作者: louwill 公众号:数据科学家养成记(louwill12)
随着大数据时代的到来和数据的市场价值得到认可,数据分析师、进阶一点的还有数据挖掘工程师、甚至是金字塔顶尖的数据科学家,这些作为21世纪最性感的职业已成功吸引无数像笔者这样的热血小青年,阿里的一句“开启AI时代”的口号就足以让我等激动的准备把此身奉献给高大上的数据科学行业。除去像计算机、数学和统计学这些科班出身的童鞋,想要转行投身数据分析的其他行业人士也绝不在少数。但数据分析到底是什么、想要成为一名数据行业的从业者又要具备哪些素质,恐怕这才是大家真正需要关注的焦点。笔者花了一些时间,从数据采集到清洗、分析,从可视化到数据的深度挖掘,一整套数据分析处理流程给大家展示一下目前国内关于数据行业的招聘信息到底有些什么。
1、数据采集与清洗
在爬虫界似乎有这样的传言,每一个爬虫进阶者都会拿拉勾网作为自己练习爬虫的对象,一来锻炼爬虫技术,二来了解招聘信息,拉勾网和谐的结构化界面给大家抓取数据提供了天然的便利,颇受各位crawler的青睐。拉勾网招聘信息界面如下:
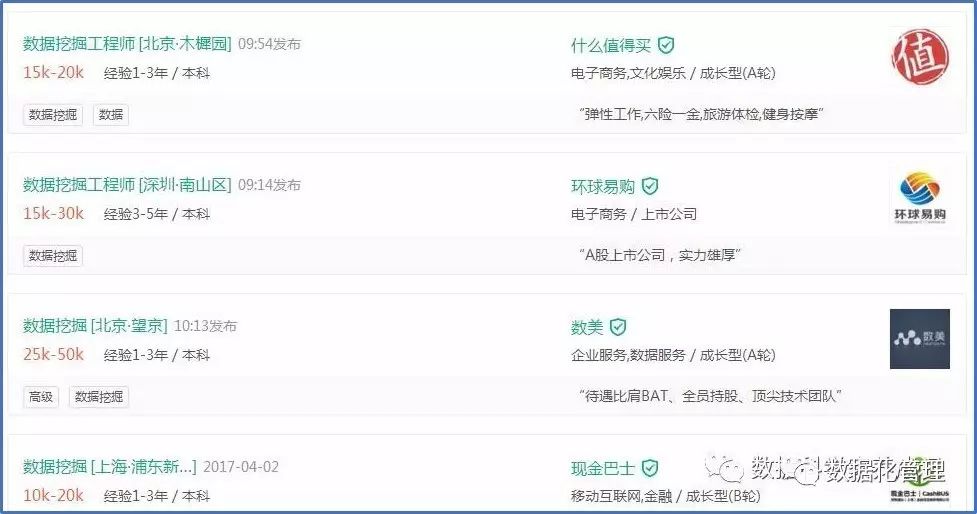
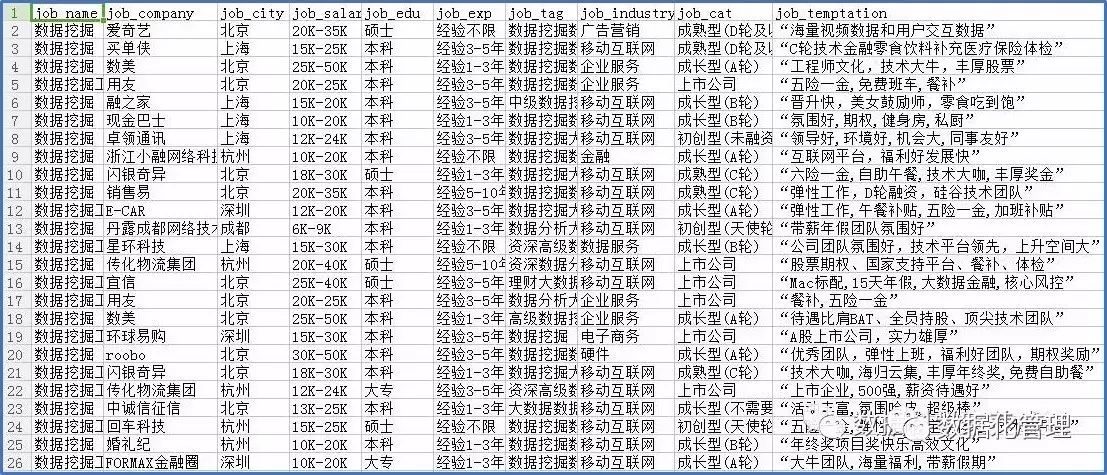
笔者以“数据分析”、“数据挖掘”、“数据运营”和“数据产品经理”为关键词在拉勾网上搜索了相关数据类职位,运用R语言中的Rvest包和Selectorgadget插件构建爬虫框架,按照岗位名称(job_name)、公司名称(job_company)、所在城市(job_city)、工资(job_salary)、学历要求(job_edu)、经验要求(job_exp)、职位标签(job_tag)、行业类别(job_industry)、公司融资阶段(job_cat)、职位福利(job_temptation)和任职要求(jd)为特征属性抓取和清洗数据,其中任职要求(JD)特征仅抓取了数据挖掘类岗位的职位描述。在剔除部分有缺失值和异常记录后整理得到拉勾网1605条数据类岗位招聘信息,数据局部展示如下:
2、数据分析与可视化展示
在进行分析之前先简单地对薪资(job_salary)这个字段进行处理,编写自定义R函数将其划分为0-5K,6-10K ,11-15K ,16-20K ,21-25K, 26-30K, 31-100K这七个区间以便后面的分析。
这里分析主要用到了ggplot2和plotrix这两个绘图包。
先来看看数据类岗位对学历的要求:
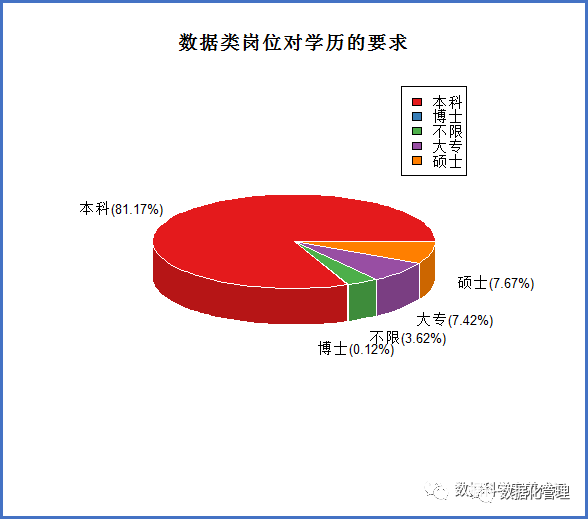
很明显,对于数据类岗位而言,本科学历要求是目前主流,硕士和专科学历也有一定比例,部分不限学历的岗位那一定是看重你的行业经验了,只有极少量的岗位是需要博士学历的,我们查询下数据便知:
job_phd
job_phd

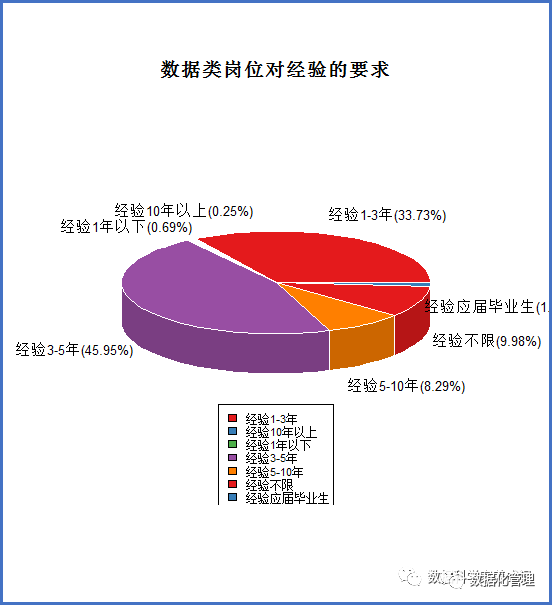
数据类岗位对于经验的要求:
目前国内数据类岗位主要分布在哪些城市?
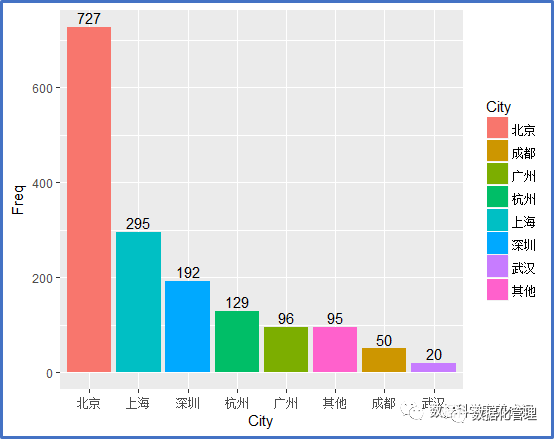
作为国内互联网行业较为发达的城市,北上广深杭所提供的数据类岗位数量占了全国将近90%的比例,而仅北京就占了一半的岗位提供数量,不得不惊叹帝都的互联网人才需求之大。上海作为国内经济金融中心,有着排名第二的数据类人才需求也无可厚非,杭州则由于阿里巴巴的加成,领衔一众互联网科技公司,数据分析人才需求也较为可观,广深相距不远,也有像腾讯这样的互联网大佬支撑,数据人才需求也是很大的。
想做数据分析的,可不要跑错了地方。
哪些行业需要数据分析人才?
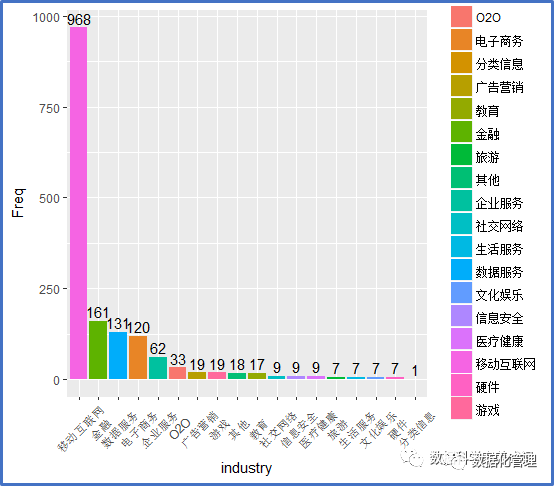
移动互联网和金融、电子商务行业为数据分析提供了大量的就业机会,数据行业的繁荣也相应的催生了专门提供数据服务的公司,这块也有较大需求。而传统行业对数据人才的需求目前并不显著,相信随着互联网+对传统行业的革命加深,越来越多的传统行业会对数据分析产生需求。
对数据分析人才有需求的企业都处在怎样的一个发展阶段?
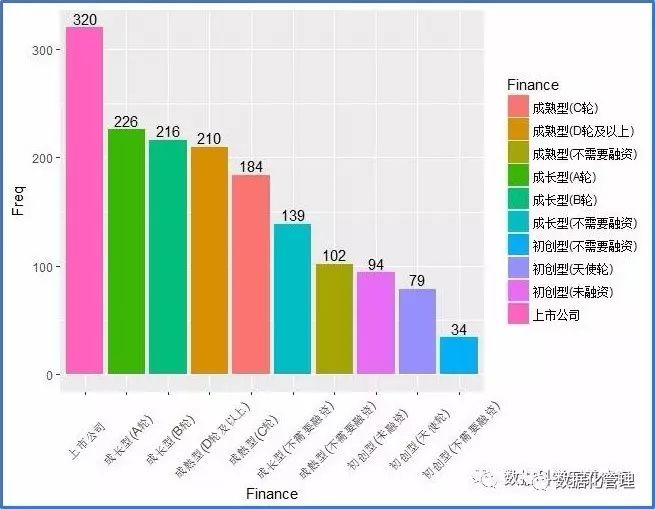
A轮以上融资的公司对数据岗位的需求相对较大,其中以上市公司为最。天使轮及其他不需要融资的企业规模较小,对数据分析与数据挖掘的需求也小很多。
丰富的数据从业经验是否就以为着30K以上的工资?
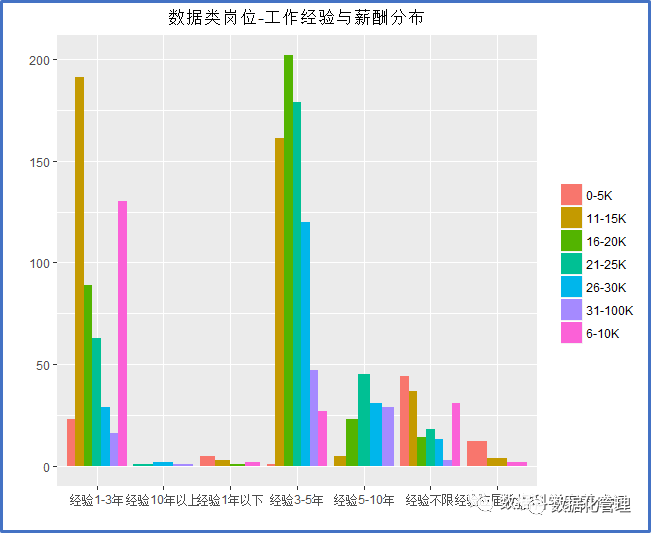
一个大家都乐意知晓的事实是,数据类岗位薪资通常都会有一个较高的起薪,高学历、零经验的应届毕业生拿到10K的薪资几乎已成常态,个别能力强的一段时间后拿到20K到30K的也大有人在。就数据行业而言,经验1-3年和3-5年是行业的香饽饽,数据分析与数据挖掘在国内兴起时间不长,很难有资深的数据科学从业者,经验5-10年就已可遇不可求,10年以上经验的业界大咖更是凤毛麟角。
数据行业高学历是否就意味着高薪资?
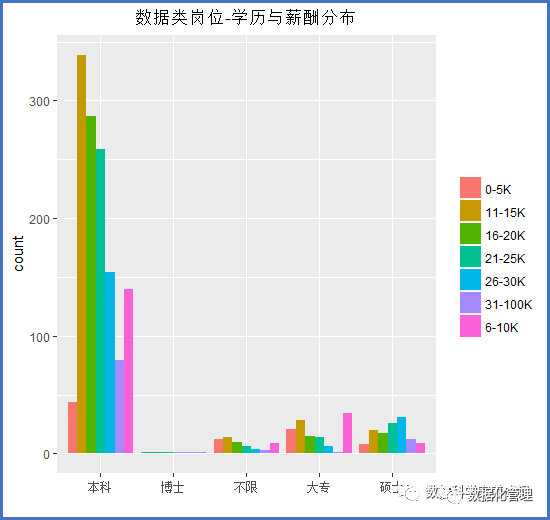
就像前述展示的一样,本科学历是数据行业资质的主流学历。相应的高学历也并一定意味着有超高薪的加成,本科学历且有一定的行业积累后拿到31-100K的薪资并不少见。
不同行业的开出的薪资分布有何区别?
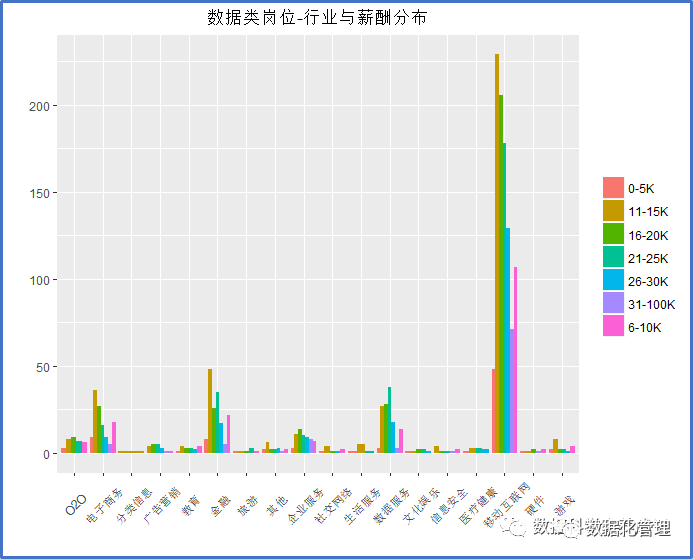
如前所述,数据岗位在移动互联网、金融、电子商务和数据服务行业有着较高的需求,而行业与薪酬分布图则再次展示了这一情况。
不同融资阶段的企业给出的薪资分布有何差异?
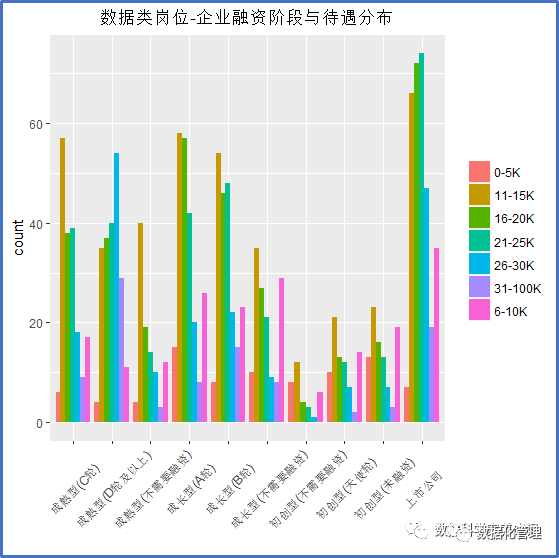
初创型(天使轮)、初创型(未融资)和初创型(不需要融资)等企业发展初期和小规模状态下给数据人才开出的工资要明显低于其他融资阶段的企业开出的薪资水平。成熟型(D轮及以上)和上市公司则明显财大气粗,对数据人才也敢于挥金如土。
3、职位福利与数据技能要求的挖掘
笔者将job_temptation和job_JD这两个字段分别抽取出来各自读入R语言中,用jiebaR包进行分词处理,然后进行词频统计,再利用wordcloud2绘制词云图,向大家展示数据行业的企业能给求职者带来怎样的福利和软件技能要求。
数据岗位福利关键词词云图:

团队、五险一金、发展空间、弹性工作时间、期权等成为企业招聘数据人才的高频诱惑词语。
数据科学行业职位技能要求词云展示:

剔除了数据挖掘和数据分析等大频干扰词之后的词云图:

将上图转化为我们熟悉的条形图形式,技能要求一目了然。所以,当我们在谈论数据挖掘时,我们谈论的是如下内容。
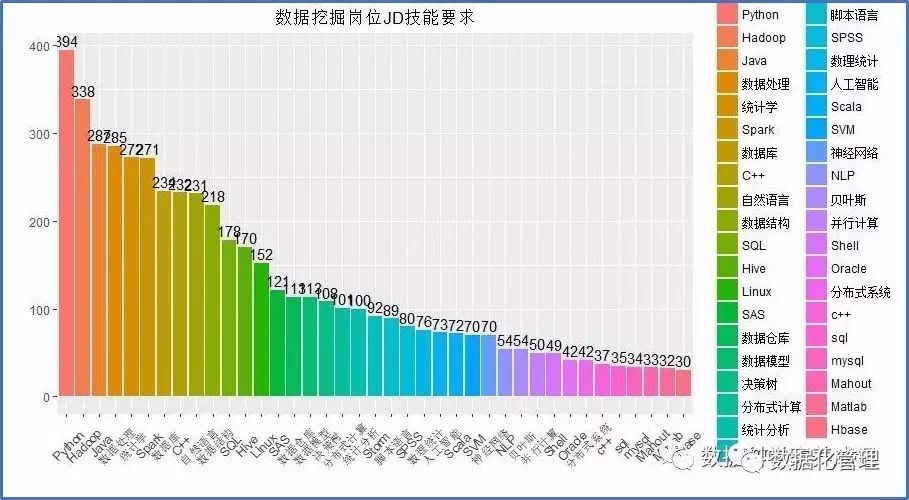
Python、R、Hadoop、Java、Spark、C++、SQL、Linux、Hive
等数据科学工具和编程语言是企业对数据人才的一致要求,一些如统计分析、数据结构以及决策树理论概念和算法也在企业对数据人才的要求之列,各位想找数据挖掘工作,可留点心呐!好好学理论,认真练技术,高薪不再远!(图中并没有R的频数,原因是笔者在分词的时候因R的单个字符难以与其他工具一起分词,故而这里没有出现R,实际上,R在JD中出现的频次有370次,仅次于Python,所以
R和Python
是数据科学从业者两把利剑,愿各位好好打磨。)
全流程实现代码:
#加载所需要的包
library(xml2)
library(rvest)
library(ggplot2)
library(stringr)
library(dplyr)
library(plotrix)
library(RColorBrewer)
library(jiebaR)
library(wordcloud2)
#对爬取页数进行设定并创建数据框
i
job_inf
#使用for循环进行批量数据爬取
for (i in 1:30){
web
job_name%html_nodes("h2")%>%html_text()
job_name[16]
job_name
job_company%html_nodes(".company_name a")%>%html_text()
job_city%html_nodes("em")%>%html_text()
job_city[16]
job_city[17]
job_city
job_inf1%html_nodes(".p_bot .li_b_l")%>%html_text()
job_tag%html_nodes(".list_item_bot .li_b_l")%>%html_text()
job_inf2%html_nodes(".industry")%>%html_text()
job_temptation%html_nodes(".li_b_r")%>%html_text()
#创建数据框存储以上信息
job
job_inf
}
#将数据写入csv文档
write.csv(job_inf,file="D:/Rdata/datasets/job_inf.csv")
#读取数据
jobdata
head(jobdata)
attach(jobdata)
#处理job_salary字段
job_salary
attributes(job_salary)
thresholds
c("1K-2K","2K-3K","2K-4K","3K-4K","3K-5K","3K-6K",
"4K-6K","4K-7K","4K-5K"),
c("4K-8K","5K-6K","5K-7K","5K-8K","5K-9K","5K-10K","6K-10K","6K-12K",
"6K-8K","6K-9K","7K-10K","7K-12K","7K-13K","7K-14K","7K-8K","7K-9K",
"8K-10K","8K-12K","8K-13K"),
c("8K-14K","8K-15K","8K-16K","9K-13K","9K-15K","9K-16K",
"9K-18K","10K-12K","10K-14K","10K-15K","10K-16K","10K-17K","10K-18K",
"10K-19K","10K-20K","11K-15K","12K-15K","12K-16K","12K-18K"),
c("12K-20K","12K-22K","12K-24K","13K-18K","13K-19K",
"13K-20K","13K-22K","13K-23K","13K-25K","13K-26K","14K-17K","14K-20K",
"14K-25K","14K-27K","14K-28K","15K-18K","15K-20K","15K-22K","15K-25K",
"15K-26K","16K-20K"),
c("15K-28K","15K-30K","16K-24K","16K-28K","16K-30K","16K-32K","18K-22K",
"18K-25K","18K-28K","18K-30K","20K-25K","20K-28K","20K-30K"),
c("17K-33K","17K-34K","18K-35K","18K-36K",
"19K-38K","20K-35K","20K-38K","20K-40K","25K-30K","25K-35K"),
c("21K-42K","22K-40K","23K-45K","24K-35K","25K-40K","25K-45K","25K-50K",
"28K-35K","30K-35K","30K-40K","30K-45K","30K-50K","28K-55K",
"30K-60K","35K-40K","35K-50K","35K-55K","35K-70K",
"40K-60K","40K-80K")
)
#工资分为下面这七个区间
job_salaries
GetSalaryMapping
job_salary
result
for(i in 1:length(thresholds)){
result
if(length(result) != 0){
return(job_salaries[i])
break
}
}
return(job_salary)
}
#替换掉原来的job_salary列
jobdata$job_salary
job_salary
#数据岗位对学历的要求
education
education.qualifications
myLabel
pie3D(
x = education$Freq, labels = myLabel,
explode= 0,
radius = 0.85,
height = 0.11,
border = "white", col = brewer.pal(5,"Set1"),
labelcex = 0.85,
main = "数据类岗位对学历的要求"
)
legend("topright",inset=0.02,legend=c("本科","博士","不限","大专","硕士"),
cex=0.8,fill=brewer.pal(5,"Set1"))
#数据岗位对经验的要求
experience
experience.qualifications
myLabel
pie3D(
x = experience$Freq, labels = myLabel,
explode= 0,
radius = 0.85,
height = 0.11,
border = "white", col = brewer.pal(5,"Set1"),
labelcex = 0.85,
main = "数据类岗位对经验的要求"
)
legend("bottom",inset=-0.03,legend=c("经验1-3年","经验10年以上","经验1年以下",
"经验3-5年","经验5-10年","经验不限","经验应届毕业生"),cex=0.66,fill=brewer.pal(5,"Set1"))
#数据类岗位城市分布
count.city
names(count.city)
count.city
rownames(count.city)
#从第8位开始的城市都归为其他
tmp
count.city
count.city
City = "其他",
Freq = sum(tmp$Freq)
))
count.city
attach(count.city)
ggplot(count.city,aes(reorder(City,-Freq),Freq,fill=City))+geom_bar(stat="identity")+xlab(
"City")+geom_text(aes(label=Freq),hjust=0.5,vjust=-0.3)
#公司融资状况分布
company.finance
names(company.finance)
company.finance
attach(company.finance)
ggplot(company.finance,aes(reorder(Finance,-Freq),Freq,fill=Finance))+geom_bar(stat="identity")+xlab(
"Finance")+geom_text(aes(label=Freq),hjust=0.5,vjust=-0.3)+theme(axis.text.x =
element_text(vjust = 0.5,hjust = 0.5,angle = 45))
#行业分布
attach(jobdata)
industry
industry
industry
rownames(industry)
ggplot(industry,aes(reorder(industry,-Freq),Freq,fill=industry))+geom_bar(stat="identity")+xlab(
"industry")+geom_text(aes(label=Freq),hjust=0.5,vjust=-0.3)+theme(axis.text.x =
element_text(vjust = 0.5,hjust = 0.5,angle = 45))
#工作经验与薪酬分布
ggplot(jobdata, aes(x = job_exp, fill = job_salary)) +
geom_bar(stat = "count", position = "dodge") +
theme_grey() + labs(x = "", y = "") +
theme(legend.title = element_blank()) +
ggtitle("数据类岗位-工作经验与薪酬分布") +
theme(plot.title = element_text(hjust = 0.5))
#行业与薪酬分布
ggplot(jobdata, aes(x = job_industry, fill = job_salary)) +
geom_bar(stat = "count", position = "dodge") +
theme_grey() + labs(x = "", y = "") +
theme(legend.title = element_blank()) +
ggtitle("数据类岗位-行业与薪酬分布") +
theme(plot.title = element_text(hjust = 0.5))+
theme(axis.text.x =
element_text(vjust = 0.5,hjust = 0.5,angle = 45))
#学历与薪酬分布
ggplot(jobdata, aes(x = job_edu, fill = job_salary)) +
geom_bar(stat = "count", position = "dodge") +
theme_grey() + labs(x = "", y = "count") +
theme(legend.title = element_blank()) +
ggtitle("数据类岗位-学历与薪酬分布") +
theme(plot.title = element_text(hjust = 0.5))
#企业融资阶段与待遇分布
ggplot(jobdata, aes(x = job_cat, fill = job_salary)) +
geom_bar(stat = "count", position = "dodge") +
theme_grey() + labs(x = "", y = "count") +
theme(legend.title = element_blank()) +
ggtitle("数据类岗位-企业融资阶段与待遇分布") +
theme(plot.title = element_text(hjust = 0.5))+
theme(axis.text.x =
element_text(vjust = 0.5,hjust = 0.5,angle = 45))
#职位福利的分析与挖掘
tp
tp
head(tp)
#分词
Mixseg
tp
length(tp)
tp1 & nchar(tp)<10]
tp_word
#职位福利词云图
wordcloud2(tp_word, size = 1,shape = 'pentagon')
#职位描述的分析与挖掘
jd
head(jd)
#分词
mixseg
jd
length(jd)
jd2 & nchar(jd)<8]
jd_word
#职位描述词云图
wordcloud2(jd_word, size = 1,shape = 'pentagon')
#去除数据挖掘和数据分析两个高频词之后的词云
jd_word[1]
jd_word[2]
jd_word2
wordcloud2(jd_word2, size = 1,shape = 'pentagon')
#生成高频词的条形图
jd_word[c(3,4,6,7,9,18,20,21,26,29,31,32,33,35,37,39,42,43,44,49,55,56,
57,59,60,61,62,63,64,66,67,68,69,70,72,74,75,76,77,80,83,84,86,88,89,90,91,
92,94,95,96,97,98,99,100)]
jd_word3
jd_word3
ggplot(jd_word3, aes(x =jd_word3$jd, y = jd_word3$Freq, fill = jd)) +
geom_bar(stat = "identity") +
labs(x = "", y = "") +
theme(axis.text.x =
element_text(vjust = 0.5,hjust = 0.5,angle = 45))+
geom_text(aes(label=Freq),hjust=0.5,vjust=-0.3) +
ggtitle("数据挖掘岗位JD高频词") +
theme(plot.title = element_text(hjust = 0.5))
#进行关联的分析
#企业对不同工作资历的应聘者的要求情况
workyear.empty
workyear.freshman
workyear.oneyear
workyear.threeyear
workyear.fiveyear
workyear.tenyear
workyear.overtenyear
参考资料:
1 数据分析师职业发展白皮书(2015年版)
2 https://github.com/edvardHua/JobRequirementAnalysis.

近期优质文章推荐:
伦敦开了个可以用个人数据购买商品的店铺,这个脑洞有点大
数据告诉你,是谁准备买iPhone?
动态仪表板,Excel也能玩
如何看穿数据可视化的谎言?
销售团队建设与管理|打造高绩效的销售团队培训





