

阿里安全采用 NVIDIA NeMo 框架和 TensorRT-LLM 大语言模型推理加速库,显著优化了模型训练与推理性能。
作者
|
刘彬(花名:慧原)
阿里安全算法工程平台工程师
彭伟(花名:又可)
随着 ChatGPT 的一夜爆火,大模型如今越来越广泛的应用到各种业务领域中,阿里安全的业务领域对大模型技术的应用也已经 2 年有余。本文对阿里安全在大模型工程领域积累的实践经验做出总结和分享。
在大模型实际应用实践的过程中,阿里安全采用 NVIDIA NeMo 框架和 TensorRT-LLM 大语言模型推理加速库,显著优化了模型训练与推理性能。其中 NeMo 在多卡环境可实现 2-3 倍的训练加速,TensorRT-LLM 结合 SmoothQuant Int8 可实现领先的推理加速比,动态批处理策略 (Dynamic Batch) 将计算步骤减少 30%,实际 QPS 增益 2-3 倍。Prompt 优化策略在特定业务中提升吞吐高达 10 倍。整体优化成果显著增强了模型性能与业务效率。
目前市场上主流大模型以 Transformer 网络结构为主,作为阿里安全的工程落地团队来说,全面分析这个模型的结构以和计算其 FLOPs 十分必要。本文首先重温 Transformer 模型的网络结构,结构如图一所示:
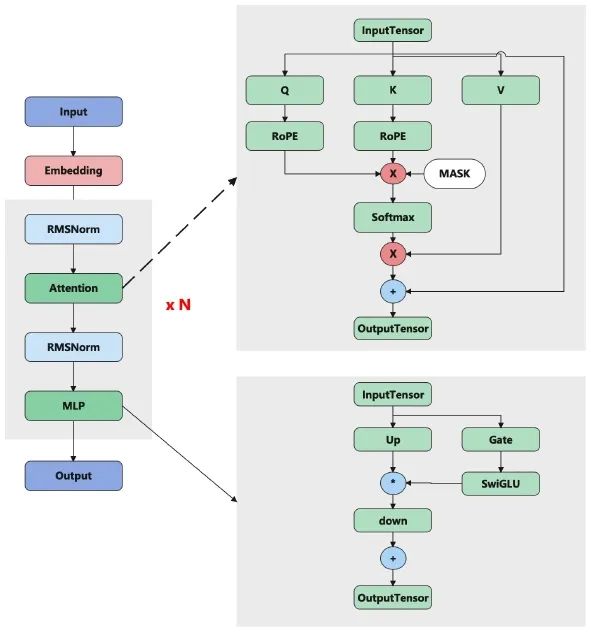
▲图一:Transformer 模型的网络结构
从上述的模型结构中可以看出,主要的计算量在 decodeLayer, 接下来,我们对该网络(以 Llama2 为例)的计算做详细的分析。
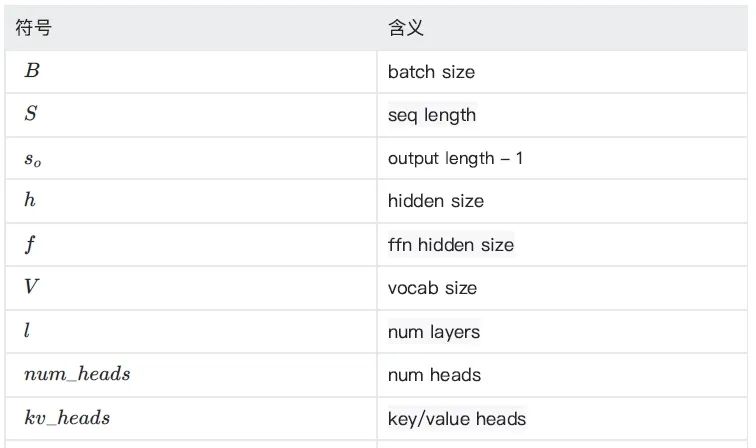
矩阵乘法 FLOPs:矩阵乘法为乘加过程,用浮点数运算次数 (FLOPs, floating point operations) 表示计算量的大小:
上面的矩阵 M 和 N 相乘的 FLOPs 计算量。
decode-only Transformer 模型架构包含:
FLOPs = (attention + mlp) * layers + output_layer
其中输入 embedding 层不涉及 FLOPs 计算,因为 embedding 层做的事情只是根据输入 token 选择对应行。
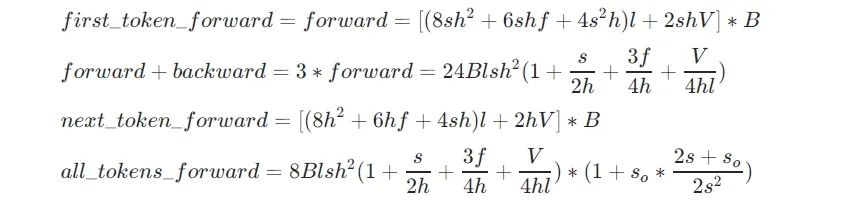
由于l、h、f、V都是模型的参数,这几个变量是固定的,影响模型计算的 FLOPs 的就剩下B、s、s0这三个变量,可以总结如下规律:
首先,我们从工程的角度,分析并总结了一些大模型训练的相关经验,针对过去 2 年阿里安全工程团队对大模型训练加速这一部分做出分享。
为什么选择 NVIDIA NeMo 框架(Megatron-LM)训练
目前开源市场使用人数最多的是 DeepSpeed 和 NVIDIA NeMo 框架 (Megatron-LM) 这两种,本文主要从工程角度(训练速度的角度)来分析训练框架的特点,接下来分别介绍这两个框架的主要特征(feature)。
DeepSpeed 是微软开发的一款十分受欢迎的大模型训练框架,feature 有很多,对于训练速度提速这块,本文重点介绍其模型并行策略,主要是 ZeRO 相关 feature。

▲图二:DeepSpeed ZeRO 模型并行【1】
假如 GPU 卡数为 N=64,Ψ 是模型参数,假设 Ψ=7.5B,使用 Adam 优化器,K 是优化器的超参,在 64 个 GPU 下 K=12,则:
NVIDIA NeMo 框架 (Megatron-LM) 是 NVIDIA 提供的一个端到端的云原生框架,无论是在本地还是在云上,用户可以灵活地构建、定制和部署生成式 AI 模型。它包含但不限于预训练模型、数据管护工具、模型对齐工具、训练和推理框架、检索增强工具和护栏工具包,为用户使用生成式 AI 提供了一种既方便、又经济的方法,同时,NeMo 也支持多模态模型的训练,包括但不限于 Stable Diffusion, Vision Transformer 等。
本文关注焦点在于大模型训练框架的速度对比,因此只聚焦 Megatron-Core 部分。在使用 NeMo 进行大模型训练过程中,影响训练速度比较大的 feature 主要如下:
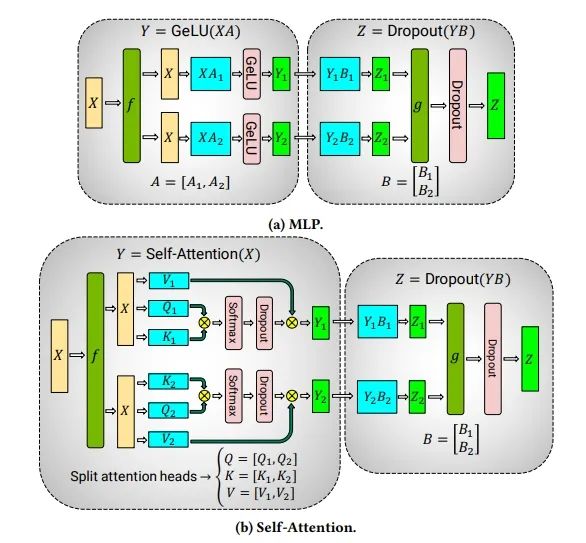
▲图三:张量并行(TP, Tensor Parallelism)【2】
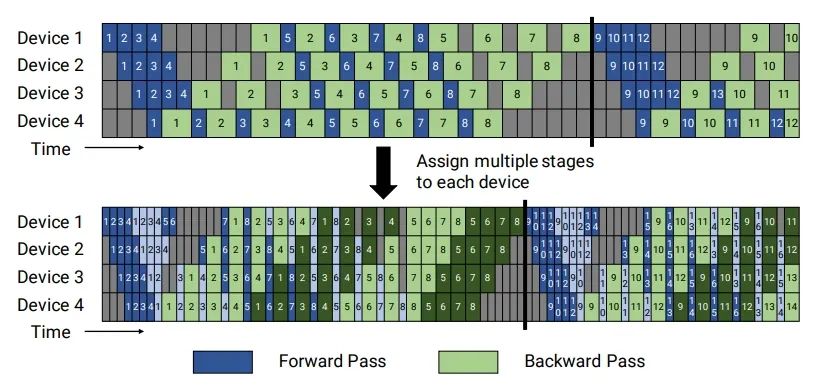
▲图四:流水线并行(PP, Pipeline Parallelism)【3】
当然,NeMo 还有其他的一些 feature,比如计算和通信做 overlap,调用基于 CuDNN 实现的 FlashAttention 等等。
在 Megatron-LM 的公开论文中可以看到(如图五所示),Megatron-Core 可以保证在 GPU 水平扩展的时候,单卡的 Flops 基本能保持不变,而 DeepSpeed 有比较大的衰减。175B 模型在 1,536 卡的规模上,Megatron-LM 的性能是 DeepSpeed 的 3 倍多,530B 模型在 2,240 卡规模上Megatron-LM 也是 DeepSpeed 的 3 倍多。
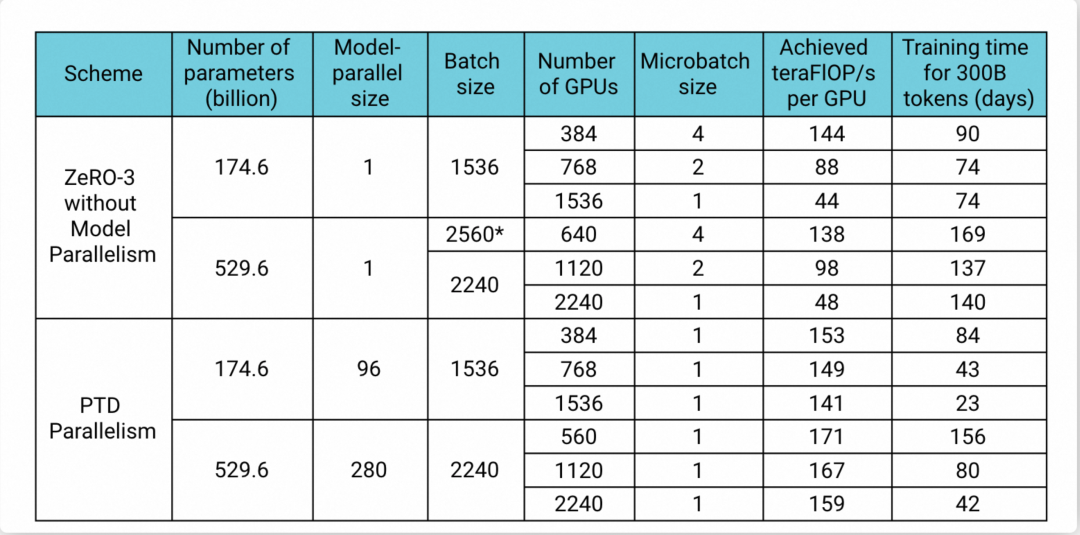
▲图五:Megatron-LM 论文中性能对比数据
我们团队在 Llama2-13B 的模型做了类似的实验,得出的结论也是 NeMo 比 DeepSpeed 性能高,具体的数据如下表所示:
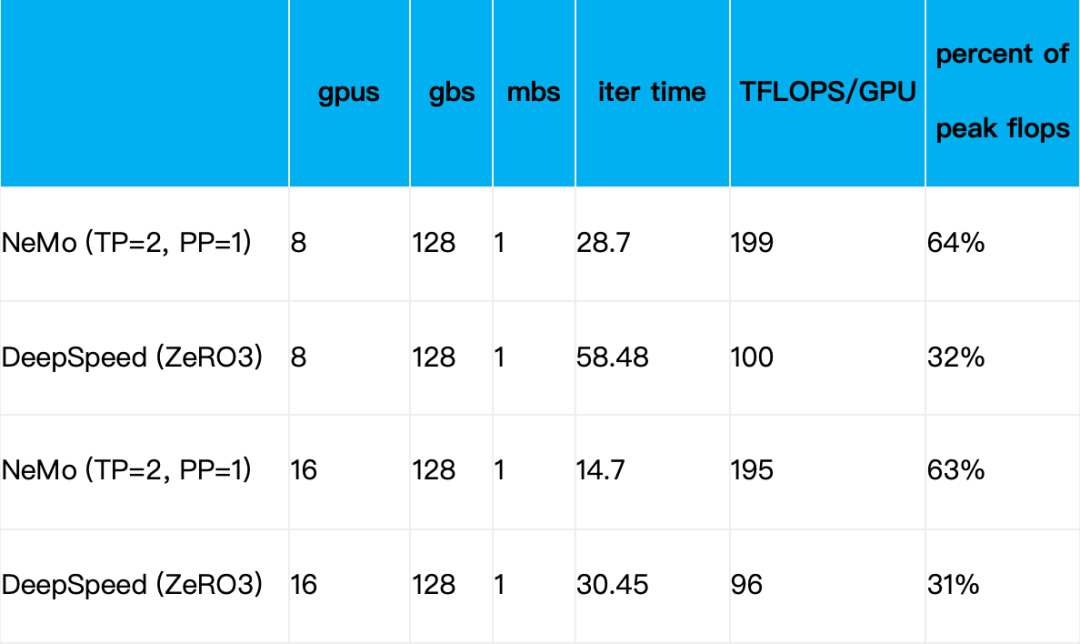
无论在单机 8 卡,还是双机 16 卡的规模上,NeMo 的性能都是 DeepSpeed 的 2 倍。
针对大模型推理,NVIDIA 推出了 TensorRT-LLM,实现了业界领先的性能。经多方比较,TensorRT-LLM 被我们选为构建阿里安全大模型高性能推理的基石。在阿里安全的业务中,由于大模型服务比较多,为了让算法同学可以快速部署大模型,工程团队开发了一系列功能让算法同学可以快速、高效、平稳的部署大模型。部署的具体流程图如下:
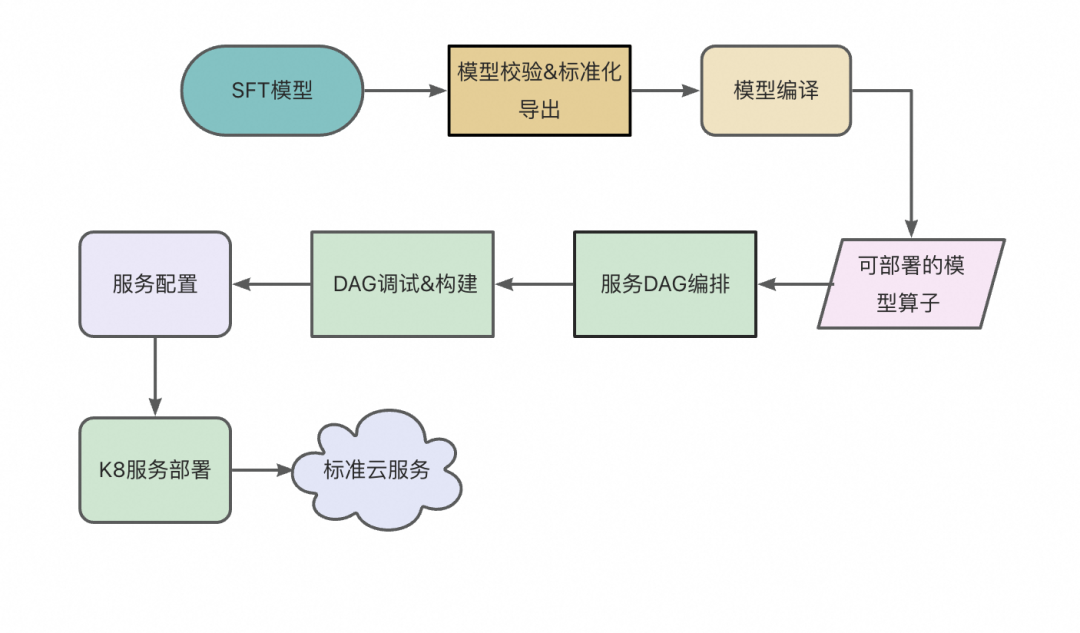
▲图六:大模型部署流程
针对这种服务特点,我们采用异步服务进行部署,即上游调用先提交一次请求,然后可以通过轮询或者回调的方式获取服务计算的结果,具体的架构图如下所示:
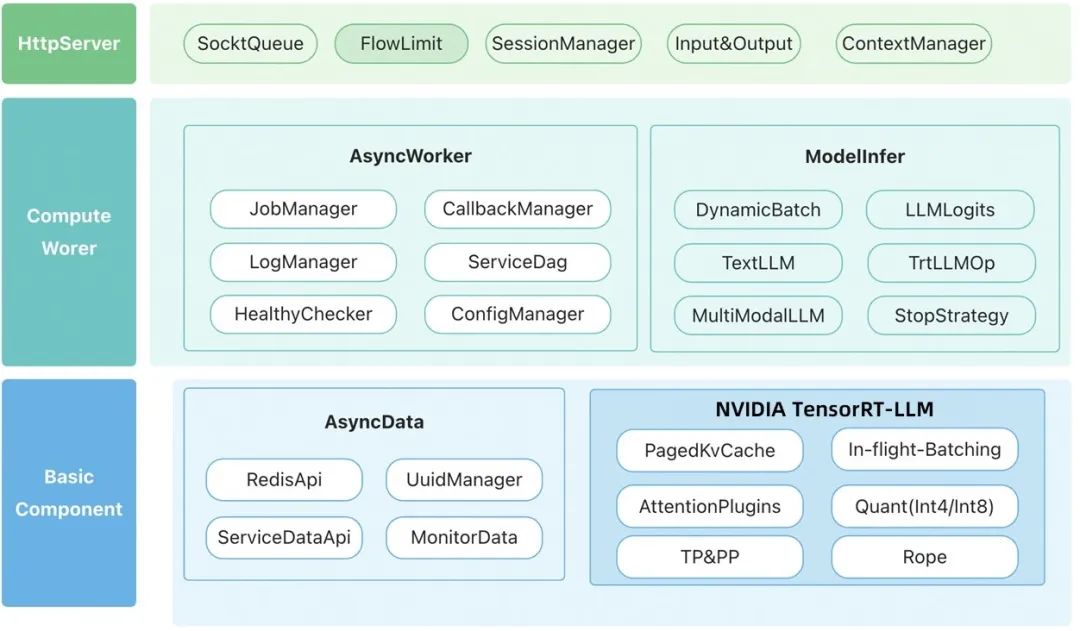
▲图七:模型服务架构图
Httpserver 层是服务的前端,它负责服务对外的交互,输入处理和输出处理等事情。
该层是模型服务的核心计算层,服务主要的计算都在这层中完成。
以上是服务的主要架构,采用该架构基本能 GPU 在服务中做到满负载的工作(凑满 batch 计算),同时可以保障服务的稳定运行。
为了进一步提升模型推理的速度,我们仔细分析了大模型在推理过程中一些计算,从上述公式中我们可以看到,要想让推理过程中的计算密度变大,只能调大 batch_size;而 generate 过程中,每个样本的输入长度和输出长度都不太一样,必然会导致算力有浪费的情况,具体的推理过程如下图所示:
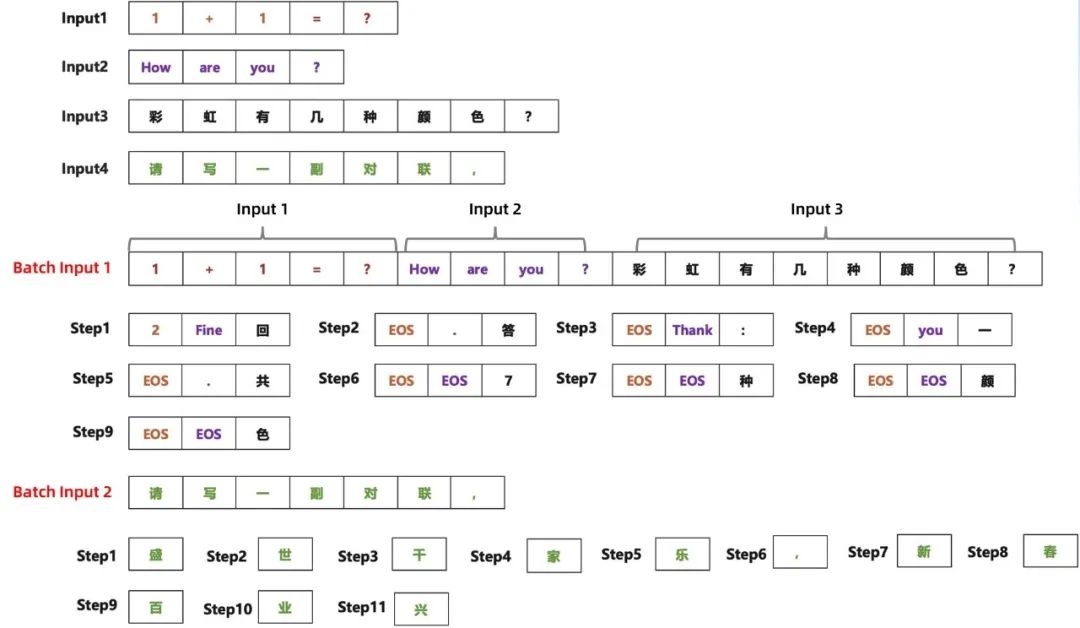
▲图八:大模型 generate 生成过程示意图
从上述的案例中可以看到,一共有 4 条样本需要进行推理,而若 GPU 最多只能一次处理 3 条样本,则共需要 9 步完成这三条样本的推理,而第 1 条样本在 step1 的时候就推理结束,input2 在 step5 的时候推理结束,因此在这 9 步推理过程中,出现很多 EOS 的 token(我们把这种叫做气泡),气泡越多,算力浪费越严重;剩余 input4 只能按 batch_size=1 进行推理,算力浪费较为严重。
在实际的推理服务中,如果一个 batch 中的其中一条输出的 output_len 很大,就可能会导致该 batch 的气泡比例可能超过 80%,就造成了算力的严重浪费,为了解决这种问题,我们提出新的推理算法,算法的逻辑如下:
1. 准备输入的数据(n = max_batch_size*10),形成一个候选集合 S
2. 如果集合 S 为空,退出;否则,对集合 S 的文本序列排序
3. 从集合 S 中取出 m 个文本进行推理,其中 m = find_max_batch_size(current_seq_len),推理到一定 step(一般取 100),或者本次 batch 的 70% 的样本已推理完并且未推理完成的样本数大于 1/max_batch_size,推理中断退出。
4. 将上次未推理完成的样本拼接上已生成的部分文本作为一个新文本,插入到候选集合 S 中,然后重复第 2 步;
算法的核心思想是依据当前是 seq_len 设置每次 batch 的大小(为了让 GPU 内存占满,不造成算力的浪费),并且每次推理过程中会动态检测是否需要提前终止,终止的条件是大部分样本已完成了推理或者推理的 step 到达一定限度。针对图九中的案例,我们使用新的调度思想之后的效果如下图所示:
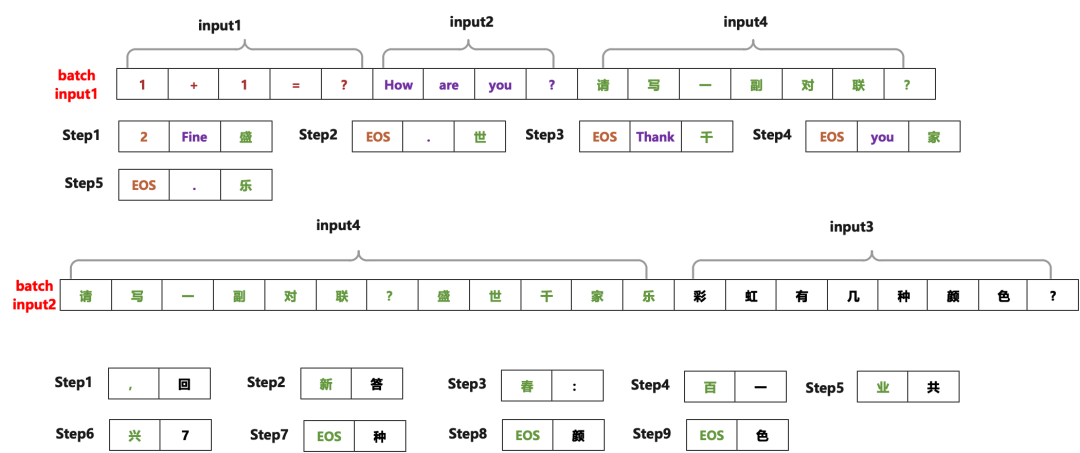
▲图九:启用新的调度策略之后的推理
采用新的调度逻辑后,这个案例的 step 数从原来的 20 步减少到 14 步;在实际的业务生产过程中,这个 step 的减少数远远大于案例中的 case。我们通过实践发现,在我们的业务中采用上述算法,服务的每秒查询率(QPS)一般有 2-3 倍以上的提升。
一般情况下,优化 prompt 可以提升模型的效果,案例如下:

上述案例是让大模型判断一段文字的正确性,如果错误则说明理由。在实际服务的生产过程中,对于回答是正确的 case,输出的 token 数是 1,对于回答错误的 case,输出的 token 数可能很大,如 Dynamic Batch 一节分析的那样,当输出的长度差别很大的时候,推理过程中产生的气泡会很大,这种情况将造成严重的算力浪费。为了解决该问题,我们可以将问题进行分解,例如对大模型提问两次,第一次让大模型判断问题的正确性,第二次针对事实错误的 case 问大模型原因。

在实际业务实践中,对于这类模式的问题采用上述策略,部分业务的吞吐提升 10 倍以上。
我们的模型量化大部分都是基于NVIDIA TensorRT Model Optimizer(简称ModelOpt,原名AMMO)做的。 ModelOpt 提供了简明易用的接口,可以对各种第三方模型进行训练后量化 (PTQ),并跟 TensorRT-LLM 实现良好衔接。
大模型的参数相对较大,占用的显存较多,并且大模型在 generate 过程中 KVCache 也需要占用大量的显存,如果对模型的参数及 KVCache 进行量化,可以显著节省显存,进而在实际服务推理过程中增大服务的 batch_size, 提升服务的吞吐量。而量化的核心是获得一个对应的缩放系数,具体公式如下:
Q = R/S + Z, (Quantize)
R = S * (Q-Z), (Dequantize)
如上述公式所表达的那样,模型量化的本质是将一个 FP32 或者 FP16 的数据映射到一个更低 bit 数值区间,进而减少了数据在 memory 间传输的耗时,然后基于不同的算法使用不同数据精度矩阵乘的硬件(如 Int8 的 Tensor Core),最后反量化回原来的数据精度。
在大模型量化实践中,我们主要尝试了对称量化的方法。
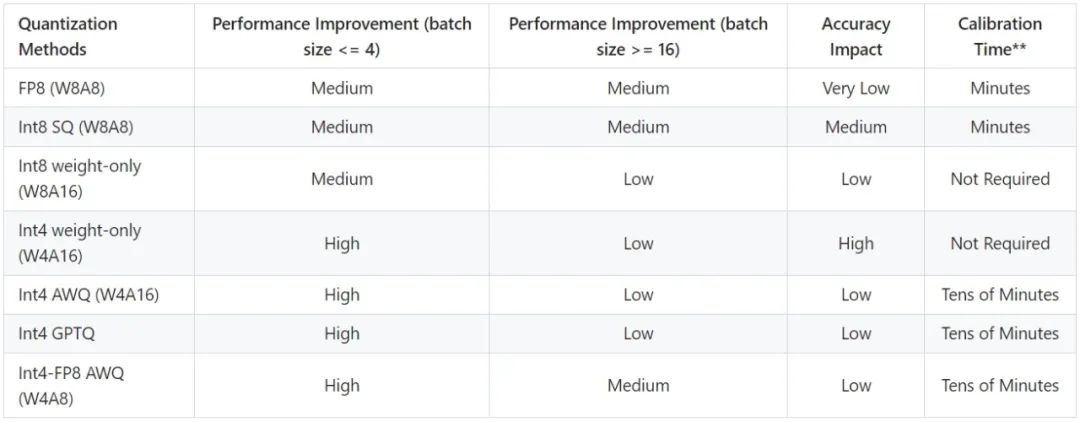
-
SmoothQuant int8,该算法认为:常见模型的 X (或者是activation) 存在 outlier 的现象。如果使用 int8 weight only 等方式进行量化,只能利用 FP16 的 Tensor Core,不能使用 int8 的 Tensor Core,也就意味着不能使用同一硬件下的更强算力。
SmoothQuant 的方法是找出一个平滑因子,将模型计算改成:
 ,通过使用平滑因子 s,解决掉 outlier 的数值问题,进而利用 8bit 的 TensorCore 或者 CudaCore 提升 GEMM 的性能的同时达到精度损失较小的目标。
,通过使用平滑因子 s,解决掉 outlier 的数值问题,进而利用 8bit 的 TensorCore 或者 CudaCore 提升 GEMM 的性能的同时达到精度损失较小的目标。
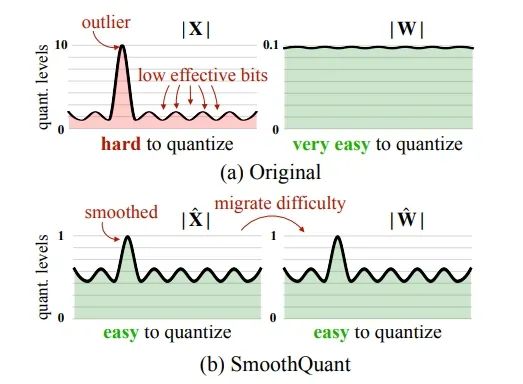
▲图十:SmoothQuant 原理【4】










