1.文字功底好,逻辑清晰,喜欢独立思考;
2.英语6级及以上的英语水平,科技媒体,科技新闻,芯片设计,计算机科学,人工智能,计算机视觉,语音识别相关专业优先;
3. 学习能力快,态度好。
招募宣言:科学的本质是,问一个不恰当的问题,于是通往了走向恰当答案的路。
简历投递:[email protected]
雷锋网按:本文根据余凯在微软亚洲研究院召开的“让世界充满 AI-人工智能研讨会”上所做的报告《 语音交互-物联网时代的入口》编辑整理而来,在未改变原意的基础上略有删减。

(初敏博士)
以下为初敏博士演讲摘录。
我最好的年龄和时间就是在 MSRA 里度过的。其实在 MSRA 最后两年没有再做语音,因为当时的感觉就是世界发生了天翻地覆的变化,但是跟语音没关系,所以后来就转向做大数据之类的事情。
后来到了阿里也几乎没有做语音,一直到了 2014 年底,阿里才开始要做语音。所以做的时间并不长,但这次有一个大的不一样的感觉:诶,这次好像真的是到风口上了。现在的数据、计算能力跟之前非常不一样,有很多的语音的需要和应用场景。
我今天不会太多地讲技术,会主要讲一些应用场景及在应用中碰到的困难。
为什么语音火起来了:数据驱动和广泛的接口
今天为什么人工智能、深度学习这一块能火起来,主要是因为今天有“数据驱动”:数据和计算能力的增强,使得我们可以在很多方面做得精细。另外就是,入口在变化。今天手机已经几乎能够处理 PC 做的事情,另外家里的汽车、音箱、电视等设备,也成为新的入口。

我们在不同设备之间切换,语音会成为这些设备最好的交互方式,因为它是最方便的、最自然的交互方式。
语音的概念在改变,传统讲语音,指的就是语音合成、语音识别等。如今的语音,一定是一个泛概念,一定包含着后续的自然语言处理。如果一句话被你识别出来做出文字内容,但你理解不了这些文字包含的内容,其实后续很多事情都是做不了的。
语音交互有两个层面可以做,一个是在操作系统底层做,可以跨设备使用;另外就只是一个 API,任何一个 App 都可以调用。
阿里云 ET 在双十一:字幕并不理想
我们阿里这边,最近的展示阿里云 ET,它其实是代表了各种人工智能技术的集合。而人类能与阿里云 ET 真正互动起来,其实是靠语音。
前两天双十一晚会有一个变魔术的节目,其实是非常困难的,因为它是直播。我们做下来最大的体验就是:真的想用,还是很不容易的。
现场一堆问题,我们要对接 10 多个团队,音频信号团队、视频信号团队、导演彩排等,我们到最后一次彩排都是出问题的。
我们当时也打了字幕,我个人认为当天的字幕并不理想,因为日程紧张,主持人语速很快,这就是很大的挑战。

双十一当晚,我们在媒体中心的活动上也打了字幕,这个字幕效果就好很多。我们后来统计这一场的错误率大概 3% 左右,其实就是因为这一场的环境简单。
所以我们到今天也还在思考:这个真的能用了吗?如何把这样一个看似很成熟的技术,能在各种真实的场景中应用起来,这还是一个系统工程的事情。
打字幕这个功能,我们目前真正在用的场景就是法院,快速形成庭审的速记稿。这在浙江的高等法院已经部署了,这个反应是比较好的。以前法官为了要让书记员记下来,他是要控制节奏的,而且书记员在记得过程中也要筛减内容。在庭审的几场演示中,基本都可以做到 95-96% 的准确率,这就很能用了,而且稿子都是法官原汁原味讲出来的。

最大的挑战:端语音信号处理
有了云的平台架构的基础之后,任何一个端接进来,最主要的挑战都是端上语音信号的采集和处理。
我们语音的一个应用就是:个人助理。我们在 YunOS 操作系统上做了个人助理,另外还包括汽车里的。汽车里还是要解决降噪的问题,我们最近做的事情就是,开着车窗、播着音乐,如何在这样的环境下让系统可以唤醒地很好。因为我们测试的汽车上只有一个麦克风,主驾驶和副驾驶上的人说话是不一样的,一个人抬着头和低着头说话是不一样的,所以在接入的时候会有很多很多这样细节的问题。
另外还有应用的直达。以支付宝为例,这个 App 里有很多小的功能,你想找一个事情是很痛苦的。我们做了一个称为“Open Dialogue”的小架构,业务方在这个基础之上自己去开发一些简单的理解。比如用户对着手机说“我要给某某转账多少钱”,那么就会直接加载出这么一个转账的界面。这样用户就不用在各种界面里选,我觉得这将是语音给我们带来的最大价值:在有太多选择的时候,用说话就能触达到我要的那个点。
但要做到这一点,背后的技术就不仅仅是识别,而是你如何快速地接入任何一个场景。因为你换一个 App,你说的话就是不一样的,语义理解上要覆盖的 Domain 是不一样的。这里的挑战就是你要怎样建立一个可扩展的的架构,让任何一个新的业务、新的 Domain 来快速地接入。

我们还有一个尝试领域就是客服。中国目前的客服很多都是打电话,然后按很多数字选项才能接入到你想要的客服选项。这当中其实有很多数据是可以沉淀下来的,沉淀下来之后就可以进行学习。
在客服系统中分为几个部分,一个部分就是语音识别,把语音转为文字,另一个就是问题的分类,分类到两个地方,一个是机器人自助的服务(常规的、简洁的资询类问题),一个是人工服务,来解决更复杂的问题。
阿里集团的客服,基本上走的是这个路子:90% 的客服请求,基本都是机器处理掉的。
这个过程中,电话被文字化,数据会不断地沉淀下来,有很多价值待发掘。一个就是质检客服质量,这其实是一个刚需,还有就是用来发掘用户喜欢什么样的产品。
我们如今很难做到一个通用的模型,来适应不同的场景。数据先验的分布,跟你所定义的场景有关。让一个模型快速适应不同的场景,这是现在最大的挑战。
做好语音的瓶颈: 自然语言理解
不同的应用场景,需要技术手段是不一样的。比如我们最常见的,问个天气、酒店、航班等信息,他是很结构化的 Domain,针对特定的 Domain 做,是很容易的。但用户不会遵循 Domain 说话,他会跳来跳去,那难点就是,上下文当中哪些信息该继承,哪些信息不该继承。
另外,在客服的过程中,如何把用户的几万条语义计算出来,认为它们是相同的,这也是难点。传统是用搜索的方法来做,但搜索只是击中了几个关键词,有时经常会答非所问。
所以我们觉得人机交互往后最大的瓶颈可能就是在这个地方,就是自然语言处理是否能做的更好。
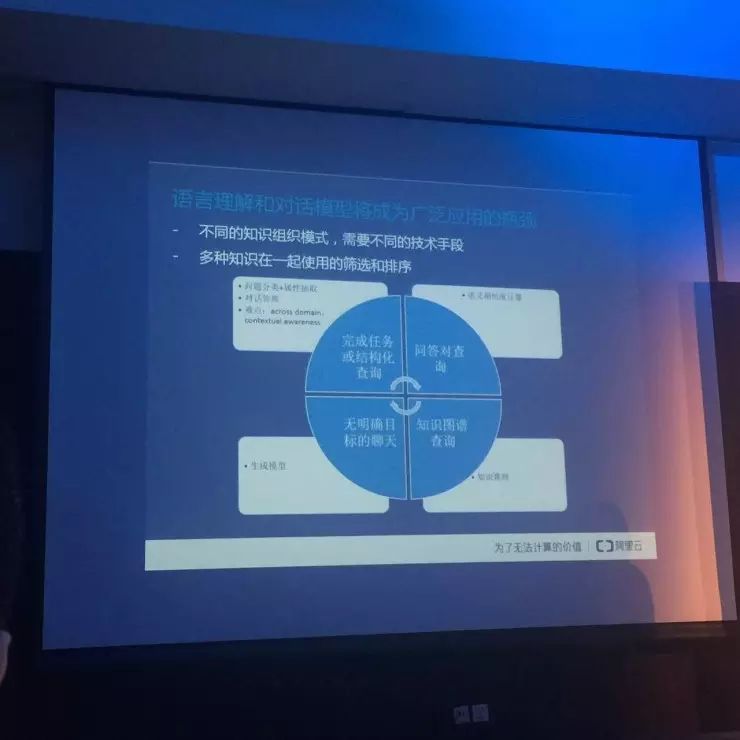
我们今天的团队任务很集中,只做了语言的交互,并没有做数据本身,因为做数据这个工程实在是太大了。所以要把很多的数据服务接进来,但是有时这些数据与语音接入的时候,并不是很友好,这是一个需要改进的地方。所以这一盘,如果要做通的话,是一个非常大的范围,也不是一个两个团队自己能做完的,要靠生态来完成。