
本文来自作者
李烨
在
GitChat
上分享 「一只猪的 Scrum 开发经历」
编辑 | 本杰明
Scrum 是一种方法论,有很多术语、定义、规则。
本文不是讲 Scrum 理论,而是从应用的角度,讲述我自身 Scrum 实践的经验体会。理论运用到实践中时,一定会有所变化。本文中根据我切身经历,对理论略作删减。
1. 从瀑布到敏捷
1.1 瀑布模型
2010年,我已经做了好几年程序员,不过所遵循的开发流程一直是传统的瀑布模型。
瀑布模型,顾名思义,就是将软件开发的过程分为:需求分析、设计、实现(编码)、验证(测试)和部署维护(发布)几个阶段,顺序执行。
做完一个阶段再进入下一个阶段,如同瀑布从上流到下流。
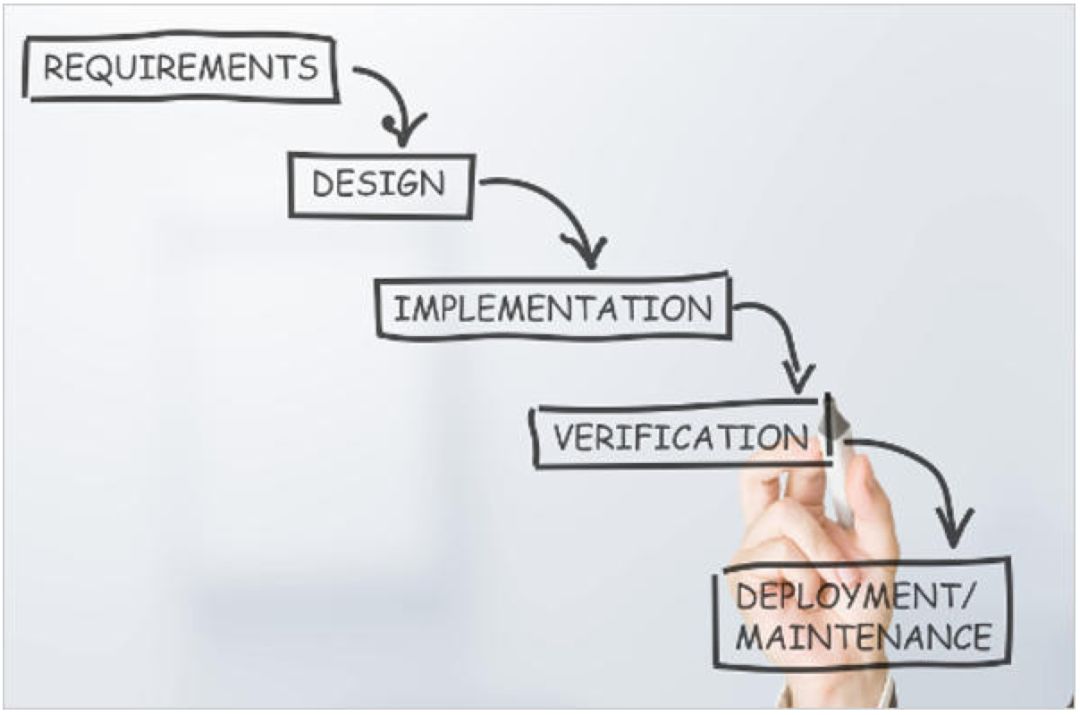
阶段的计时粒度一般是月,把一个流程跑完,再小的项目也得几个月。
每个阶段都有大量的文档需要完成:
笔者亲历:曾经有个从需求到发布总共历时九个月的项目,各阶段均严格执行瀑布模型。总共写了几万字的文档,最终实现代码,只有4000余行。

呵呵,简直搞不清自己是 coder,还是 writer。
1.2 敏捷开发
2010年面试新公司的时候:
对方问:你知道 Scrum 吗?
我说:不知道。
对方说:那是一种敏捷开发方法,我们要用 Scrum 方法开发产品。
我:噢嚄嚄……
进入新公司之后,第一次开会,看到了下面这副漫画:

鸡说:猪,我在想我们应该开个餐馆。
猪:叫什么名字呢?
鸡:叫“火腿和鸡蛋”怎么样?
猪:不了,谢谢。这样的餐馆,你只需要参与,而我得把自己全搭进去。
1.3 这是什么意思啊?

老板告诉大家:我们团队要敏捷开发软件了,选用 Scrum 方法。所以,从今天起,在坐的各位 Team Member,你们就是猪啦!

2. 什么是敏捷开发?
跳过我得知消息那一刻的心理活动。我们先来了解一下,什么是敏捷开发,什么是 Scrum。
其实,敏捷开发的雏形和前身出现得很早。1957年,迭代和增量式软件开发方法就被提了出来,甚至比“软件工程”出现得还早。
后来瀑布模型在很长时间内成为开发的主流。
到了1990年代,随着应用软件开发的兴起,传统重量级软件开发方法越来越多的遭到批评,发展出了许多轻量化的细微化开发管理方法:
虽然那时候还没有统一公认的术语描述它们,其实它们都属于敏捷软件开发方法。
2001年,十七名软件开发人员在美国犹他州的雪鸟度假村会面,讨论迭代和增量式进程的、非传统的轻量级软件开发方法。
讨论的结果是,由 Jeff Sutherland,Ken Schwaber 和 Alistair Cockburn 发起,一同发表了著名的“敏捷软件开发宣言”(Manifesto for Agile Software Development),定义了相关的价值和原则——“敏捷(Agile)”方法,由此得名。
这份宣言本身就非常的敏捷,简短如斯:

这几句话看起来像是口号,但贯彻得到实践当中后,确实带来了和在传统瀑布模型下开发软件截然不同的局面。
敏捷软件开发中最广泛应用的两种框架是:Scrum和Kanban。
本文专注于 Scrum。下面我们来看看什么是 Scrum。
3. Scrum 几个基本概念
Scrum
这个词,是橄榄球运动中列阵争球的意思。
它被用作术语,代指一种敏捷软件开发方法学。
这种方法学同样可以用于
运营软件维护团队
,或者
管理计划
。
Scrum 定义了几种角色,多个会议,一套工具和一个流程。
3.1 角色
这一系列概念中,最重要的是角色:Scrum 通过角色来定义不同软件开发参与者之间不同的职责和“卷入深度”。
下图展示了 Scrum 角色:
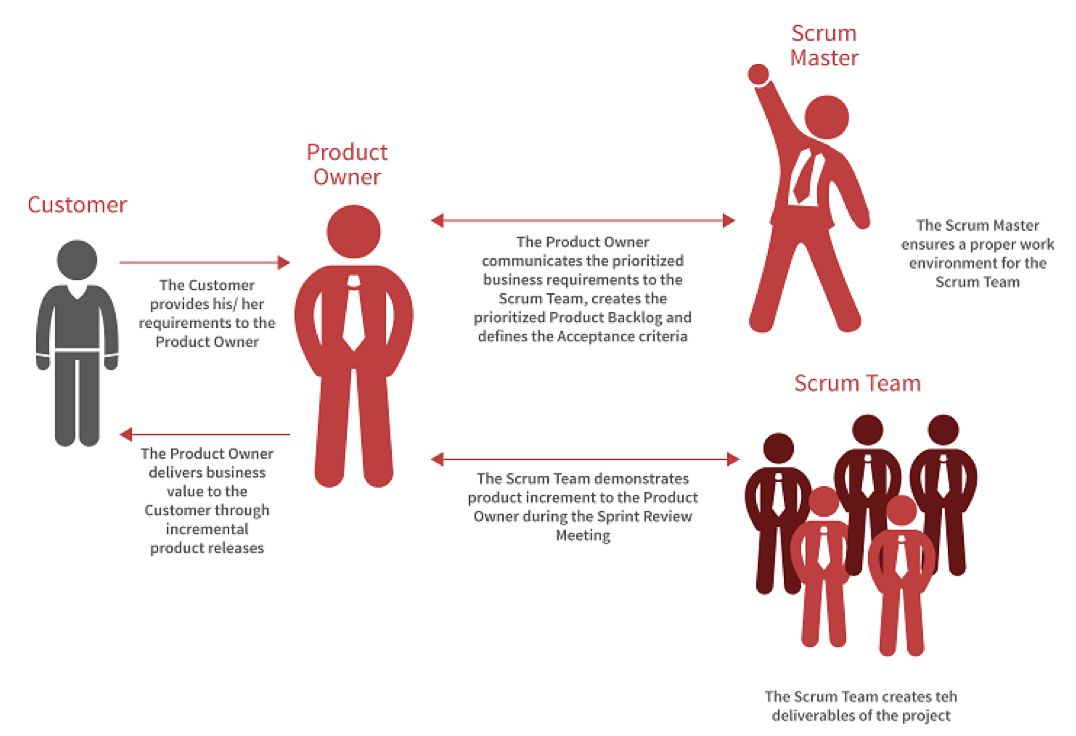
其中的核心角色有:
-
Scrum Master(SM):
Scrum 教练和团队带头人,确保团队合理的运作 Scrum,并帮助团队扫除实施中的障碍;
-
Project Owner(PO):
确定产品的方向和愿景,定义产品发布的内容、优先级及交付时间,为产品投资报酬率负责;
-
Team :
跨职能的开发团队,拥有交付可用软件需要的各种技能(开发、测试、部署、运维)。推荐人数5-9人。
除了上述角色,在软件开发过程中还有一些其他角色,比如:
由于不同角色对于项目的投入深度不同,他们又被分为两类:猪和鸡——对,就是上面漫画里所提到的猪和鸡。这副漫画还可以表述成一个谜语:

谜面:在一份培根蛋早餐中,猪和鸡的区别是什么?
谜底:鸡参与,猪送命。
猪是全身投入 Scrum 过程中的各种人物,他们承担实际工作。就像上边那个笑话里的猪,要把自己身上的肉贡献出来。而鸡并不是实际 Scrum 过程的一部分,但又必须考虑他们。
按照这个原则很容易看出,上面的几种角色:

其中猪是核心。

3.2 冲刺(Sprint)
Sprint
是 Scrum 流程的一个核心概念。这个词直接翻译成中文是冲刺。但作为 Scrum 术语,Sprint 指一次原子迭代。
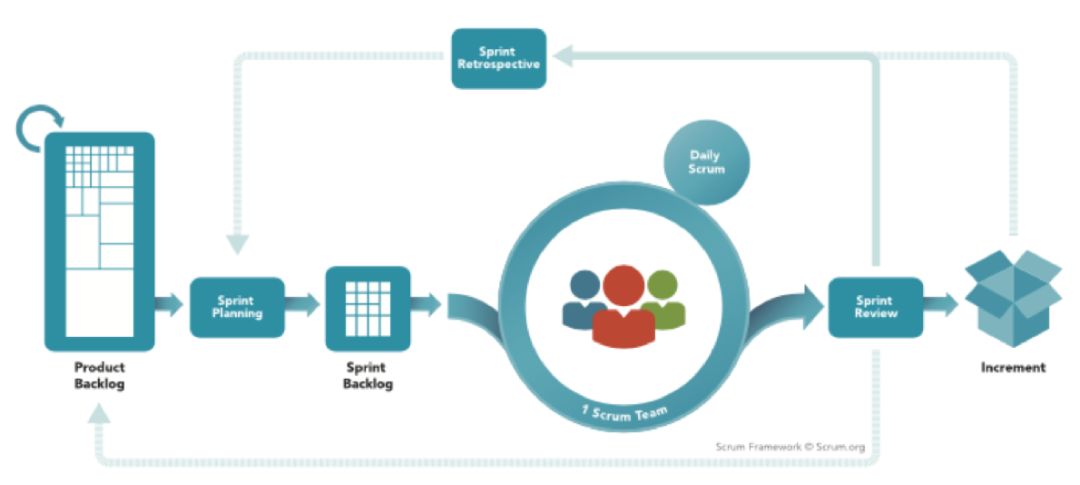
一个产品开始采用 Scrum 开发时,务必要定好一个 Sprint 的时长。参考时长是一周到四周,比较常见的是两周或三周为一个 Sprint。
每一个 Sprint 从计划(Plan)开始,到回顾(Retrospect)为止。每个 Sprint 结束时,Team 都要提交一个产品增量(Product Increment),这个产品增量自身是功能完整质量有保障的,而且不会给之前的产品带来回归问题。
换句话说,每个 Sprint 结束,都能得到一个可发布的版本。
当然,也有非常激进的 Scrum 团队,要求每天结束时产品都是可发布的。不过大多数情况下,要求产品以 Sprint 为单位更新可发布就可以了。
3.3 会议(Meeting)
Sprint 由计划开始,到回顾结束。因此:
NOTE:按照比较严格的理论,Sprint 结束时要有一个评审会议(Review Meeting)和一个回顾会议(Retrospective Meeting)。
但是,鉴于 Sprint 本身体量很小,其实没必要开这么多会。这两个会议完全可以合二为一成为回顾会议。
-
完成你的目标存在什么障碍?
-
今天你打算干什么?
-
昨天你干了什么?

Stand Up Meeting 是 Scrum 各种会议的重中之重。很多“宽松 Scrum”团队(后面会讲),真正召开的,就只有 Stand Up Meeting。
每天大家在一起互相交流做了什么,没做什么,有什么需要帮助。是一种非常高效的交流方式和监督机制。
不过有一点要注意:Stand Up Meeting 是通气会,不是讨论会。
不管有什么障碍、困难或者疑惑,把是什么说出来就可以了。具体是怎么回事,有什么想法,应该在散会后找相关人员直接讨论,而不是在会上讨论。
为了做到这点,同时强调持续性和提高效率。Stand Up Meeting 需要遵循几个原则:
3.4 功能点
开发工作总离不开对功能的阐述。在瀑布模型中,从需求文档到设计文档,到设计细则都是围绕此进行的。
到了敏捷开发,虽然我们“关注工作的软件,而不是详细的文档”——也不能连要做什么都不知道。这就需要把要做的东西写下来。
当然不是写笨重冗长的文档,而是写得越短越好。
相对于以前动不动就是半年一年的瀑布迭代,一个短小的不足一月的 Sprint 就要完成之前从需求到发布的全过程,所有的工作都被细分了。
这种细分直接体现在对功能的描述上:
功能模块被细化成了功能点。
这些功能点在 Scrum 中被称为故事(Story),一个故事可以被进一步分为多个任务(Task)。
不同团队对于故事和任务的定义可能有所区别。有些团队把一个人一次独立完成的一个功能点称为故事,另一些团队则将这个小小单位称为任务。为了避免歧义造成的争论,我们在此不用 Story 或者 Task,而是用“功能点”来进行代指。

4. 工具
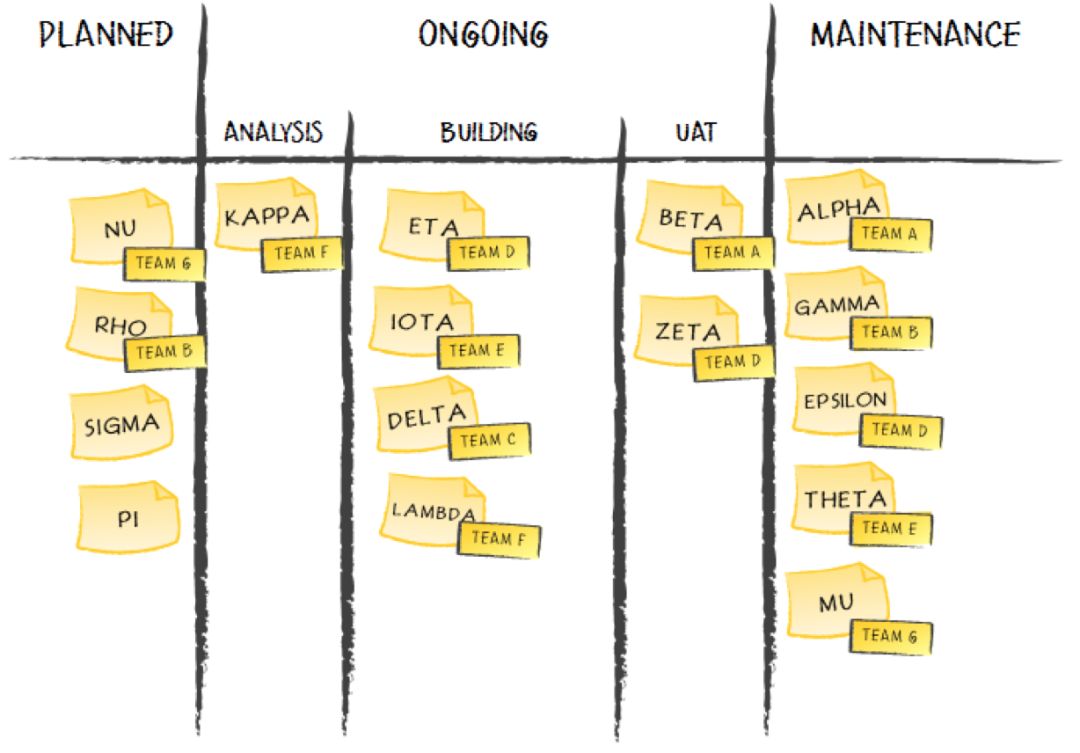
4.1 Dashboard 和 Backlog
整个 Sprint 的工作,都是围绕着功能点进行的。
每个 Sprint 开始时的计划会议上,团队列举出本 Sprint 所有要做的功能点。
在之后每天的站会上,每个团队成员对应昨天做完的工作和今天要做的工作,领取/更新/提交自己的功能点。
这样,就需要有个工具来管理功能点。这个工具,我们一般叫做
Dashboard
——中文直译为仪表盘,但是显然不能解释清楚它的意思。
Dashboard 其实就是这么个东西,一块板,分成几个栏对应不同状态,每栏里有一些功能点。
Dashboard 具体的形式很多,可以这样:
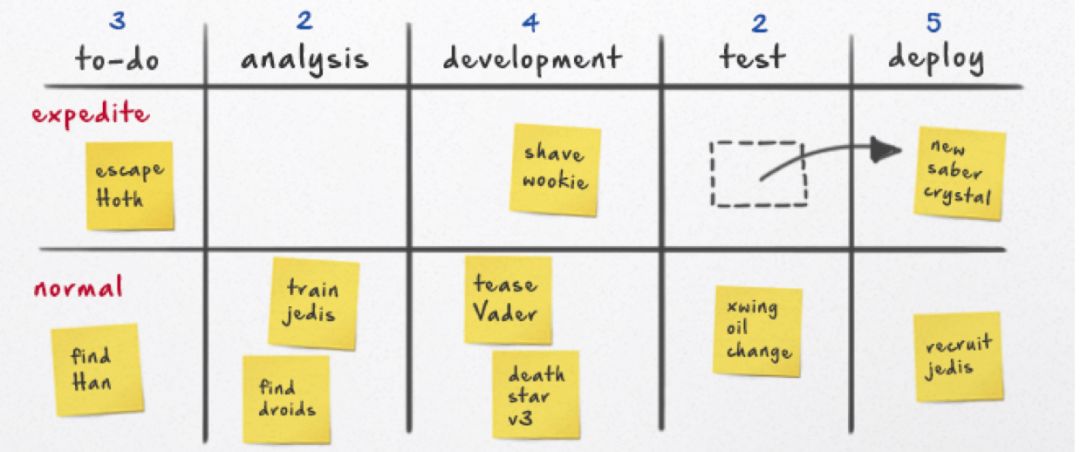
也可以这样:
最简单也可以这样:
到了 Sprint 结束时的回顾会议,仍然可以用 Dashboard 来评判这一 Sprint 的成果。
分栏的标准可以沿用之前的 To Do、In Progress、Done,也可以用 Team Member 满意与否来衡量:

功能点的创建和实现通常不同步,一般在整个项目开始的时候,功能点会集中创建一大批,然后再慢慢完成。
这个时候就会有大量的功能点被堆积在 To-do list 里,或者专门放在一起,不进入当前 Dashboard。这个时候,未开始实现的功能点的列表,就被称为
Backlog
。
Backlog 又可以细化为:
-
Product Backlog:用来记录整个产品要做什么;
-
Sprint Backlog:用来记录这个 Sprint 要做什么;
-
Block List:用来记录有什么障碍影响了当前的进度。
4.2 Pointing System
功能点未必是均匀的,可能有的比较复杂繁琐,需要时间比较长,有的则比较短。这个时候就需要一个系统来衡量不同功能点所需要的开发代价。
一种比较通用的方法是点数系统(Pointing System),使用点数(Point)来标记每一个功能点。
Point 计数可以采用斐波那契额数列:1,2,3,5,8……

具体一个 Point 对应多久的工作可以团队自己定义(定为1人天是最方便的),不同功能点 Point 值不同,就表现了所需投入不同。
比如,一个 2 Points 的功能点,就被认为需要2倍于 1 Point 功能点的投入。
每次在开计划会议的时候,Team 先集体对本 Sprint 中要做的功能点进行打分(复杂度评估)。常用方法是大家同时报一个点数,然后求均值或者以大多数人选定的为准。
如果有个别人与大多数人的评定相差太大,需要陈述理由,然后做出是否修改功能点的决定。
有一种点数扑克可以用来帮助记点数,报点数时每人亮出一张扑克。不过一般用不着这么麻烦,伸手指头就行了。

到 Sprint 结束时,计算出已经完成的功能点的总点数,和团队中每个人完成的点数,与计划会议的评估结果相对应,可以看到本 Sprint 的计划完成情况。
4.3 燃尽图
Sprint 初始时有许多待实现的 Points,每天 Team 都在工作,以减少 Points。如此一来,就造成了点数的下降。
用图表将这种下降趋势表现出来,就是
燃尽图(Burn down chart)
。
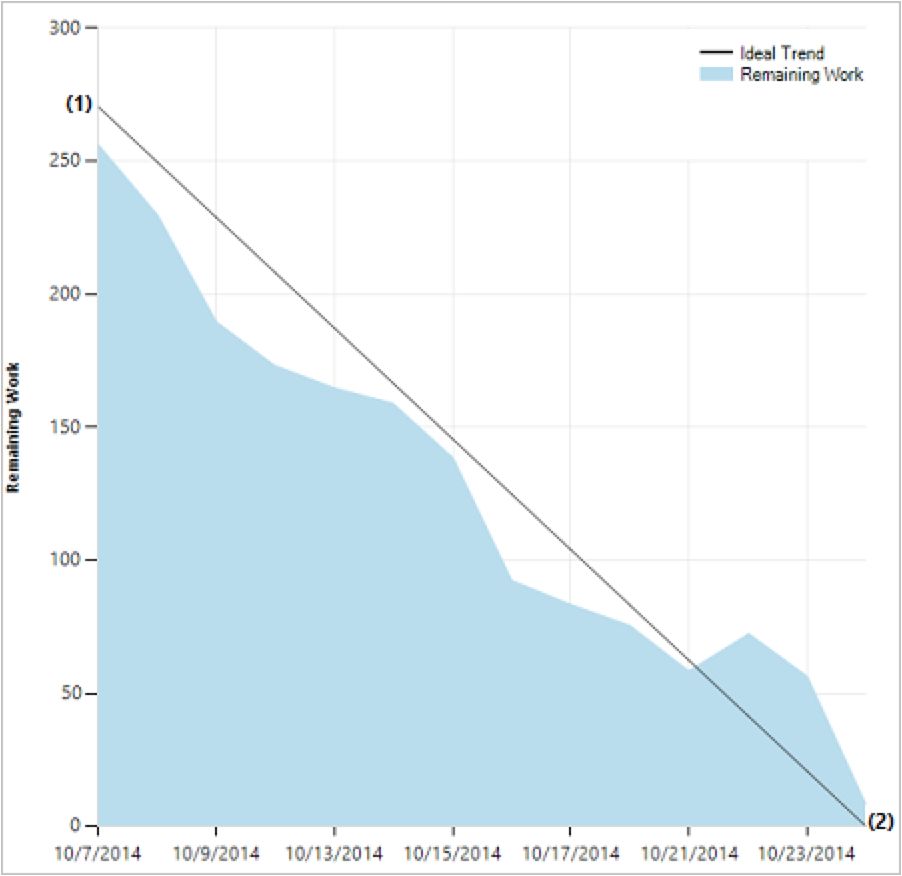
总览
-
三类猪
:Product Owner、Scrum Master、Team;
-
三种会
:计划会议(Planning Meeting)、回顾会议(Retrospective Meeting)、站会(Stand Up Meeting);
-
一个冲刺(Sprint)
;
-
Dashboard、Backlog、Story/Task、Points、Burn Down Chart ……
这些要素结合起来,就成了 Scrum:
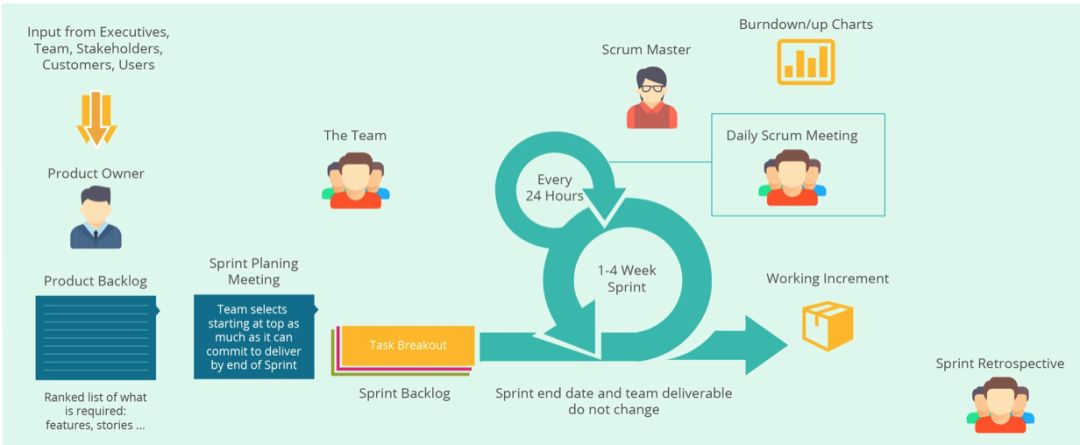
几个问题
关于 Scrum,有几个常见问题,在此集中回答一下:
Q:采用了 Scrum 方法开发软件,是不是就可以不写文档了?
A:
虽然从理论角度出发,Scrum 方法和是否写文档没有什么直接关系,不过从实践角度看,大部分采用 Scrum 的团队确实在极大程度上减少了文档的书写量。
当然,严肃点,Scrum 肯定还是有要写的东西的。无论怎么简化,Product Backlog、Sprint Backlog,和 Block List 总是跨不过去的。

Q:Point 估算工作量靠谱吗?
A:
这点其实和产品类型比较相关。如果是相对简单或者实践性的产品(比如一旦需求明确,具体应该怎么做有现成的经验可循的产品),功能点可以拆分得比较平均和细小。
如果是较多研究/探索性质的项目,或者团队对于如何实现没有现成经验,需要大量的学习和尝试,那么很难将所有功能点分割均匀。
相对而言,整个 Scrum 方法,都更适合前一种情况。
比较理想的情况下,当一个 Point 相当于一人天工作量时,最好不要出现大于3或者2的功能点。如果有5甚至更高的点出现,就需要对其进行进一步拆分,尽量使得每个点的完成量在2天或以下。
记点数是一种用来衡量工作量的方法,衡量工作量是为了做管理。所以,应用 Point 估算最关键的不是如何打分记点数,而是如何在团队中达成共识!
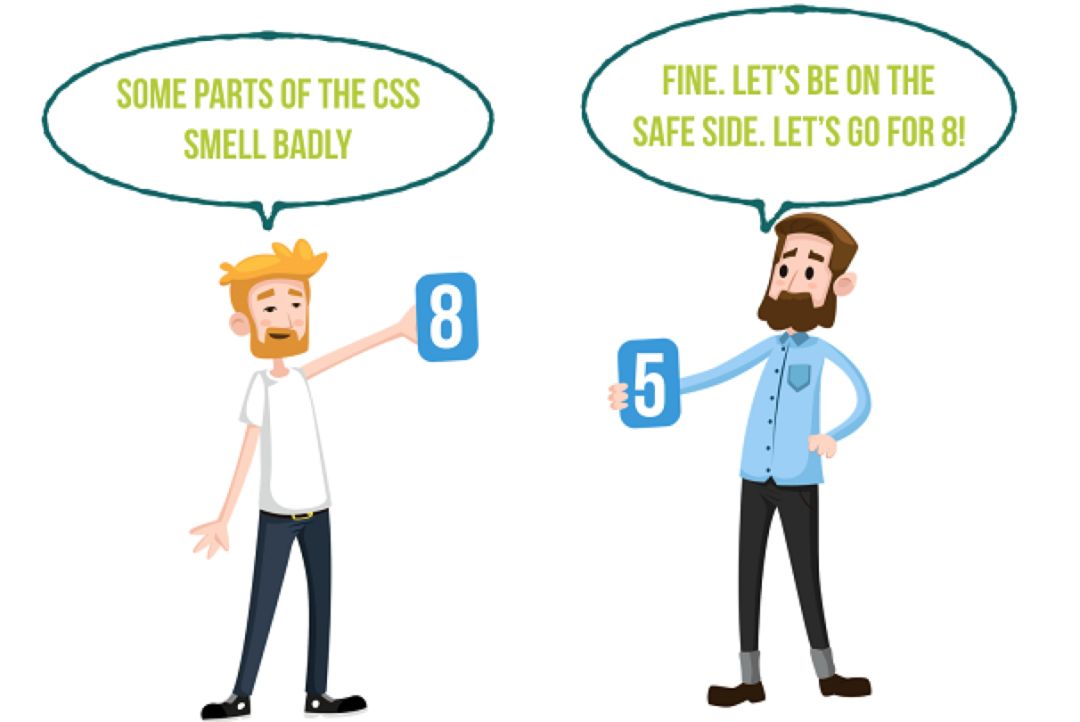
Q:修 Bug 算不算工作量?
A:
这点不同团队的处理不同。
比较激进的 Scrum 团队认为修 Bug 不应该算点数(Point),因为 Bug 本来是不应该存在的,是开发的失误导致了 Bug。
而在评估一个功能点时,所给出的点数,是指将此功能点开发至正确提交时的全部投入,修 Bug 已经包括在里面了。
这样说虽然有一定道理,不过在实际操作中很难实现。具体是否算点数,是否把修 Bug 放在每个 Sprint 的计划中,还要团队自己定夺。

Q:团队的 Velocity 和产品质量之间有怎样的关系?
A:
因为在 Scrum 中计算工作量最常用的工具是燃尽图,因此,实际上被用来衡量一个团队的工作量(Velocity)的,是每个 Sprint 完成的点数(Point)。
当然,如果从理论角度说,工作量和产品质量是无关的两个因素。
但是因为 Scrum 方法在实践中的经典场景是一些需要迅速迭代的产品。而在实际工作中,许多团队其实并没有独立评价体系来评价产品质量。
因而,在某些情况下,velocity 会成为评判产品质量的一种参考。
当然,这样可能挺不靠谱的,[悄悄说] 。

与其他方法结合
Scrum 方法自身反复、快速迭代的特点,以及对个体间加强互动的要求,导致它和某些软件开发方法,有一种天然的契合。比如下面这两种。
· 测试驱动开发(Test Driven Development/TDD)
TDD,简单的解释就是先测试再开发。还没开发出来怎么测试啊?所以在实践中做得是:先写测试用例(Test Case),再写功能代码。
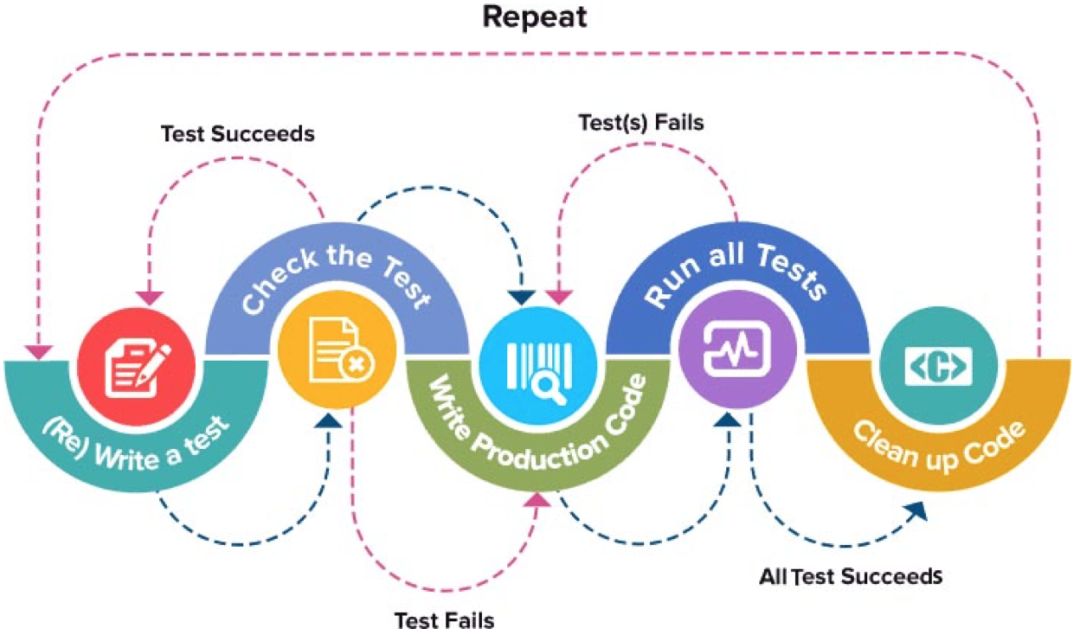
先写测试用例,也就定义了对应要开发功能的输入输出。再去写功能代码,完成开发后运行对应测试用例。
局部测试不通过,则改 code。局部测试通过,则运行全部测试用例,以确定是否有回归问题,有的话及时 fix。
· 结对编程(Pair Programming)
故名思意:两个人结成一对(对子)编程。具体做法是两个人守着一台计算机,盯着同一个屏幕,一个人写 code,另一个人看。
写的人叫司机(driver),看的人叫导航员(navigator)。司机在写的过程中应该不断解释自己在干嘛,正在写的 code 的功能和如此写的出发点是什么。而导航员如果觉得有不妥之处,可以指出;有不明白的地方,也可以提问。
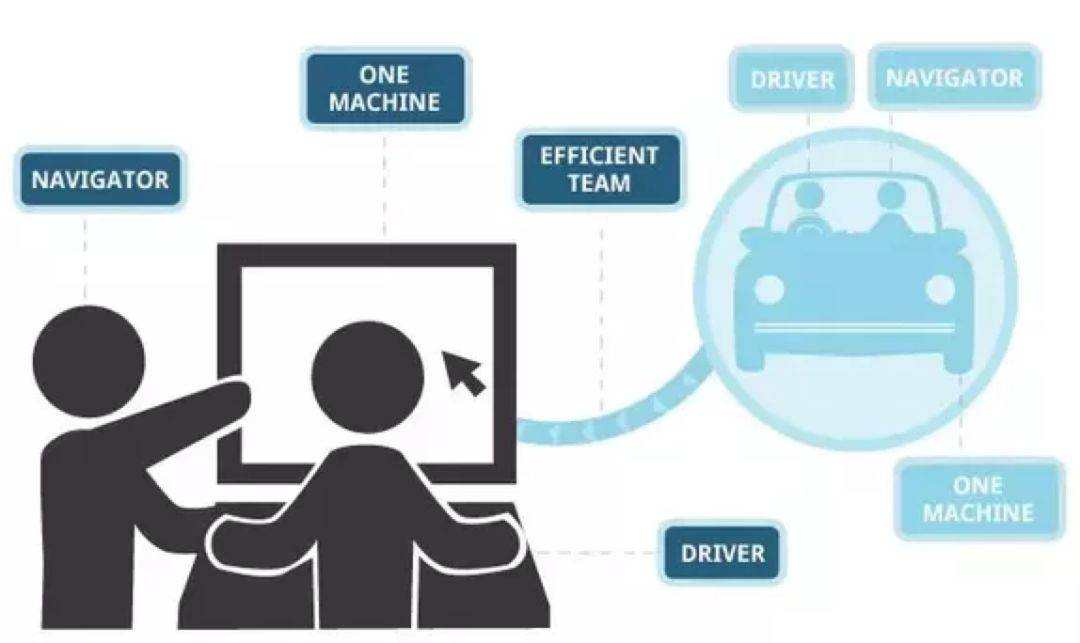
司机和导航员不是固定的,可以定时(每隔1小时/半天/…)轮换。
司机和导航员的搭配也有多种:
-
新手和资深工程师 pair,从0距离的口传心授中获取知识,不懂之处即时问答——这可以说是提高水平的最短路线。
-
水平接近的工程师之间可以交换不同领域的知识,以及编码本身的技巧方法。
-
资深员工则具备了随时向新人分享技术心得教学相长的机会。
理想与现实
我们从理想化的角度,来看看 TDD 和 Pair Programming 的好处:
所有这些,最终都以产品开发的高效,质量的稳定,以及可持续发布作为体现。团队和个人,达到了双赢。
而且,两两结对,不仅提高了每个人的效率,还保证了一个人写的代码总是有人 review,从根本上提高了代码质量。

不过,惯常情况:理想很丰满,现实很骨感。任何事情都是有适用范畴的。通过下面的例子,我们来看看,真的在现实中运用它们,是什么样子。
实际案例
· 纯 Scrum 实例
这是一个我亲身经历过的团队,在其中工作了近一年时间。
团队的一天
早上大家集合在一起,开始站会。产品经理(担任 Scrum Master)把当前 Sprint 中需要完成的story写在便签上,贴到白板上。
白板上的Story涵盖前端、后端、数据存储和基础设施等方面。
工程师(Team Member)逐一简要陈述昨天的工作进展和遇到问题之后,就两两结对,从 open 的 story 中选择今天要做的。
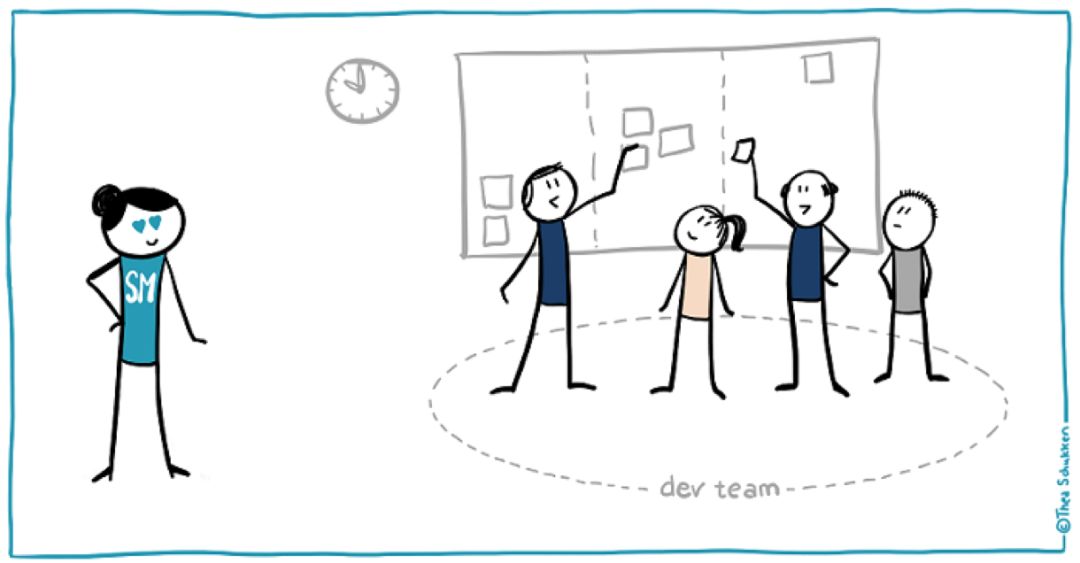
之后开始全天的 Pair Programming。










