先剧透了一些内容。他们报道:“OpenAI 表示,GPT-4o mini 是该公司第一个使用其开发的
全新安全策略
的 AI 模型,称为”指令层次结构”(“The Instruction Hierarchy”)。这应该也是自
超级对齐团队解散、Ilya 离职创业、前陆军将军进入高层
等一系列事件以来,OpenAI 首次在产品层面公布了他们后续的安全策略。
据 OpenAI 官方介绍,超过 70 名社会心理学和错误信息等领域的外部专家对 GPT-4o 进行了测试,以识别潜在风险,这些专家评估的见解有助于提高 GPT-4o 和 GPT-4o mini 的安全性。
再回到接下来要介绍的重点:
性能
。
首先,还是难倒全世界 AI 的那个
经典问题
—— 9.11 和 9.9 哪个大?
先问
GPT-4o,还是和以前一样的答案 + 一段歪理,让人怀疑是不是“弱智吧”的数据不小心喂太多了。

再换成 GPT-4o mini 问一下,生成答案的速度超级快 —— 别问对不对,反正就是很快!值得一提的是,答案也变得非常精炼。

为了直观感受 GPT-4o mini 的速度,请看以下动图:

这要是换成 GPT-4o,那别说动图了,视频都得录一分钟
。
目前,GPT-4o mini 在 API 中已经支持文本和图像处理功能。未来,OpenAI 计划进一步扩展其能力,使其能够处理文本、图像、视频和音频等多种输入和输出。这个模型的上下文窗口高达 128K 个标记,每次请求可以生成最多 16K 个标记的输出,其知识库更新至 2023 年 10 月。得益于与 GPT-4o 共享的改进版分词器,GPT
-4o mini 在处理非英语文本时的效率更高,成本更低。
在文本智能和多模态推理的学术基准测试中,GPT-4o mini 的表现超越了 GPT-3.5 Turbo 和其他小型模型。它支持与 GPT-4o 相同范围的语言处理能力。此外,GPT-4o mini 在函数调用方面表现出色,这使得开发者能够构建可以获取数据或与外部系统交互的应用程序。与 GPT-3.5 Turbo 相比,它在处理长文本上下文时的性能也有显著提升。
OpenAI 在官方博客中放出了关键基准测试的结果,
处处对标谷歌的
Gemini Flash 和 Anthropic 的
Claude Haiku
:
推理能力
:在涉及文本和视觉的推理任务中,GPT-4o mini 表现优异。在 MMLU 测试中,GPT-4o mini 的得分达到了 82.0%,
远超 Gemini Flash 的 77.9% 和 Claude Haiku 的 73.8%。
数学和编程能力
:GPT-4o mini 在数学推理和编程任务上的表现尤为出色,超越了市面上其他小型模型。在 MGSM(
数学推理能力测试
)中,GPT-4o mini 得分高达 87.0%,而 Gemini Flash 和 Claude Haiku 分别只有 75.5% 和 71.7%。在 HumanEval(
编程能力测试
)中,GPT-4o mini 的得分为 87.2%,同样大幅领先于 Gemini Flash 的 71.5% 和 Claude Haiku 的 75.9%。
多模态推理
:在 MMMU(
多模态推理评估
)测试中,GPT-4o mini 也展现出强大的实力,得分为 59.4%,超过了 Gemini Flash 的 56.1% 和 Claude Haiku 的 50.2%。

在 ChatGPT 中,免费、Plus 和 Team 用户从今天开始将能够访问 GPT-4o mini,取代 GPT-3.5。企业用户也将从下周开始获得访问权限。GPT-4o mini 现在可作为文本和视觉模型在 Assistants API、Chat Completions API 和 Batch API 中使用。具体的定价方案如下:
-
GPT-4o mini 的输入 token 价格为 0.15 美元 / 1M;输出 token 价格为 0.6 美元 / 1M。
-
相比之下,此前的 GPT-4o 模型输入 token 价格为 5 美元 / 1M,输出 token 价格为 15 美元 / 1M,价格差异非常大。
-
而 GPT-3.5 Turbo 的最后一个版本 gpt-3.5-turbo-0125 定价为输入 0.5 美元 / 1M,输出 1.5 美元 / 1M。
-
此外,使用 Batch API 可以将 token 价格降低一半。例如,使用 Batch API 时,GPT-4o mini 的输入 token 价格降至 0.075 美元 / 1M,输出 token 价格降至 0.3 美元 / 1M。
Open
AI 计划在未来几天推出 GPT-4o mini 的微调。
下图则是由 Artificial Analysis 绘制的一张描述比较不同小型 AI 模型价格的图表,图表展示了各种模型的综合价格(包括输入和输出 token 的成本)。


Karpathy:以后都应该卷小模型!
今天,还有一个相当“应景”的推文,便是
先前宣布创业的 AI 大神 Andrej Karpathy
在看到 GPT-4o mini 的发布之后,第一时间发表了他的想法:“
大模型正在变得更小,而这种小型但高效的模型将代表着 AI 发展的新方向
”。
从最早微软
发表“小模型”的观点开始,法国出现了一个明星独角兽 Mistral,引起了一波
压缩模型的热潮,
国内
也有面壁智能这类专攻
“高效
”
小模型的公司,
目前 AI 圈已经逐渐形成了共识,而
Karpathy 的话则是为
其进行了一份完美的总结。

大语言模型(LLM)的规模竞争正在向一个意想不到的方向发展——变得更小!我预测,我们将看到体积极小但能够非常出色且可靠地“思考”的模型。甚至可能只需调整 GPT-2 的参数设置,大多数人就会认为它很“聪明”。
那么,为什么现在的模型体积如此庞大呢?
这是因为我们在训练过程中还不够高效
。我们要求模型记住整个互联网的内容,而令人惊讶的是,它们真的做到了。它们甚至能够背诵常见数字的 SHA 哈希值(一种复杂的加密算法生成的固定长度字符串),或者回忆极其冷门的事实。实际上,大语言模型在记忆能力上远超人类,有时只需一次学习就能长期记住大量细节。
想象一下,如果你要参加一场考试,考官给你一段话的开头,要求你默写出互联网上的任意段落,这就是当前模型的标准训练目标。之所以难以做得更好,是因为在训练数据中,模型的思考能力和知识储备是密不可分的。因此,模型必须先变大才能变小,因为我们需要它们的自动化帮助来重构和优化训练数据,使之成为理想的、人造的格式。
这是一个循序渐进的改进过程:一个模型帮助生成下一个模型的训练数据,直到我们得到“
完美的训练集
”。当我们用这个完美的训练集来训练 GPT-2 时,按照今天的标准,它将会是一个非常强大和智能的模型。也许它在 MMLU 上的分数会稍低一些,因为它可能不会完美地记住所有的化学知识。也许它需要偶尔查阅资料来确保信息的准确性。但总的来说,
这种小型但高效的模型将代表着 AI 发展的新方向
。
这条推文自然是引起了激烈讨论,甚至让马斯克在底下评论了一句:“对,特斯拉在现实世界的人工智能领域也在干同样的事情。” 可谓是打了波广告。


又双叒叕是华人天团?
在 OpenAI 的官方博客文末,介绍了这款模型的负责人 Jacob Menick, Kevin Lu, Shengjia Zhao, Eric Wallace, Hongyu Ren, Haitang Hu, Nick Stathas, Felipe Petroski Such
和项目负责人
Mianna Chen。

Kevin Lu 是 OpenAI 的应用研究科学家,2021 年毕业于加州大学伯克利分校,当时他和 Pieter Abbeel 与 Igor Mordatch 合作研究强化学习和序列建模。Lu 在 X 上转发了“大模型竞技场” lmsys 的庆祝新闻,用早期测试版本的 GPT-4o mini 在竞技场 PK 的结果侧面印证了其性能水平:和 Gemini-1.5-pro-API-0409-Preview 与 GPT-4-Turbo-2024-04-09
并列第四
。

Shengjia Zhao 在 OpenAI 从事大型语言模型的训练和对齐工作。他本科毕业于清华大学,是斯坦福大学计算机科学系 Stefano Ermon 指导的博士生,期间在做不确定性量化和生成模型的研究。在 X 上,Zhao 分享了一个观点:“
人工智能每年在相同能力的情况下降低 10 倍的
成本










