围棋、视频游戏、迷宫……DeepMind 的人工智能在玩游戏方面可谓是得心应手。DeepMind 又发布了一篇论文介绍了他们在这方面的另一项新研究:循环环境模拟器(recurrent environment simulator)。据介绍,该方法可以被用来改进探索(exploration)过程,还能适应多种不同的环境(包括 Atari 游戏、3D 赛车和迷宫)。本论文已经被 ICLR 2017 接收。机器之心对本论文进行了简单编译介绍,更多详情请点击文末「阅读原文」查阅原论文。

可以模拟环境(environment)响应动作(action)的方式的模型可以被代理用来进行有效的规划和行动。我们通过引入能够做出未来数百个时间步骤的时间和空间连贯预测(coherent prediction)的循环神经网络(recurrent neural network)而改进了之前的来自高维像素观察的环境模拟器。我们对性能影响因素进行了深度的分析,为推动对这些模型的性质的理解提供了最广泛的尝试。我们使用一种模型解决了计算效率低下的问题——该模型不需要在每一个时间步骤都生成一个高维图像。我们表明我们的方法可以被用来改进探索(exploration),并且可以适应多种不同的环境,即 10 种 Atari 游戏、一个 3D 赛车环境和复杂的 3D 迷宫。
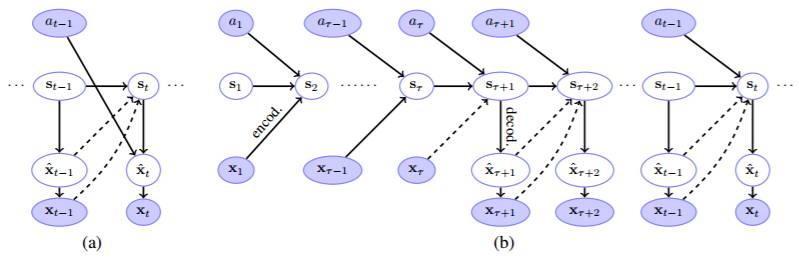
图 1:(a) 在 Oh et al. (2015) 中使用的循环结构的图模型,(b) 我们的循环结构的图模型。填充节点和空节点分别代表被观察的和隐藏的变量
2 循环环境模拟器
环境模拟器是一种模型;给定一个动作序列 a1, . . . , aτ−1 ≡ a1:τ−1 及其对应的环境观察 x1:τ,该模型可以预测后续动作的影响
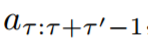 ,比如,构建对环境的预测
,比如,构建对环境的预测
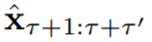 或状态表征
或状态表征
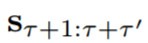 。
。
我们的起点是 Oh et al. (2015) 中的循环模拟器(recurrent simulator),其在模拟带有视觉观察(帧)和离散动作的确定性环境上的表现是当前最佳的。该模拟器是一个带有以下主干结构的循环神经网络:
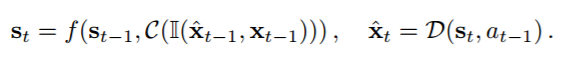
在这个等式中,st 是环境的隐藏状态表征,f 是一个非线性的确定状态转移函数。I 符号表示预测的帧
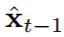 和真实的帧 xt−1 的选择,其会产生两种类型的状态转换,分别称为依赖于预测的转换(prediction-dependent transition)和依赖于观察的转换(observation-dependent transition)。C 是一个由一系列卷积构成的编码函数,D 是一个将状态 st 和动作 at-1 通过一个乘法交互组合起来的解码函数,它然后使用一系列全卷积来将其构建出预测的帧
和真实的帧 xt−1 的选择,其会产生两种类型的状态转换,分别称为依赖于预测的转换(prediction-dependent transition)和依赖于观察的转换(observation-dependent transition)。C 是一个由一系列卷积构成的编码函数,D 是一个将状态 st 和动作 at-1 通过一个乘法交互组合起来的解码函数,它然后使用一系列全卷积来将其构建出预测的帧
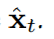
该模型被训练用来最小化被观察的时间序列及其预测
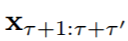 之间的均方误差,其对应于其环境的演化。在一个概率框架中,这相当于如图 1(a) 所示的图模型的对数似然的最大化。在这个图 中,xˆt 到 xt 的链接表示随机依赖,因为 xt 是通过向 x^t 添加一个 0 均值和单位方差的高斯噪声项而构成的,而其它剩下的链接都表示确定依赖。虚线表示这两个链接中仅有一个是活动的,这要看其状态转换是依赖于预测还是依赖于观察。
之间的均方误差,其对应于其环境的演化。在一个概率框架中,这相当于如图 1(a) 所示的图模型的对数似然的最大化。在这个图 中,xˆt 到 xt 的链接表示随机依赖,因为 xt 是通过向 x^t 添加一个 0 均值和单位方差的高斯噪声项而构成的,而其它剩下的链接都表示确定依赖。虚线表示这两个链接中仅有一个是活动的,这要看其状态转换是依赖于预测还是依赖于观察。
该模型使用随机梯度下降训练,其中每个 mini-batch 由一个随机从 x1:τ+τ 0 子采样的长度 τ + T 的片段集组成。对于 mini-batch 中的每个片段,模型使用最初的 τ 观察来进化状态,并仅形成最新的 T 观察的预测。训练包括使用预测依赖转换或观察依赖转换(第一个 τ 转换之后)和预测长度 T 的值三个阶段。在第一个阶段,模型使用观察依赖转换并预测 T = 10 个时间步。在第二和第三个阶段,模型使用预测依赖转换并分别预测 T = 3 和 T = 5 个时间步。在评估或使用期间,模型只能使用预测依赖转换。
动作依赖状态转换
上述 Oh et al. (2015) 的模型的一个鲜明特征是动作仅通过预测或者观测间接地影响状态转换。允许动作直接地调节状态转换可潜在地使模型与动作信息更有效地合作。因此我们提出了如下这一核心结构:
在图像模型表征上,这与图 1(b) 中使用从 at−1 到 st 的连接替代从 at−1 到 xˆt 的连接相符合。
短期 vs 长期准确度
上述 Oh et al. (2015) 训练计划的最后两个阶段被用于解决低精确度问题,低精确度由循环神经网络在被要求提前预测几个时间步时仅通过使用观测依赖转换显示而获得。然而,论文并没有分析或讨论替代性训练计划。
原则上讲,最高精确度应该通过如下方式获得:最大可能地接近模型被使用的方式训练模型,进而通过使用尽可能接近模型被要求预测的时间步数量的大量的预测依赖转换。然而,预测依赖转换增加了目标函数的复杂度以至于替代性计划常被使用(Talvitie, 2014; Bengio et al., 2015; Oh et al., 2015)。目前训练方法的指导理念是使用 xt−1 观察而不是 xˆt−1 预测来形成状态 st 将对减少预测造成的错误的传播产生影响,其在更早的训练阶段更高,使得模型可以从时间步 t−1 所构成的错误中纠正自己。例如,根据验证选择的一个日程表,Bengio et al. (2015) 引入了一种预定采样方法,其中在每个时间步中,从伯努利分布(Bernoulli distribution)采样的状态转换类型带有从对应于仅使用观察依赖转换的初始值退火到对应于仅使用预测依赖转换的最终值的参数。
我们对 Atari 不同训练计划的分析考虑了预热长度 τ 、预测长度 T 和预测依赖转换之间的相互作用,分析表明,观察依赖转换不但没有校正效应,而且还会限制模型考虑其预测能力的时间间隔,并因此集中资源。事实上我们发现,连续预测依赖转换的数量越多,对模型聚焦于学习环境的整体动态的鼓励就越多,这带来了更高的长期精确性。最高的长期精确性常常通过一个甚至是在训练早期阶段仅使用预测依赖转换的训练计划获得。聚焦于学习整体动态以从学习帧的精确细节转移模型资源为代价来降低短期精确性。因此,对于不能获得合理的长期精确性的复杂游戏,优选混合预测依赖和观察依赖转换的训练计划。从这一分析得出,当制定训练计划时,应该考虑连续预测依赖转换的比例,而不仅仅是这种转换的比例。
根据这一观点,通过被考虑任务类型的区别可以解释 Bengio et al. (2015) 仅使用预测依赖转换获得的差强人意的结果。确实,在我们的情况中,模型可以在某种程度上容忍诸如早期预测的模糊等错误;Bengio et al. (2015) 考虑的离散问题与我们的情况不同,早期时间步的预测错误可以严重影响后期时间步的预测,因此模型需要很高的短期精确性以获得合理的长期精确性。另外,Bengio et al. (2015) 把形成 st 的预测作为一个定量而不是作为 st−1 的一个函数来对待,因此并不执行精确的最大似然法。
独立于预测的状态转换
除了潜在地令模型更高效地包含动作信息外,允许动作直接影响动态状态的另一个关键优点:它允许考虑不依赖于框架的状态转换情况,即 st = f(st−1, at−1) 形式,其对应于移除从 xˆt−1 和 xt−1 到 st(图 1b)。我们称这种模型为独立预测模拟器(prediction-independent simulator),其代表着不使用预测的情况下演变状态的能力。Srivastava et al. (2015) 也考虑了独立于预测的状态转换在高维的观察值问题。
独立预测模拟器能显著提高计算效率,尤其是在智能体对一系列动作而不是单个动作的影响感兴趣的情况下。实际上,这样的模型并不需要通过一系列卷积从低维状态空间映射到高维观察空间,在每一时间步反之亦然。
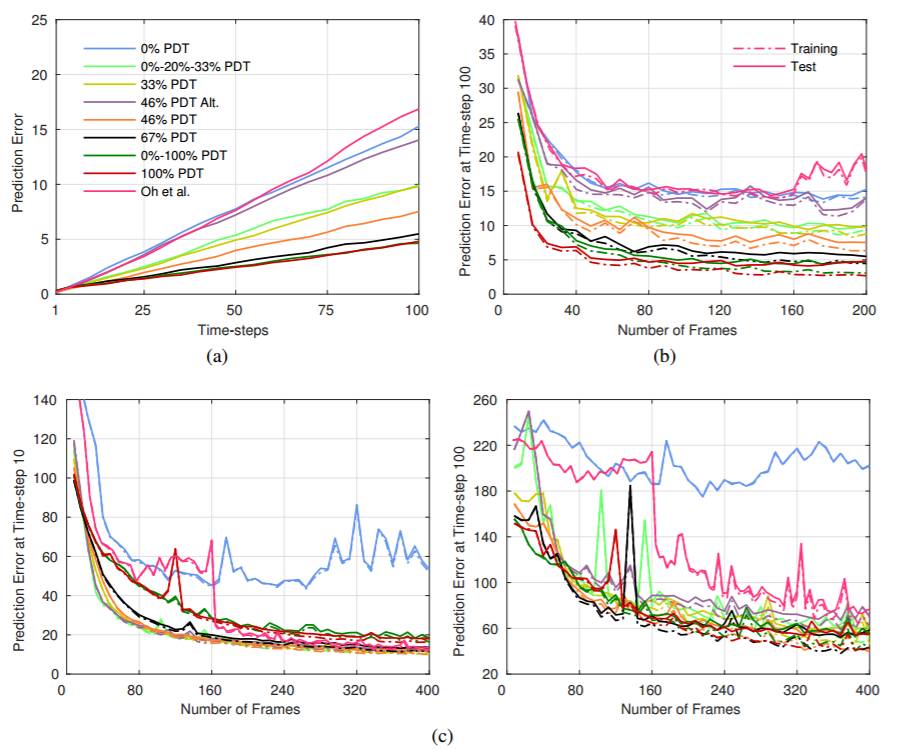
图 2: 在 (a)-(b) Bowling 和 (c) Fishing Derby 上对于不同的训练方案的 10,000 个序列预测误差平均值。在所有图表中使用相同的颜色和线代码。(a)模型看过 2 亿帧之后的预测误差和时间步。(b)-(c):模型在时间步 10 和 100 时预测误差和看过的帧数。
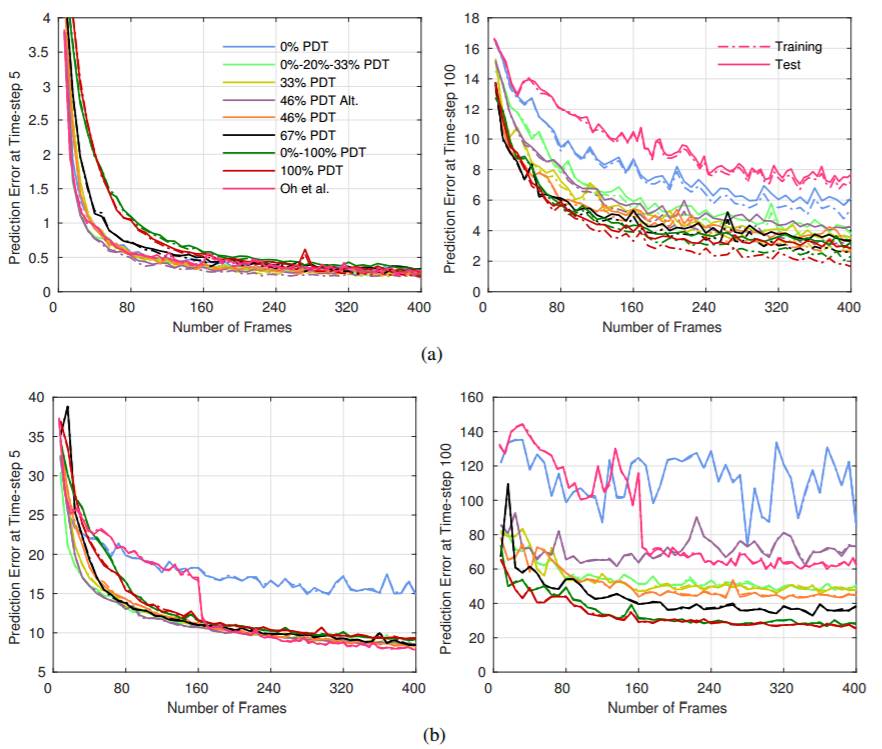
图 3:(a) Pong 和 (b) Seaquest 在不同训练方案的预测误差。

图 7:从使用我们的模拟器和人类玩家采取的动作所生成的(a)500 帧 Pong 和(b)350 帧 Breakout 中提取的关键帧。









