(点击
上方蓝字
,快速关注我们)
来源:伯乐在线专栏作者 - iPytLab
http://python.jobbole.com/87621/
如有好文章投稿,请点击 → 这里了解详情
前言
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. – Donald Knuth
先扔上一句名言来镇楼。
当我们的确是有需要开始真正优化我们的Python程序的时候,我们要做的第一步并不是盲目的去做优化,而是对我们现有的程序进行分析,发现程序的性能瓶颈进而进行针对性的优化。这样才会使我们花时间和精力去做的优化获得最大的效果。
本文主要介绍Python内置的性能分析器的优雅使用方法,并以作者的一个化学动力学的程序为例子进行性能分析实践, 介绍了常用的性能分析可视化工具的使用,最后对Python程序进行初步的性能优化尝试。
正文
关于性能分析
性能分析就是分析代码和正在使用的资源之间有着怎样的联系,它可以帮助我们分析运行时间从而找到程序运行的瓶颈,也可以帮助我们分析内存的使用防止内存泄漏的发生。
帮助我们进行性能分析的工具便是性能分析器,它主要分为两类:
基于事件的性能分析(event-based profiling)
统计式的性能分析(statistical profiling)
关于性能分析详细的概念参考: 性能分析-维基百科
Python的性能分析器
Python中最常用的性能分析工具主要有:cProfiler, line_profiler以及memory_profiler等。他们以不同的方式帮助我们分析Python代码的性能。我们这里主要关注Python内置的cProfiler,并使用它帮助我们分析并优化程序。
cProfiler
快速使用
这里我先拿上官方文档的一个简单例子来对cProfiler的简单使用进行简单介绍。
import
cProfile
import
re
cProfile
.
run
(
're.compile("foo|bar")'
)
分析结果:
197
function
calls
(
192
primitive
calls
)
in
0.002
seconds
Ordered
by
:
standard name
ncalls tottime percall cumtime percall
filename
:
lineno
(
function
)
1
0.000
0.000
0.001
0.001
<
string
>:
1
(
<
module
>
)
1
0.000
0.000
0.001
0.001
re
.py
:
212
(
compile
)
1
0.000
0.000
0.001
0.001
re
.py
:
268
(
_compile
)
1
0.000
0.000
0.000
0.000
sre_compile
.py
:
172
(
_compile_charset
)
1
0.000
0.000
0.000
0.000
sre_compile
.py
:
201
(
_optimize_charset
)
4
0.000
0.000
0.000
0.000
sre_compile
.py
:
25
(
_identityfunction
)
3
/
1
0.000
0.000
0.000
0.000
sre_compile
.py
:
33
(
_compile
)
从分析报告结果中我们可以得到很多信息:
-
整个过程一共有197个函数调用被监控,其中192个是原生调用(即不涉及递归调用)
-
总共执行的时间为0.002秒
-
结果列表中是按照标准名称进行排序,也就是按照字符串的打印方式(数字也当作字符串)
-
在列表中:
-
ncalls表示函数调用的次数(有两个数值表示有递归调用,总调用次数/原生调用次数)
-
tottime是函数内部调用时间(不包括他自己调用的其他函数的时间)
-
percall等于 tottime/ncalls
-
cumtime累积调用时间,与tottime相反,它包含了自己内部调用函数的时间
-
最后一列,文件名,行号,函数名
优雅的使用
Python给我们提供了很多接口方便我们能够灵活的进行性能分析,其中主要包含两个类cProfile模块的Profile类和pstat模块的Stats类。
我们可以通过这两个类来将代码分析的功能进行封装以便在项目的其他地方能够灵活重复的使用进行分析。
这里还是需要对Profile以及Stats的几个常用接口进行简单总结:
Profile类:
-
enable(): 开始收集性能分析数据
-
disable(): 停止收集性能分析数据
-
create_stats(): 停止收集分析数据,并为已收集的数据创建stats对象
-
print_stats(): 创建stats对象并打印分析结果
-
dump_stats(filename): 把当前性能分析的结果写入文件(二进制格式)
-
runcall(func, *args, **kwargs): 收集被调用函数func的性能分析数据Stats类
Stats类
import
pstats
p
=
pstats
.
Stats
(
'stats.prof'
)
Stats类可以接受stats文件名,也可以直接接受cProfile.Profile对象作为数据源。
-
strip_dirs(): 删除报告中所有函数文件名的路径信息
-
dump_stats(filename): 把stats中的分析数据写入文件(效果同cProfile.Profile.dump_stats())
-
sort_stats(*keys): 对报告列表进行排序,函数会依次按照传入的参数排序,关键词包括calls, cumtime等,具体参数参见https://docs.python.org/2/library/profile.html#pstats.Stats.sort_stats
-
reverse_order(): 逆反当前的排序
-
print_stats(*restrictions): 把信息打印到标准输出。*restrictions用于控制打印结果的形式, 例如(10, 1.0, ".*.py.*")表示打印所有py文件的信息的前10行结果。
有了上面的接口我们便可以更
优雅
的去使用分析器来分析我们的程序,例如可以通过写一个
带有参数的装饰器
,这样想分析项目中任何一个函数,便可方便的使用装饰器来达到目的。
import
cProfile
import
pstats
import
os
# 性能分析装饰器定义
def
do_cprofile
(
filename
)
:
"""
Decorator for function profiling.
"""
def
wrapper
(
func
)
:
def
profiled_func
(
*
args
,
**
kwargs
)
:
# Flag for do profiling or not.
DO_PROF
=
os
.
getenv
(
"PROFILING"
)
if
DO_PROF
:
profile
=
cProfile
.
Profile
()
profile
.
enable
()
result
=
func
(
*
args
,
**
kwargs
)
profile
.
disable
()
# Sort stat by internal time.
sortby
=
"tottime"
ps
=
pstats
.
Stats
(
profile
).
sort_stats
(
sortby
)
ps
.
dump_stats
(
filename
)
else
:
result
=
func
(
*
args
,
**
kwargs
)
return
result
return
profiled_func
return
wrapper
这样我们可以在我们想进行分析的地方进行性能分析, 例如我想分析我的MicroKineticModel类中的run方法:
class
MicroKineticModel
(
km
.
KineticModel
)
:
# ...
# 应用装饰器来分析函数
@
do_cprofile
(
"./mkm_run.prof"
)
def
run
(
self
,
**
kwargs
)
:
# ...
装饰器函数中通过sys.getenv来获取环境变量判断是否需要进行分析,因此可以通过设置环境变量来告诉程序是否进行性能分析:
export
PROFILING
=
y
# run the program...
程序跑完后便会在当前路径下生成mkm_run.prof的分析文件,我们便可以通过打印或者可视化工具来对这个函数进行分析。
性能分析实践
下面我就通过分析自己的动力学程序中MicroKineticModel类中的方法来进行实践,并使用常用的几种性能分析可视化工具来帮助分析并进行初步的优化和效率对比。
注: 本次测试的程序主要包含数值求解微分方程以及牛顿法求解多元非线性方程组的求解,其中程序中的公式推导部分全部通过字符串操作完成。
生成性能分析报告
按照上文的方法,我们通过装饰器对run方法进行修饰来进行性能分析,这样我们便可以像正常一样去跑程序,但是不同的是当前路径下会生成性能分析报告文件。
# 设置环境变量
export
PROFILING
=
y
# 执行运行脚本
python
run
.
py
在看似正常的运行之后,在当前路径下我们会生成一个分析报告, mkm_run.prof, 它是一个二进制文件,我们需要用python的pstats模块的接口来读取。
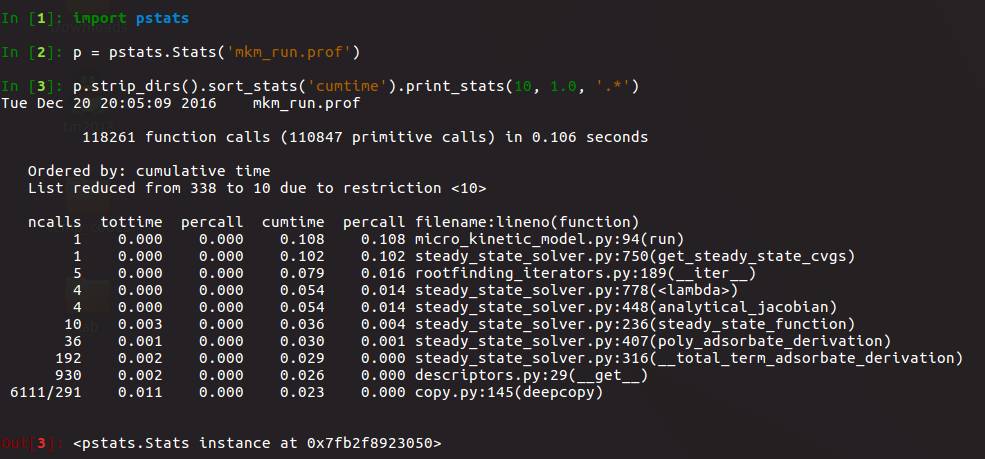
我们只按照累积时间进行降序排序并输出了前十行,整个函数只运行了0.106秒。可见程序大部分时间主要花在牛顿法求解的过程中,其中获取解析Jacobian Matrix的过程是一个主要耗时的部分。
虽然我们可以通过命令行查看函数调用关系,但是我并不想花时间在反人类的黑白框中继续分析程序,下面我打算上直观的可视化工具了。
分析数据可视化
gprof2dot
Gprof2Dot可将多种Profiler的数据转成Graphviz可处理的图像表述。配合dot命令,即可得到不同函数所消耗的时间分析图。具体使用方法详见: https://github.com/jrfonseca/gprof2dot
因此我们可以利用它来为我们的程序生成分析图:
gprof2dot -f pstats mkm_run.prof | dot -Tpng -o mkm_run.png
于是我们路径下面就生成了mkm_run.png
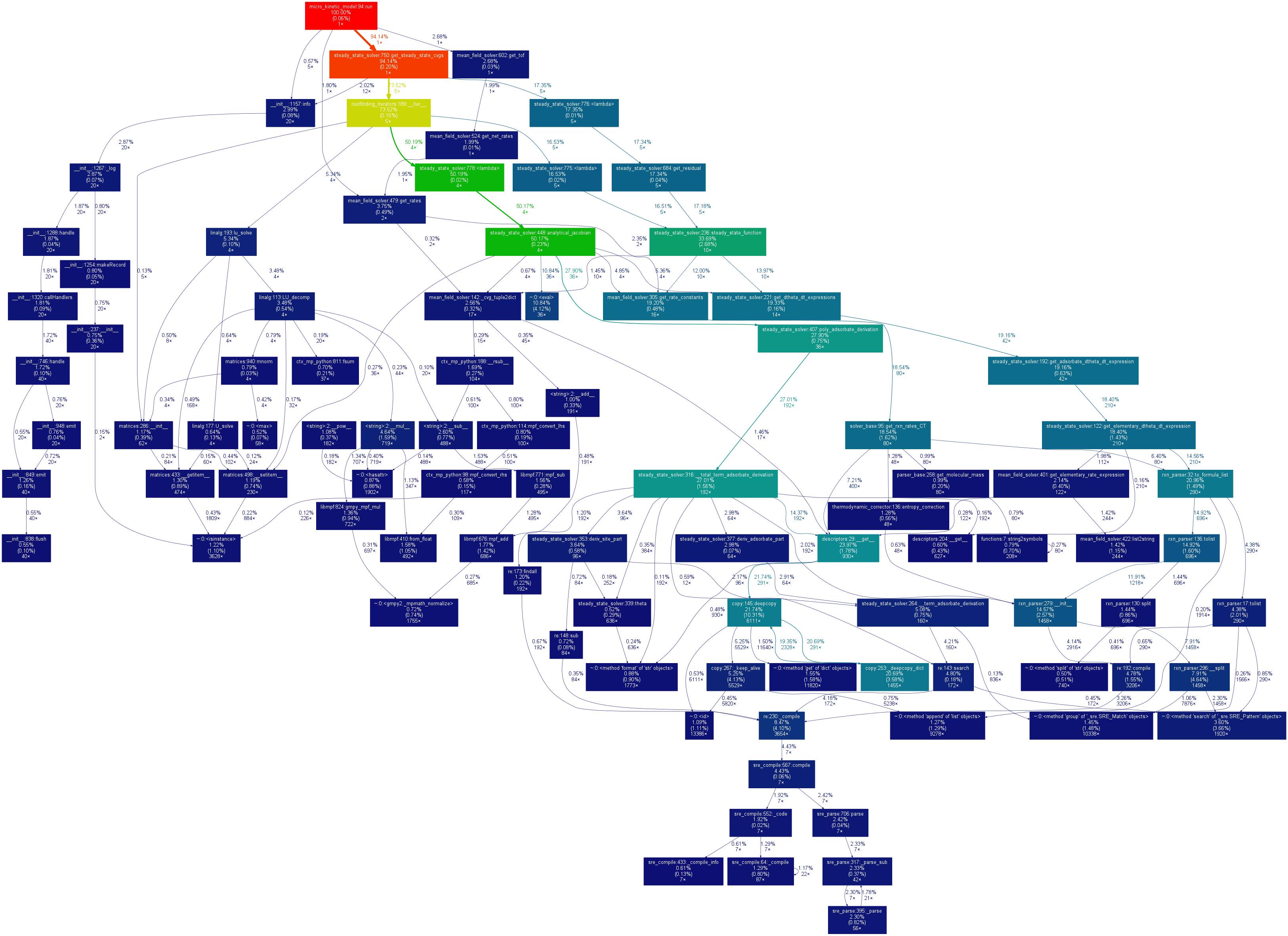
我倒是蛮喜欢这个时间分析图,顺着浅色方格的看下去很容易发现程序的瓶颈部分,
每个node的信息如下:

每个edge的信息如下:

vprof
也是一个不错的工具来提供交互式的分析数据可视化,详情参见: https://github.com/nvdv/vprof
他是针对文件进行执行并分析,并在浏览器中生成可视化图标
# 生成CPU flame图
vprof
-
c
c
run
.py
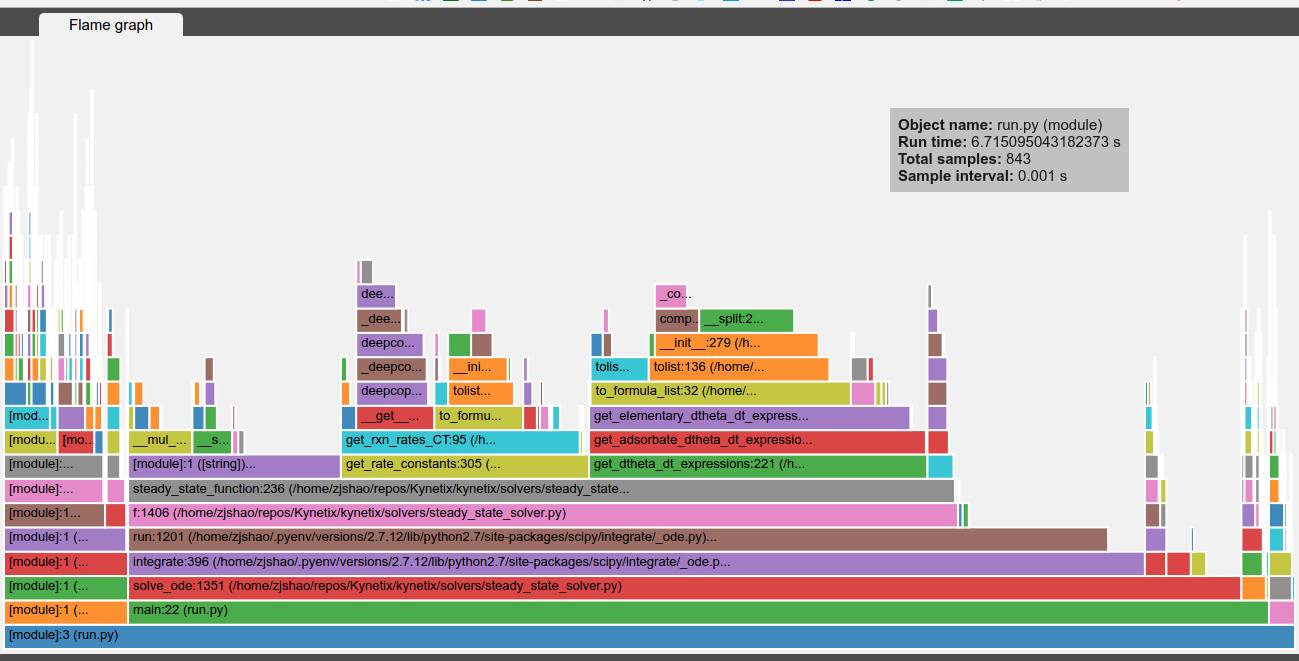
RunSnakeRun
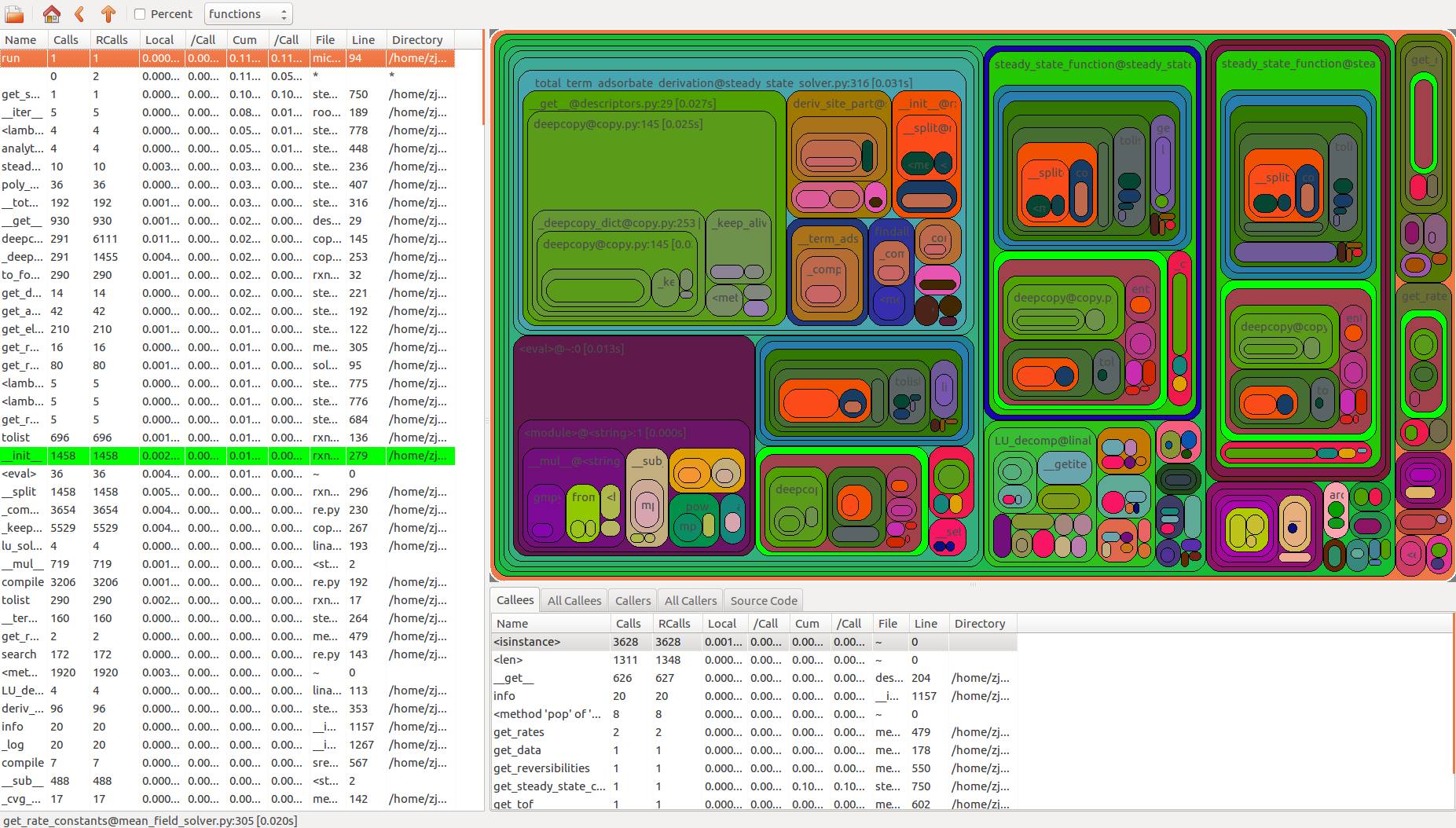
RunSnakeRun是另一个可对性能分析结果进行可视化的工具,它使用wxPython讲Profiler的数据可视化
runsnake mkm_run.prof
效果图:
KCacheGrind & pyprof2calltree
KCacheGrind是Linux中常用的分析数据可视化软件,他默认处理valgrind的输出,但是我们结合pyprof2calltree工具可以把cProfile的输出转换成KCacheGrind支持的格式。
pyprof2calltree -i mkm_run.prof -k # 转换格式并立即运行KCacheGrind
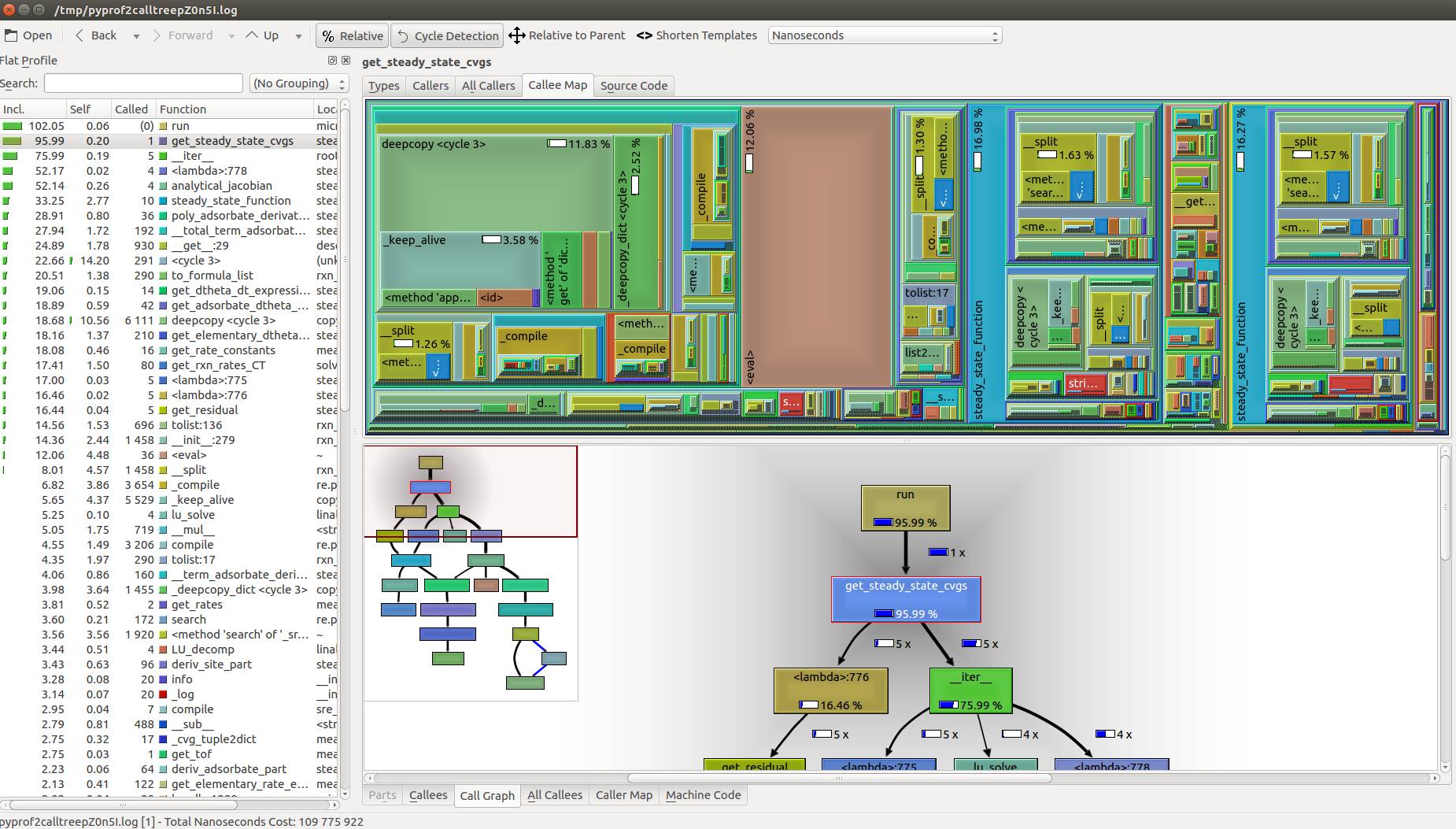
初步优化










