正文
AI科技评论按:9 月 26 日,机器人领域的顶级学术会议 IROS 2017 进入第二日。上午,著名华人计算机视觉专家、斯坦福副教授李飞飞,在温哥华会议中心面向全体与会专家学者作了长达一小时的专题报告。
在昨天发布的上篇 李飞飞:为什么计算机视觉对机器人如此重要? | IROS 2017中,李飞飞介绍了视觉对生物的重要性,以及计算机视觉在物体识别任务中的飞速发展。在下篇中,李飞飞继续与大家讨论了计算机视觉的下一步目标:丰富场景理解,以及计算机视觉与语言结合和任务驱动的计算机视觉的进展和前景。场景理解和与语言结合的计算机视觉进一步搭起了人类和计算机之间沟通的桥梁,任务驱动的计算机视觉也会在机器人领域大放异彩。李飞飞介绍的自己团队的工作也丰富多样、令人振奋。

(2015年,李飞飞也在同一个会场面向着大海和听众进行过一次 TED 演讲)
物体识别之后:丰富场景识别
(续上篇)在物体识别问题已经很大程度上解决以后,我们的下一个目标是走出物体本身,关注更为广泛的对象之间的关系、语言等等。

在Visual Genome数据集之后,我们做的另一项研究是重新认识场景识别。
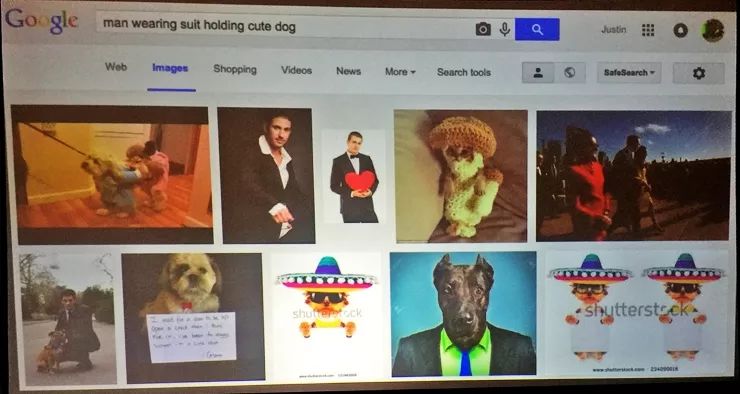
场景识别单独来看是一项简单的任务,在谷歌里搜索“穿西装的男人”或者“可爱的小狗”,都能直接得到理想的结果。但是当你搜索“穿西装的男人抱着可爱的小狗”的时候,就得不到什么好结果。它的表现在这里就变得糟糕了,这种物体间的关系是一件很难处理的事情。

比如只关注了“长椅”和“人”的物体识别,就得不到“人坐在长椅上”的关系;即便训练网络识别“坐着的人”,也无法保证看清全局。我们有个想法是,把物体之外、场景之内的关系全都包含进来,然后再想办法提取精确的关系。
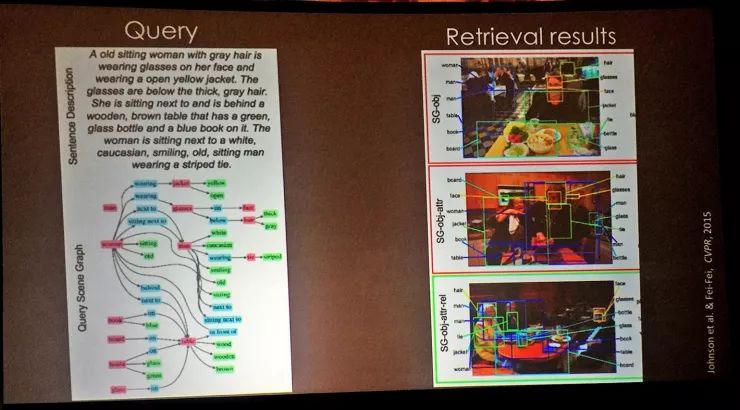
如果我们有一张场景图(graph),其中包含了场景内各种复杂的语义信息,那我们的场景识别就能做得好得多。其中的细节可能难以全部用一个长句子描述,但是把一个长句子变成一个场景图之后,我们就可以用图相关的方法把它和图像做对比;场景图也可以编码为数据库的一部分,从数据库的角度进行查询。
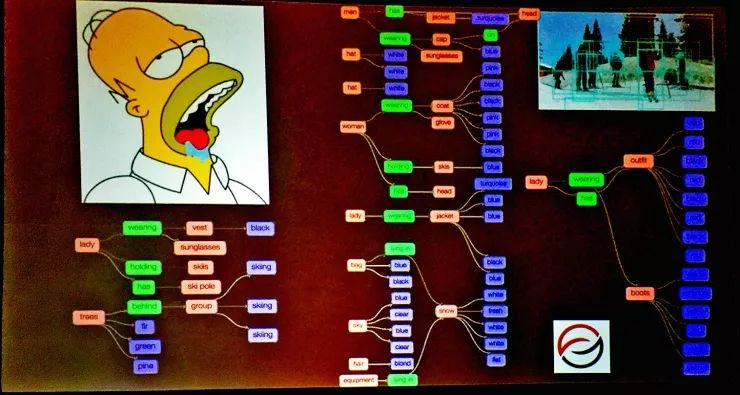
我们已经用场景图匹配技术在包含了许多语义信息的场景里得到了许多不错的量化结果,不过在座的各位可能边听就边觉得,这些场景图是谁来定义的呢?在Visual Genome数据集中,场景图都是人工定义的,里面的实体、结构、实体间的关系和到图像的匹配都是我们人工完成的,过程挺痛苦的,我们也不希望以后还要对每一个场景都做这样的工作。所以在这项工作之后,我们很可能会把注意力转向自动场景图生成。
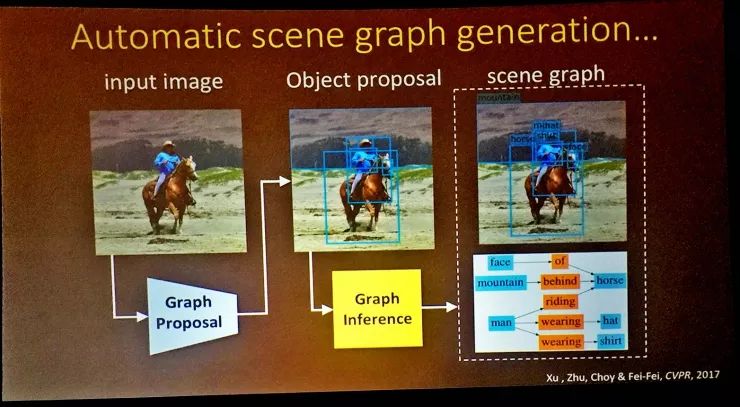
比如这项我和我的学生们共同完成的CVPR2017论文就是一个自动生成场景图的方案,对于一张输入图像,我们首先得到物体识别的备选结果,然后用图推理算法得到实体和实体之间的关系等等;这个过程都是自动完成的。
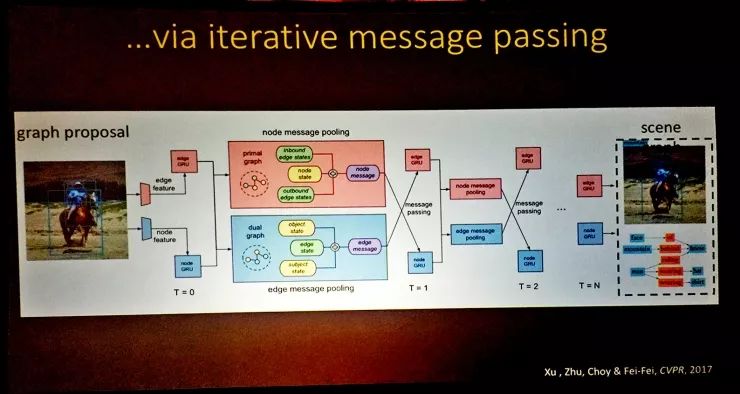
这里涉及到了一些迭代信息传递算法,我先不详细解释了。但这个结果体现出的是,我们的模型的工作方式和人的做法已经有不少相似之处了。
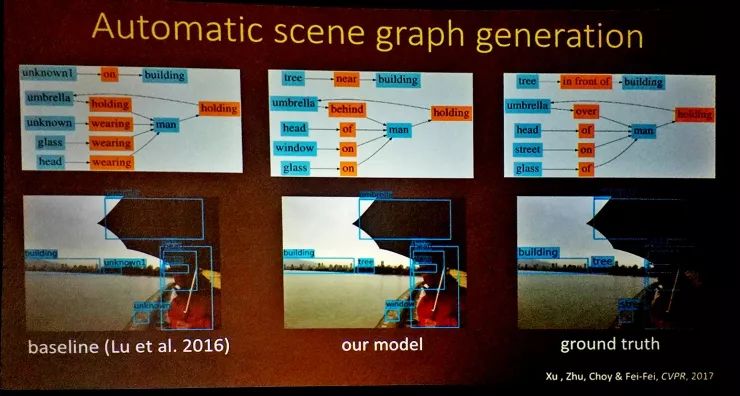
得到这样的结果我们非常开心,这代表着一组全新的可能性来到了我们面前。借助场景图,我们可以做信息提取、可以做关系预测、可以理解对应关系等等。
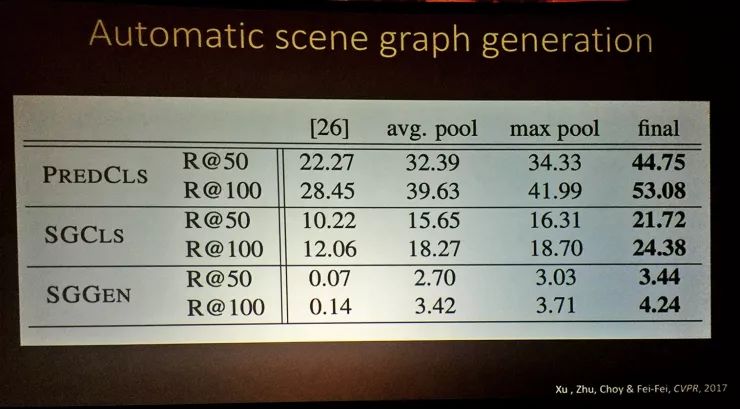
当然了论文发表前我们也做了好看的数据出来。

我们相信Visual Genome数据集也能够帮助很多的研究人员在研究关系和信息提取的算法和模型实验中施展拳脚。
场景识别之后还有什么?

刚才说过了物体识别、关系预测这两项场景理解难题之后,Jeremy 提到的最后一件事情就是,“场景中的gist的根本是三维空间中在物体间和物体表面上以一定形式扩散、重复出现的视觉元素”。不过由于我关注的并不是三维场景理解,我就只是简单介绍一下斯坦福的同事们近期的研究成果。

左侧是从单张图片推测三维场景的布局,展现出其中物体的三维几何特征;右侧是空间三维结构的语意分割。除了斯坦福的这两项之外,三维场景理解还有很多的研究成果,包括使用图片的和点云的。我也觉得很兴奋,将来也不断地会有新东西来到我们面前,尤其是在机器人领域会非常有用。
这样,我们就基本覆盖全了场景的gist,就是看到场景的前150毫秒中发生的事情。视觉智慧的研究当然并不会局限于这150毫秒,之后要考虑的、我们也在期待的还有两项任务。

我的研究兴趣里,除了计算机科学和人工智能之外,认知神经科学也占了相当的位置。所以我想回过头去看看我在加州理工学院读博士的时候做的一个实验,我们就让人们观察一张照片,然后让他们尽可能地说出自己在照片中看到的东西。当时做实验的时候,我们在受试者面前的屏幕上快速闪过一张照片,然后用一个别的图像、墙纸一样的图像盖住它,它的作用是把他们视网膜暂留的信息清除掉。

接下来我们就让他们尽可能多地写下自己看到的东西。从结果上看,有的照片好像比较容易,但是其实只是因为我们选择了不同长短的展示时间,最短的照片只显示了27毫秒,这已经达到了当时显示器的显示速度上限;有些照片显示了0.5秒的时间,对人类视觉理解来说可算是绰绰有余了。
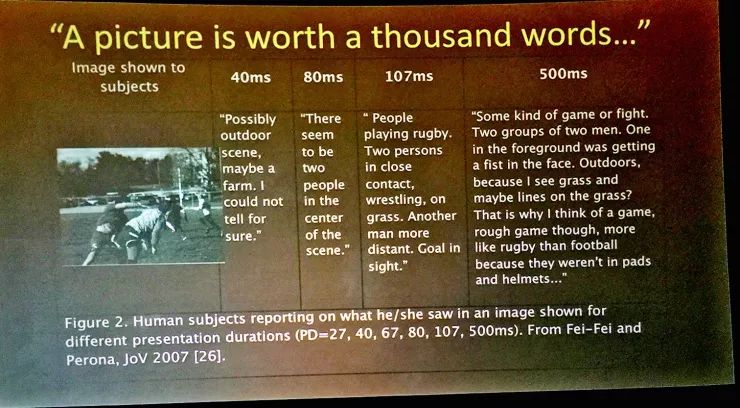
我们得到的结果大概是这样的,对于这张照片,时间很短的时候看清的内容也很有限,500毫秒的时候他们就能写下很长一段。进化给了我们这样的能力,只看到一张图片就可以讲出一个很长的故事。
计算机视觉+语言

我展示这个实验想说的是,在过去的3年里,CV领域的研究人员们就在研究如何把图像中的信息变成故事。

他们首先研究了图像说明,比如借助CNN把图像中的内容表示到特征空间,然后用LSTM这样的RNN生成一系列文字。这类工作在2015年左右有很多成果,从此之后我们就可以让计算机给几乎任何东西配上一个句子。

比如这两个例子,“一位穿着橙色马甲的工人正在铺路”和“穿着蓝色衬衫的男人正在弹吉他”。这让我想起来,2015年的时候我就是在这同一个房间里做过演讲。两年过去了,我们的算法也已经不是最先进的了,不过那时候我们的研究确实是是图像说明这个领域的开拓性工作之一。
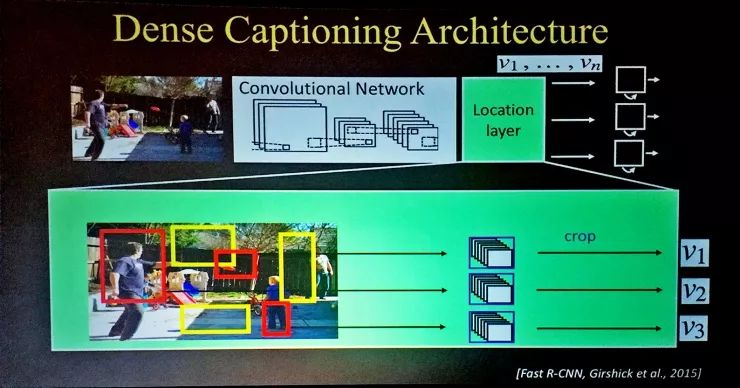
我们沿着这个方向继续做研究,迎来的下一个成果是稠密说明,就是在一幅图片中有很多个区域都会分配注意力,这样我们有可以有很多个不同的句子描述不同的区域,而不仅仅是用一个句子描述整个场景。在这里就用到了CNN模型和逻辑区域检测模型的结合,再加上一个语言模型,这样我们就可以对场景做稠密的标注。

比如这张图里就可以生成,“有两个人坐在椅子上”、“有一头大象”、“有一棵树”等等;另一张我的学生们的室内照片也标出了丰富的内容。

我们的稠密标注系统也比当时其它基于滑动窗口的方法表现好得多。

在最近的CVPR2017的研究中,我们让表现迈上了一个新的台阶,不只是简单的说明句子,还要生成文字段落,把它们以具有空间意义的方式连接起来。

这样我们就可以写出“一只长颈鹿站在树边,在它的右边有一个有叶子的杆子,在篱笆的后面有一个黑色和白色的砖垒起来的建筑”,等等。虽然里面有错误,而且也远比不上莎士比亚的作品,但我们已经迈出了视觉和语言结合的第一步。

而且,视觉和语言的结合并没有停留在静止的图像上,刚才的只是我们的最新成果之一。在另外的研究中,我们把视频和语言结合起来,比如这个CVPR2017的研究,我们可以对一个说明性视频中不同的部分做联合推理、整理出文本结构。这里的难点是解析文本中的实体,比如第一步是“搅拌蔬菜”,然后“拿出混合物”。如果算法能够解析出“混合物”指的是前一步里混合的蔬菜,那就棒极了。我的学生和博士后们也都觉得这是让机器人进行学习的很重要的一步。
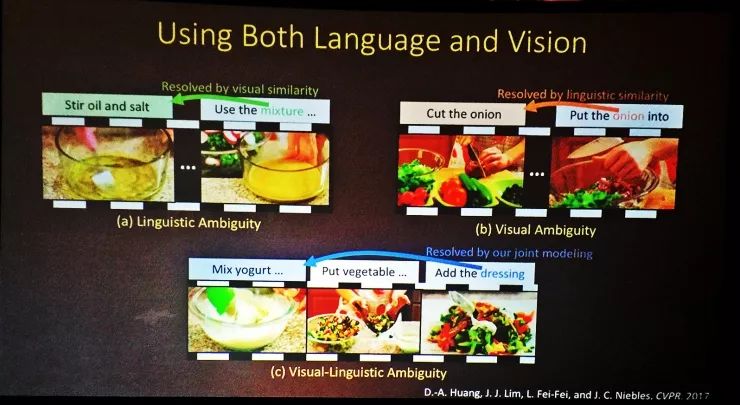
这里的机会仍然是把视觉问题和语言结合起来,如果只用视觉的方法,就会造成视觉上的模糊性;如果只用语言学的方法,就会造成语言上的模糊性;把视觉和语言结合起来,我们就可以解决这些问题。
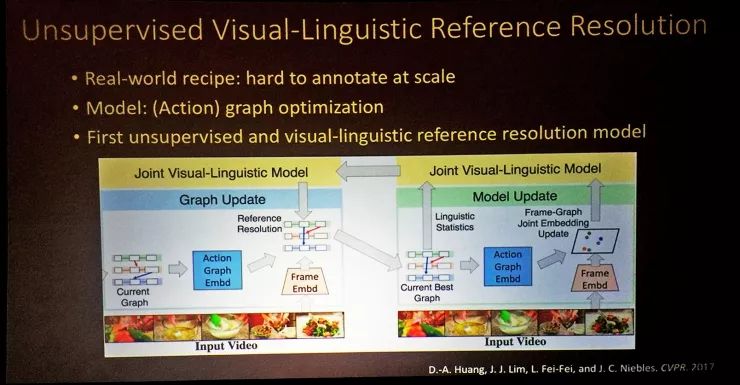
太细节的还是不说了,我们主要用了图优化的方法在实体嵌入上解决这些模糊性。我们的结果表明,除了解决模糊性之外,我们还能对视频中的内容作出更广泛完善的推理。
任务驱动的计算机视觉

在语言之后,我想说的最后一个方向是任务驱动的视觉问题,它和机器人的联系也更紧密一些。对整个AI研究大家庭来说,任务驱动的AI是一个共同的长期梦想,从一开始人类就希望用语言给机器人下达指定,然后机器人用视觉方法观察世界、理解并完成任务。

比如人类说:“蓝色的金字塔很好。我喜欢不是红色的立方体,但是我也不喜欢任何一个垫着5面体的东西。那我喜欢那个灰色的盒子吗?” 那么机器,或者机器人,或者智能体就会回答:“不,因为它垫着一个5面体”。它就是任务驱动的,对这个复杂的世界做理解和推理。

最近,我们和Facebook合作重新研究这类问题,创造了带有各种几何体的场景,然后给人工智能提问,看它会如何理解、推理、解决这些问题。这其中会涉及到属性的辨别、计数、对比、空间关系等等。
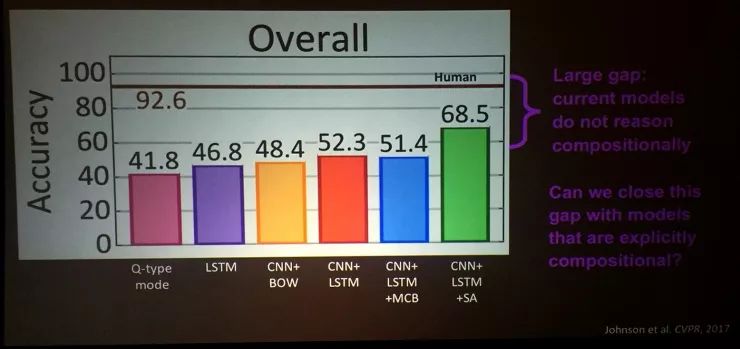
我们在这方面的第一篇论文用了CNN+LSTM+注意力模型,结果算不上差,人类能达到超过90%的正确率,机器虽然能做到接近70%了,但是仍然有巨大的差距。有这个差距就是因为人类能够组合推理,机器则做不到。

在一个月后的ICCV我们就会介绍新一篇论文中的成果,我们把一个问题分解成带有功能的程序段,然后在程序段基础上训练一个能回答问题的执行引擎。这个方案在尝试推理真实世界问题的时候就具有高得多的组合能力。

模型的实际表现当然不错,所以论文被ICCV接收了。比如这个例子里,我们提问某种颜色的东西是什么形状的,它就会回答“是一个立方体”这样,表明了它的推理是正确的。它还可以数出东西的数目。这都体现出了算法可以对场景做推理。

我们也在尝试环境仿真,我们用三维渲染引擎建立执行任务的环境,让学习策略的机器人在其中学习动作,比如把篮球放进微波炉,也需要它把这个任务分解成许多步骤然后执行。
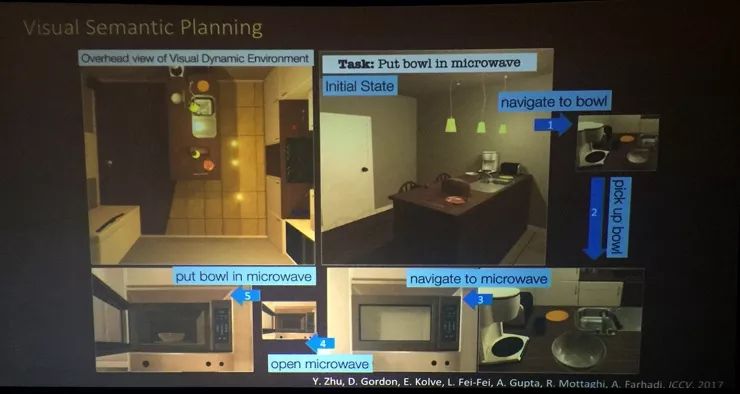
我们采用了一种深度语意表征,然后用不同难度的任务测试它,中等难度的任务可以是从厨房里多个不同的地方拿取多个不同的物体,然后把它们放在指定的地方;难的任务可以是需要策略让它寻找之前从来没有见过的新物体。

视觉相关的任务说了这么多,我想把它们组织成这三类。
首先是除了物体识别之外的关系识别、复杂语意表征、场景图;
在场景gist之外,我们需要用视觉+语言处理单句标注、段落生成、视频理解、联合推理;
最后是任务驱动的视觉问题,这里还是一个刚刚起步的领域,我相信视觉和逻辑的组合会在这个领域真正携起手来。

人类视觉已经发展了很久,计算机视觉虽然在出现后的60年里有了长足的进步,但也仍然只是一门新兴学科。我以前应该有提过我边工作边带孩子,这也就是一张我女儿二十个月大时候的照片。

看着她一天天成长的过程,真的让我觉得还有许许多多的东西等着我们去研究。视觉能力也是她的日常生活里重要的一部分,读书、画画、观察情感等等,这些重大的进步都是这个领域未来的研究目标。

谢谢大家!
(完)
————— 给爱学习的你的福利 —————
3个月,从无人问津到年薪30万的秘密究竟是什么?答案在这里——崔立明授课【推荐系统算法工程师-从入门到就业】3个月算法水平得到快速提升,让你的职业生涯更有竞争力!长按识别下方二维码(或阅读原文戳开链接)抵达课程详细介绍~

————————————————————











