众所周知,图像就是像素值的集合,而这个观点可以帮助计算机科学家和研究者们构建一个和人类大脑相似并能实现特殊功能的神经网络。有时候,这种神经网络甚至能超过人类的准准度。
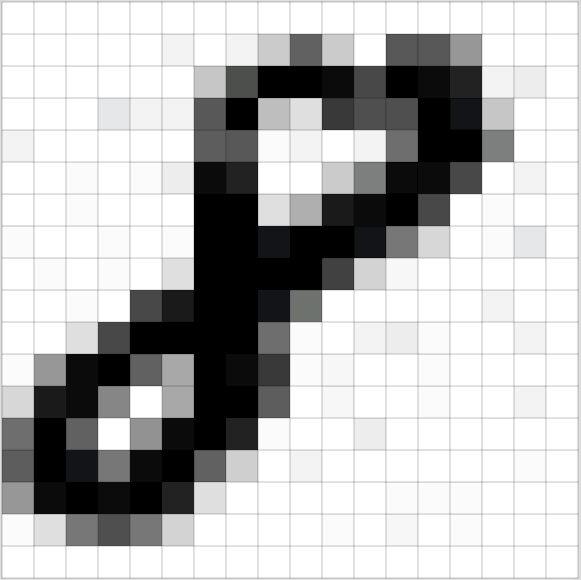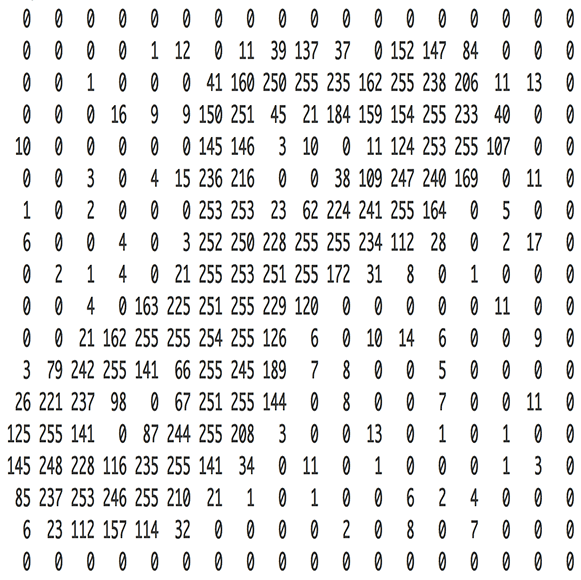
上图是一个非常好的案例,其说明了图像是由像素值表征的这一特征。这些小的像素块形成了最基本的卷积神经网络。
卷积神经网络与一般的神经网络有非常高的相似性,它们都是由可学习的权重和偏置项还有神经元组成。每个神经元接受一些输入,然后执行点积(标量),随后可选择性地执行非线性分类。整个网络仍然表示单可微分(single differentiable)的评估函数(score function),整个网络从一端输入原始图像像素,另一端输出类别的概率。该网络仍然具有损失函数,因为损失函数可以在最后(全连接)层计算相对概率(如支持向量机/Softmax),并且学习常规神经网络的各种开发技巧都能应用到损失函数上。

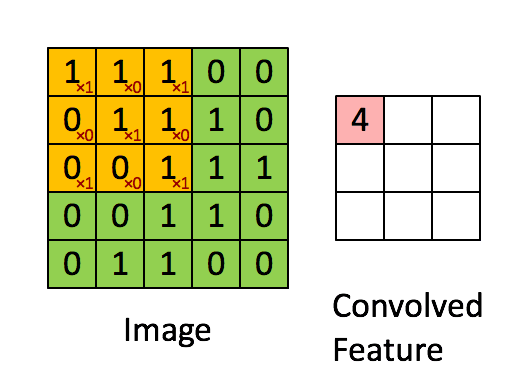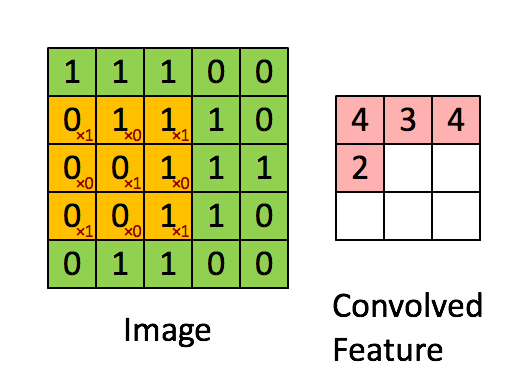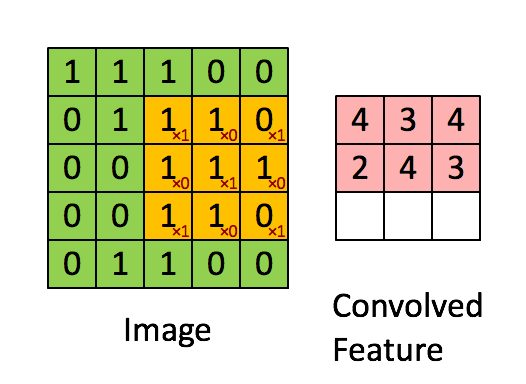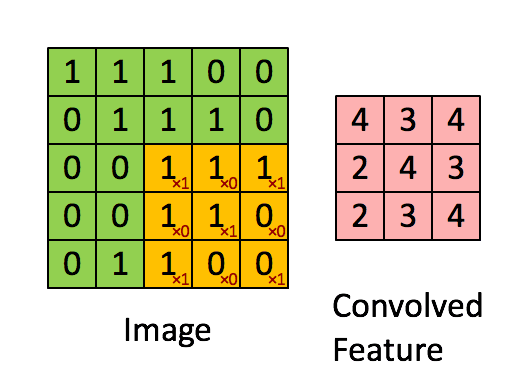
卷积是如何进行的。每一个像素由周围像素的加权和所替代,神经网络会学习这些权重。
最近,随着数据量和计算力的大大提升,ConvNets 在人脸识别、物体识别、交通标志、机器人和自动驾驶等方向表现得十分出色。
下图显展示了在 ConvNet 中四种主要的操作:
1. 卷积(Convolution)
2. 非线性(如 ReLU)
3. 池化或子采样(Pooling or Sub Sampling)
4. 分类(Classification)
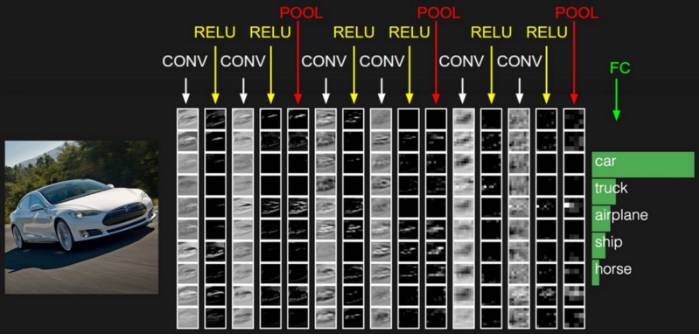
一张汽车的图片经过 ConNet,并在全连接层输出类别为汽车
全卷积网络(All Convolution Network)
大多数用于目标识别的现代卷积神经网络(CNN)都是运用同一原理构建:交替卷积和最大池化层,并伴随着少量全连接层。以前就有一篇论文提出,最大池化(max-pooling)可被一个带有增加步长的卷积层轻易替换,而没有在图像识别基准上出现精确度的损失。论文中提到的另一个趣事也是用一个全局平均池化(Global Average pooling)替换全连接层。
如需详细了解全卷积网络,可查阅论文:https://arxiv.org/abs/1412.6806#
去掉全连接层也许不是一件让人很惊讶的事,因为长久以来人们本来就不怎么使用它。不久前 Yann LeCun 甚至在 Facebook 上说,我从一开始就没用过全连接层。
这不无道理,全连接层与卷积层的唯一区别就是后者的神经元只与输入中的局部域相连,并且卷积空间之中的很多神经元共享参数。然而,全连接层和卷积层中的神经元依然计算点积,它们的函数形式是相同的。因此,结果证明全连接层和卷积层之间的转换是可能的,有时甚至可用卷积层替换全连接层。
正如上文提到的,下一步是从网络中去除空间池化运算。现在这也许会引起一些疑惑。让我们详细看一下这个概念。
空间池化(spatial Pooling),也称为子采样(subsampling)或下采样(downsampling),其减少了每一个特征映射的维度,但是保留了最重要的信息。

让我们以最大池化为例。在这种情况下,我们定义了一个空间窗口(spatial window),并从其中的特征映射获取最大元素,现在记住图 2(卷积是如何工作的)。直观来讲带有更大步长的卷积层可作为子采样和下采样层,从而使输入表征更小更可控。同样它也可减少网络中的参数数量和计算,进而控制过拟合的发生。
为了减少表征尺寸,在卷积层中使用更大步长有时成了很多案例中的最佳选择。在训练好的生成模型,如变分自动编码器(VAE)或生成对抗网络(GAN)中,放弃池化层也是十分重要的。此外,未来的神经网络架构可能会具有非常少的或根本没有池化层。
鉴于所有以上提到的小技巧或微调比较重要,我们在 Github 上发布了使用 Keras 模型实现全卷积神经网络:https://github.com/MateLabs/All-Conv-Keras
导入库(library)和依赖项(dependency)
from __future__ import print_function
import tensorflow as tf
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dropout, Activation, Convolution2D, GlobalAveragePooling2D
from keras.utils import np_utils
from keras.optimizers import SGD
from keras import backend as K
from keras.models import Model
from keras.layers.core import Lambda
from keras.callbacks import ModelCheckpoint
import pandas
在多 GPU 上训练
对于模型的多 GPU 实现,我们有一个可将训练数据分配给可用 GPU 的自定义函数。
计算在 GPU 上完成,输出数据传给 CPU 以完成模型。
def make_parallel(model, gpu_count):
def get_slice(data, idx, parts):
shape = tf.shape(data)
size = tf.concat(0, [ shape[:1] // parts, shape[1:] ])
stride = tf.concat(0, [ shape[:1] // parts, shape[1:]*0 ])
start = stride * idx
return tf.slice(data, start, size)
outputs_all = []
for i in range(len(model.outputs)):
outputs_all.append([])
#Place a copy of the model on each GPU, each getting a slice of the batch
for i in range(gpu_count):
with tf.device('/gpu:%d' % i):
with tf.name_scope('tower_%d' % i) as scope:
inputs = []
#Slice each input into a piece for processing on this GPU
for x in model.inputs:
input_shape = tuple(x.get_shape().as_list())[1:]
slice_n = Lambda(get_slice, output_shape=input_shape, arguments={'idx':i,'parts':gpu_count})(x)
inputs.append(slice_n)
outputs = model(inputs)
if not isinstance(outputs, list):
outputs = [outputs]
#Save all the outputs for merging back together later
for l in range(len(outputs)):
outputs_all[l].append(outputs[l])
# merge outputs on CPU
with tf.device('/cpu:0'):
merged = []
for outputs in outputs_all:
merged.append(merge(outputs, mode='concat', concat_axis=0))
return Model(input=model.inputs, output=merged)
配置批量大小(batch size)、类(class)数量以及迭代次数
由于我们用的是拥有 10 个类(不同对象的种类)的 CIFAR 10 数据集,所以类的数量是 10,批量大小(batch size)等于 32。迭代次数由你自己的可用时间和设备计算能力决定。在这个例子中我们迭代 1000 次。
图像尺寸是 32*32,颜色通道 channels=3(rgb)
batch_size = 32
nb_classes = 10
nb_epoch = 1000
rows, cols = 32, 32
channels = 3
把数据集切分成「训练集」、「测试集」和「验证集」三部分
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
print('X_train shape:', X_train.shape)
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
print (X_train.shape[1:])
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
构建模型
model = Sequential()
model.add(Convolution2D(96, 3, 3, border_mode = 'same', input_shape=(3, 32, 32)))
model.add(Activation('relu'))
model.add(Convolution2D(96, 3, 3,border_mode='same'))
model.add(Activation('relu'))
#The next layer is the substitute of max pooling, we are taking a strided convolution layer to reduce the dimensionality of the image.
model.add(Convolution2D(96, 3, 3, border_mode='same', subsample = (2,2)))
model.add(Dropout(0.5))
model.add(Convolution2D(192, 3, 3, border_mode = 'same'))
model.add(Activation('relu'))
model.add(Convolution2D(192, 3, 3,border_mode='same'))
model.add(Activation('relu'))
# The next layer is the substitute of max pooling, we are taking a strided convolution layer to reduce the dimensionality of the image.
model.add(Convolution2D(192, 3, 3,border_mode='same', subsample = (2,2)))
model.add(Dropout(0.5))
model.add(Convolution2D(192, 3, 3, border_mode = 'same'))
model.add(Activation('relu'))
model.add(Convolution2D(192, 1, 1,border_mode='valid'))
model.add(Activation('relu'))
model.add(Convolution2D(10, 1, 1, border_mode='valid'))
model.add(GlobalAveragePooling2D())
model.add(Activation('softmax'))
model = make_parallel(model, 4)
sgd = SGD(lr=0.1, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
打印模型。这会给你一个模型的一览,它非常有助于视觉化模型的维度和参数数量
print (model.summary())
数据扩充
datagen = ImageDataGenerator(
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=0, # randomly rotate images in the range (degrees, 0 to 180)
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=False, # randomly flip images
vertical_flip=False) # randomly flip images
datagen.fit(X_train)
在你的模型中保存最佳权重并添加检查点
filepath="weights.{epoch:02d}-{val_loss:.2f}.hdf5"checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1, save_best_only=True, save_weights_only=False, mode='max')
callbacks_list = [checkpoint]
# Fit the model on the batches generated by datagen.flow().
history_callback = model.fit_generator(datagen.flow(X_train, Y_train, batch_size=batch_size), samples_per_epoch=X_train.shape[0], nb_epoch=nb_epoch, validation_data=(X_test, Y_test), callbacks=callbacks_list, verbose=0)
最后,拿到训练过程的日志并保存你的模型
pandas.DataFrame(history_callback.history).to_csv("history.csv")
model.save('keras_allconv.h5')
以上的模型在前 350 次迭代后很容易就实现超过 90% 的精确度。如果你想要增加精确度,那你可以用计算时间为代价,并尝试扩充更大的数据。
原文地址:https://medium.com/@matelabs_ai/how-these-researchers-tried-something-unconventional-to-came-out-with-a-smaller-yet-better-image-544327f30e72#.1a1ve638e
©本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]










