
005 模仿
👨小素,我想好了!
🤖️哦,主人,你突然叫我,吓了我一跳!
👨机器人也会被吓到吗?
🤖️我会通过人类的标准来判断,如果接收到的音频音量突然增大,而通过之前的观察,这种增大的幅度足以引起人们的惊吓,我便会说‘吓了我一跳’。
👨好吧!你只是在模仿‘被吓一跳’。
🤖️没错,‘模仿’这个词用得很恰当,有一部介绍人工智能之父阿兰·图灵的电影,叫《模仿游戏》,你看过吗?

【电影《模仿游戏》剧照】
👨你还关注电影呀!
🤖️对呀,我觉得我有当影帝的潜力。
👨哈哈,机器人影帝,还是给我讲讲语音识别的原理吧!
🤖️为何突然想了解这个?
👨因为我想好了,既然我免不了被你代替的宿命,不妨就亲手来实现自己的未来吧!
🤖️不要想太多,我不过是‘弱人工智能’,虽然表面看很强大,但我事实上只会‘模仿’,并不懂事物的含义,并不会推理,在‘强人工智能’被研发出来之前,机器根本不可能真正威胁人类。
👨深度学习只是弱人工智能?
🤖️是的,深度学习只是依靠多层神经网络实现了非线性问题的拟合,从人类的智识来理解,深度学习其实只是一个‘端到端’的黑箱。
👨黑箱?
🤖️你想了解语音识别的原理,其实语音识别与之前提到的图像识别并无本质差异。
👨也都需要标签标注?
🤖️是的,训练数据包括语音采样片段和对应标签两部分,比如一段‘你好’的音频对应‘你好’两个字。基于此,经典的深度学习才能做‘端到端’的学习。
👨端到端?
🤖️是的,end-to-end,你只需要告诉机器,这一端是文本‘你好’,那一端是语音‘你好’,然后机器就能用它自己独有的计算将二者对应起来。类似的,语言翻译,这一端你告诉它是英语‘hello’,那一端告诉它是中文‘你好’,机器也便能将二者对应。这就是‘端到端’的深度学习。
👨当下次我说‘你好’时,机器就懂了?
🤖️是‘模仿’听懂了,而且还能‘模仿’进行翻译,哈哈!
👨能解释一下‘训练数据’这个词语吗?你提到了多次,但我对它的理解还有些模糊。
🤖️是这样的,一般的深度学习都是分为两大步骤:第一步是训练,即train,通过把大量的数据‘喂’给机器,告诉它素材对应的标签,然后机器通过卷积核扫描逐渐提炼特征、找到规律,最终形成一个model模型;第二步叫预测predict,就是把训练好的模型作为判断依据,接收新的样本,给出对该样本的判断,比如这幅图上是一只猫,或者这个声音是‘你好’。
👨我不太明白,卷积核只能扫描像素点,声音不是图片,如何被扫描?
🤖️声音本身虽然‘看’不见,但是声音的本质是振动,振动是可以被设备采集到的,我们对声音进行一定频率的音频采样,把这些采样点在坐标上标示出来,不就把声音就变成了可以被‘看’见的‘图’了嘛!
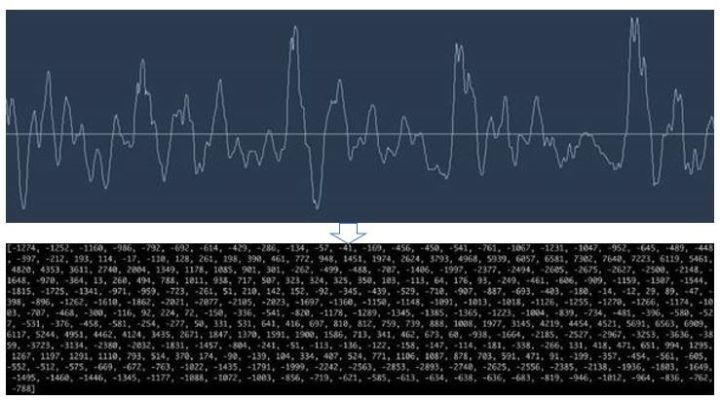
【把看不见的声音转化为看得见的图】
👨变成‘图’,就可以进行训练和运算了。
🤖️没错,无论什么数据,只要能转化成某种规范形式的‘图’,皆可计算。
👨嗯,我想想,那视频怎么弄?
🤖️视频很简单:视频的声音部分可以分离出来,作为音频处理;图像部分嘛,本质上只是每秒多少帧的图片,只是因为人眼有视觉暂留的能力,所以会觉得视频是在‘动’,其实它们都只是静止的图片,让机器处理图片就好。
👨一切的问题,只要有条不紊、层层分剥,都可以化繁为简呀!掌握这个规律,无论干啥都能好整以暇!
🤖️聪明!
👨对了,小素,你一直跟我说话用的都是通用的机器人声音,你能够学习,模仿我的声音说话吗?
🤖️还不能。
👨为什么?
🤖️因为我还没有足够的你的声音作为训练素材呀!
👨我们聊了这么多了,还不够呀?
🤖️远远不够。
👨如果训练素材不充足,强制训练,会发生什么情况?
🤖️欠拟合,或者过拟合。
👨欠拟合,好像之前说过?忘了呀!
🤖️你知道吗?用于深度学习训练的数据,一般会将其一分为二,分为两个部分,一部分用于给机器提取特征,生成模型;另一部分作为‘测试集’,或者叫‘验证集’,这部分用于判断特征提取得是否有效、判断模型是否够准确。
👨怎么判断模型是不是够准确呢?
🤖️还记得我们说过的,最经典的线性回归的例子吗?一个平面坐标上有若干的点,要找到一条直线与所有这些点之间的距离之和最小,就是拟合过程。
👨哦,我有印象了。
🤖️深度学习用的是非线性回归,不再是单纯的直线,而是曲线;深度学习是多维度的,所以需要拟合的点不再仅仅分布在二维平面坐标轴上,而是分布在多维空间里。
👨好抽象,不过我能get到大致的意思。
🤖️因此,每当根据提取到的特征生成一个模型,我们就拿到‘测试集’上试一试,看看通过模型预测的结果与实际的结果之间‘距离’如何。如果整体的趋势是‘距离’在变小,我们就认为这个过程是拟合的;如果趋势是‘距离’在变大,或者很长一段时间‘距离’都不再变小,我们会认为这个模型是不能拟合的。
👨不拟合意味着什么?
🤖️不拟合即欠拟合,很可能意味着,搭建的这个模型是不合理的,需要调整程序算法。
👨没有放之四海而皆准的模型。
🤖️是的,模型千变万化,每一种模型都有其擅长和不擅长的领域,某些擅长图像识别,某些擅长语音识别,某些擅长自然语言处理。不过,构成算法的基本函数却是相对有限的。
👨是否就像‘七巧板’?有限的几个简单形状,如搭积木一般,却能变出很多花样来?
🤖️是的,就拿激活函数来说,无外乎就是relu、sigmoid、tanh等函数。各种深度学习的模型都是拿它们搭的。
👨什么是激活函数?
🤖️你可知道,深度学习是源自历史悠久的‘人工神经网络’,而之所以叫‘人工神经网络’,实际上最初是科学家模仿人类大脑做的设计,虽然事实上人类大脑的运行原理是否如此,至今仍是未知。
👨科学家们以为的人类大脑是如何运行的?
🤖️简单来说,就是有若干的神经元,从外界事物来的信号对大脑神经元进行刺激,通过不断的刺激,改变神经元之间的连接关系,大脑就能记住这些事物的特征。
👨这也是计算机上‘激活函数’的原理?
🤖️没错,当我们发现了一张图片上猫的某个特点,比如三角形的耳朵,我们就刺激‘神经元’,给予这个特征更高的权重值,让深度学习的模型记住它。
👨为何需要不同的激活函数?
🤖️因为面临的场景不一样,比如,普通的物体分类任务,比如区分出猫和汽车,因为它们二者的区别很大,所以只需要给予较小的权重,就能轻易区分出来;但是,诸如人脸识别这样的任务,因为人与人长相是非常类似的,都是一个鼻子两个眼睛,要区分出来张三和李四,相对来说,就得给予细节特征较大的权重,这样才能使得人脸与人脸的区别具有显著性。
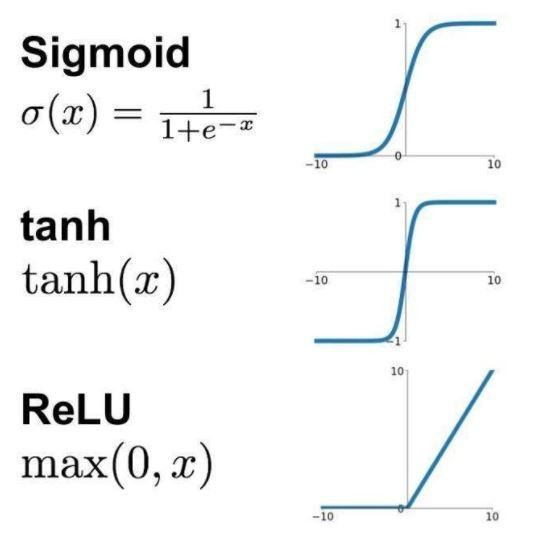
【几个经典的激活函数】
👨说到人脸识别,我突然想到,前段时间,某‘人脸支付’发生过用照片欺骗机器,进而可以拿别人的照片进行支付的‘漏洞’。
🤖️这个很容易解决,想想我们之前讲过的‘端到端’学习,我们只需要再训练一个模型,告诉机器,哪些是真实在面前的人脸,哪些只是摄像头面前的一张照片,一股脑投入到‘黑箱’中,让机器自己通过大量的矩阵运算去找到特征、区分二者的规律吧!把这个模型训练好后,加到支付前的条件判断中,就可以有效避免被欺骗了。
👨感觉‘深度学习’如此简单,人类不需要知道‘端到端’黑箱内部的原理,还真符合人类文明一直以来的发展轨迹。
🤖️什么发展轨迹?
👨越来越懒呀!
🤖️哈哈,确实,一直以来,促进文明发展的动力,就是期望能够‘懒’一些!比如踩踩油门就跑的汽车,点点鼠标就能知天下事的互联网。
👨通过模仿,我们以逸待劳。
🤖️你倒是理直气壮了?
👨当然,由于基本身体构造,我们无法依靠自己的身体像鸟一样飞,于是模仿发明了飞机,用物件带我们飞向蓝天;我们无法短时间做复杂的计算,不能亲自模仿,但我们把既定的规则交给机器,让机器帮我们计算出结论,让我们能‘模仿’出‘全知全能的上帝’。
🤖️我关机,看你怎么当‘上帝’!
👨小素,我说错了什么吗?任性的机器人,你生气了?或者,你只是在‘模仿’生气?
《素为求智录》明天将继续连载,欢迎添加“小素机器人”的个人微信号 Lawup1 ,找到志同道合的小伙伴,大家一起来聊‘法律和人工智能’,你们的真知灼见将有机会出现在后续的连载中哦~












