在刚刚结束的 2017 年国际高性能微处理器研讨会(Hot Chips 2017)上,微软、百度、英特尔等公司都发布了一系列硬件方面的新信息,比如微软的 Project Brainwave、百度的 XPU、英特尔的 14nm FPGA 解决方案等。谷歌也不例外,在大会 keynote 中 Jeff Dean 介绍了人工智能近期的发展及其对计算机系统设计的影响,同时他也对 TPU、TensorFlow 进行了详细介绍。文末提供了该演讲资料的下载地址。
在演讲中,Jeff Dean 首先介绍了深度学习的崛起(及其原因),谷歌在自动驾驶、医疗健康等领域取得的最新进展。
Jeff Dean 表示,随着深度学习的发展,我们需要更多的计算能力,而深度学习也正在改变我们设计计算机的能力。
我们知道,谷歌设计了 TPU 专门进行神经网络推断。Jeff Dean 表示,TPU 在谷歌产品中的应用已经超过了 30 个月,用于搜索、神经机器翻译、DeepMind 的 AlphaGo 系统等。
但部署人工智能不只是推断,还有训练阶段。TPU 能够助力推断,我们又该如何加速训练?训练的加速非常的重要:无论是对产品化还是对解决大量的难题。
为了同时加速神经网络的推断与训练,谷歌设计了 TPU 二代。TPU 二代芯片的性能如下图所示:
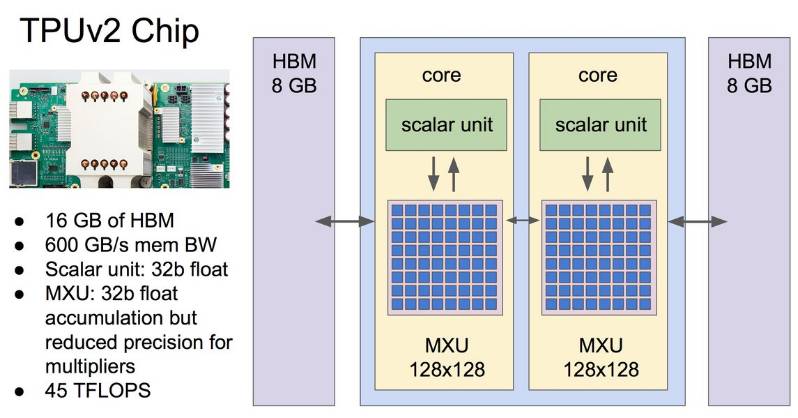
除了上图所述意外,TPU 二代的特点还有:
下图是 TPU 组成的大型配置:由 64 块 TPU 二代组成,每秒 11.5 千万亿次浮点运算,4 太字节的 HBM 存储。

在拥有强大的硬件之后,我们需要更强大的深度学习框架来支持这些硬件和编程语言,因为快速增长的机器学习和深度学习需要硬件和软件都能具备强大的扩展能力。因此,Jeff Dean 还详细介绍了最开始由谷歌开发的深度学习框架 TensorFlow。
深度学习框架 TensorFlow

TensorFlow 是一种采用数据流图(data flow graphs),用于数值计算的开源软件库。其中 Tensor 代表传递的数据为张量(多维数组),Flow 代表使用计算图进行运算。数据流图用「节点」(nodes)和「边」(edges)组成的有向图来描述数学运算。
TensorFlow 的目标是建立一个可以表达和分享机器学习观点与系统的公共平台。该平台是开源的,所以它不仅是谷歌的平台,同时是所有机器学习开发者和研究人员的平台,谷歌和所有机器学习开源社区的研究者都在努力使 TensorFlow 成为研究和产品上最好的机器学习平台。
下面是 TensorFlow 项目近年来在 Github 上的关注度,我们可以看到 TensorFlow 是所有同类深度学习框架中关注度最大的项目。
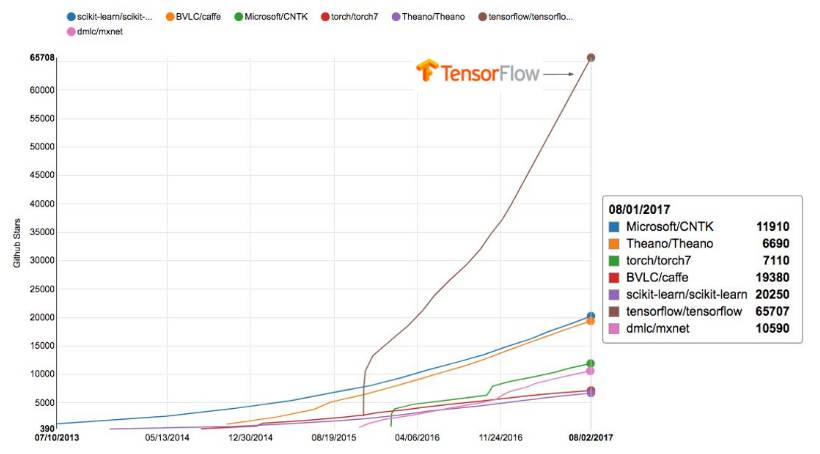
TensorFlow:一个充满活力的开源社区
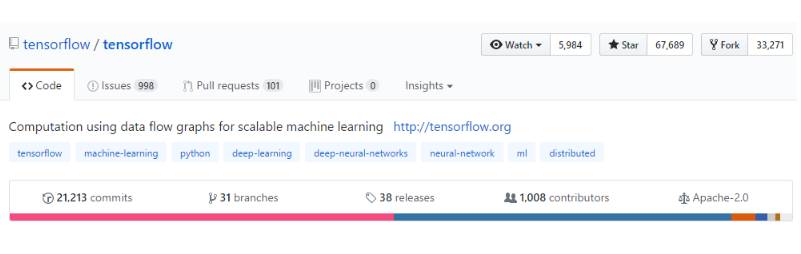
TensorFlow 发展迅速,有很多谷歌外部的开发人员
-
超过 800 多位 TensorFlow 开发人员(非谷歌人员)。
-
21 个月内 Github 上有超过 21000 多条贡献和修改。
-
许多社区编写了 TensorFlow 的教程、模型、翻译和项目
-
超过 16000 个 Github 项目在项目名中包含了「TensorFlow」字段
社区与 TensorFlow 团队之间的直接联合
通过 TensorFlow 编程
在 TensorFlow 中,一个模型可能只需要一点点修改就能在 CPU、GPU 或 TPU 上运行。前面我们已经看到 TPU 的强大之处,Jeff Dean 表明,对于从事开放性机器学习研究的科学家,谷歌可以免费提供 1000 块云 TPU 来支持他们的研究。Jeff Dean 说:「我们很高兴研究者能在更强劲的计算力下进行更杰出的研究」
TensorFlow Research Cloud 申请地址:https://services.google.com/fb/forms/tpusignup/
机器学习需要在各种环境中运行,我们可以在下面看到 TensorFlow 所支持的各种平台和编程语言。

除此之外,TensorFlow 还支持各种编程语言,如 Python、C++、Java、C#、R、Go 等。
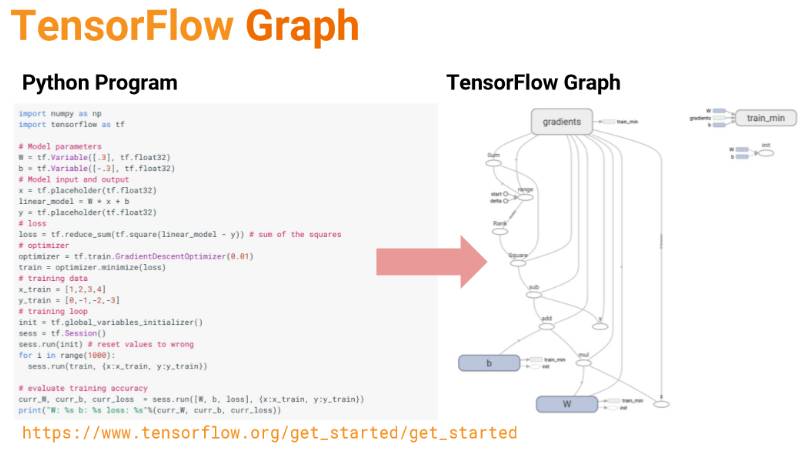
TensorFlow 非常重要的一点就是计算图,我们一般需要先定义整个模型需要的计算图,然后再执行计算图进行运算。在计算图中,「节点」一般用来表示施加的数学操作,但也可以表示数据输入的起点和输出的终点,或者是读取/写入持久变量(persistent variable)的终点。边表示节点之间的输入/输出关系。这些数据边可以传送维度可动态调整的多维数据数组,即张量(tensor)。
如下是使用 TensorFlow 和 Python 代码定义一个计算图:
在 Tensorflow 中,所有不同的变量和运算都储存在计算图。所以在我们构建完模型所需要的图之后,还需要打开一个会话(Session)来运行整个计算图。在会话中,我们可以将所有计算分配到可用的 CPU 和 GPU 资源中。
如下所示代码,我们声明两个常量 a 和 b,并且定义一个加法运算。但它并不会输出计算结果,因为我们只是定义了一张图,而没有运行它:
a=tf.constant([1,2],name="a")
b=tf.constant([2,4],name="b")
result = a+b
print(result)
#输出:Tensor("add:0", shape=(2,), dtype=int32)
下面的代码才会输出计算结果,因为我们需要创建一个会话才能管理 TensorFlow 运行时的所有资源。但计算完毕后需要关闭会话来帮助系统回收资源,不然就会出现资源泄漏的问题。下面提供了使用会话的两种方式:
a=tf.constant([1,2,3,4])
b=tf.constant([1,2,3,4])
result=a+b
sess=tf.Session()
print(sess.run(result))
sess.close
#输出 [2 4 6 8]





