本文为《程序员》原创文章,未经允许不得转载,更多精彩请订阅2017年《程序员》
智能金融,顾名思义,就是人工智能在金融领域的应用。智能金融还是一个比较新的方向,整体上还处于探索的阶段。首先,我们需要澄清它和其他一些概念如金融科技、互联网金融的区别。
过去几年来,“金融科技”(Fintech)成为一个热门词。但是大部分的金融科技产品,例如银行借贷、券商研究、早期投资、对冲基金、外汇支付等还是停留在对金融信息获取、统计量化模型、交易完成的信息技术(IT)保障上。智能金融则再进一步,试图用机器学习、知识表现等人工智能的分支来做决策支持。
智能金融也要和“互联网金融”区分开来。互联网金融(互金)是现在大家提到“金融科技”时最容易想到的,在国内几乎成了“P2P”的代名词。互联网金融关注的是把交易行为或者获客渠道搬到互联网上来,其中会有一些智能的应用,但总的来说还是传统人力服务的互联网化,和“智能金融”的差距很大。
智能金融也借力于金融科技和互联网金融的发展。金融机构开始相信技术的价值不仅仅是依赖经验和人脉,一些统计算法(如时间序列分析)的成功也为更智能算法的应用起到了教育、冷启动市场的作用。大量的金融数据互联网化也提供了智能金融不可或缺的训练数据。
智能金融现在中国市场上最常见的是征信,这和互联网金融的发展息息相关。个人征信可能有上千家在做;企业征信也在起步,最初步的是各种工商注册数据处理。在美国,我们接触较多的有两个领域,一个是传统大银行里的数据分析,另一个是交易策略的生成,类似桥水(Bridgewater)、Kensho在做的。当然人工智能分支很多,其他的分支和金融的结合也有很多应用,如图1所示。
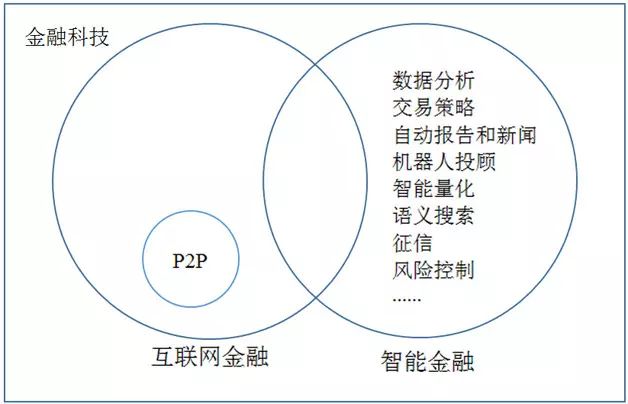
图1 智能金融的内涵
据我们了解,这些机构里的人工智能,可以分为机器学习和语义分析两大块。从算法层面讲没有什么太过神奇的东西,很多都是十几年前就知道的方法。不管是征信还是策略生成,或者信息挖掘,基本都可以映射到“语义数据集成”这个经典的老问题上,进步一些的就是语义搜索。当然解决这个问题也不简单,需要机器学习、数据库、本体和知识库等多种方法的混合应用。所以当前智能金融公司招聘的人才,主要是这样的人。
就如何在国内展开智能金融应用,我们接触了很多金融界人士,包括风投、孵化器、券商、私募、银行、交易所、研究所、监管机构等等,涉及的问题有行业研究、企业研究、尽职调查、交易撮合、并购、投资顾问、理财顾问、个人征信、企业征信、风险控制、系统风险防范等诸多领域。尽管金融面临的具体问题千差万别,但总的来说集中在“价值判断”和“风险评估”两个大方面。
但是如何做价值判断和风险评估,就是见仁见智的问题,没有统一的方法,甚至有时候看起来纯粹是“拍脑门”。比如并购业务怎么找到合适的壳公司,有一个经验模型是“三分钟找壳法”,包括七八项判断标准,其中一条是实际控制人应该是大学毕业、40-50岁之间。这有什么道理?但是在一些场景上可能就是有意义的。再如一位VC合伙人,判断是否投资一个项目,基本上5分钟就可以凭直觉做出,只看商业计划书里的三五页、项目的来源和谁在背书,很快做最终的决定。
乍看起来一点也不“理性”的决策流程,其实是很有道理的。金融决策的特点是涉及的因素实在是太多了。金融产品可能是最复杂的商品,一份股转书有两百多页,还有大量的年报、半年报、研究报告、公告、反馈意见、尽职调查结果……但很少有人是看了这几百页的材料再做决定的,往往就凭经验和人脉,直接“变魔术”,做出决定。
机器能不能也“变魔术”,替代人做出价值判断和风险评估呢?市场上不乏这样的探索者。但是深入理解金融和人工智能的人会知道,人工智能和市场研究员抢饭碗的担心在短期内是多余的——虽然长期看可能会发生。
我们认为,想让机器“变魔术”,要依次解决五个问题(每一个问题都依赖前一个问题的解决)。现在我们依靠人“变魔术”,是因为这个五个问题(特别是后面的问题)还没有完善的解决方案,还需要人的经验和人脉(信任、背书)来引导。但是每一个问题的解决,都可以更多地利用机器的力量,获得更智能的工具来做出价值判断和风险评估,人则有更多的时间去做只有人才能获得的“洞察”(insights)。
第一个问题是从物理世界获得数字化的数据。大多数买方和卖方的数据,其实是很难被机器、甚至人去访问的。很多时候还是需要人面对面的交谈、亲临现场的访问,才能得到决策的依据,甚至仅仅是获得一个行业里中小企业的名录都是很困难的事。现在有了新三板系统,有了巨潮网上的信息披露,数据获取成本才降下来,并使后续的机器处理成为可能。最近股转系统要求券商留挂牌过程中的电子底稿,长远看就是特别有意义的事。
第二个问题是从“脏数据”中获得“干净数据”。数字化数据中依然有大量的“脏数据”,例如新三板披露材料中有1/4是扫描件,大量的公告是不规范的PDF文件,难以做文本处理,大量的财务数据用不规范的表格展示。至于网上千差万别的新闻数据、研究报告就更“脏”了,很多数据(如财务、股权结构、股东结构)隐藏在图片中,难以提取、统计、汇总、比较。XBRL(金融数据结构化)报表只解决了一小部分问题,而且还没有对公众开放。现在各家机构都在用实习生、初级研究员做这些数据的提取工作,极为浪费人力。
第三个问题是从数据中辨认金融“实体”。实体(entity)包括企业、投资机构、人(高管、股东、投资人、合伙人等)、行业、产品、事件、案例、法规等等。数据不仅是一堆汉字和数字的组合,一次定增公告里会提到项目、产品、定增对象(人或者机构),供应商和收入来源里会提到上下游企业,投资人简历里会提到学历和以前的职务。这些实体和它们的属性往往很有价值。例如一家券商曾委托我们筛选股东里不含契约型基金的公司、在江浙地区的投资基金等等,这就需要我们不仅把股东、基金的名字看成字符串,而且要理解它是什么样的机构、有哪些地域属性、分类属性等。这些数据分散在很多地方,如股转系统、工商网站、行业协会、机构官网。只有做好实体的识别,才能把这些信息串起来。
第四个问题是发现金融实体之间的深入关系,形成“知识图谱”。金融决策需要的洞察,往往不是一眼能看出来的。例如投资公司对企业的投资,往往通过各种子公司和“壳”来完成,仅仅依赖股东披露或工商注册信息(包括子公司、孙公司的工商信息)是不够的,还需要一些规则和数据挖掘来发现隐藏得很深的关系。我们曾对一家投资公司做了个案研究,发现单纯从披露数据和工商数据,只能获得一半的投资事件,而通过深度规则挖掘,才能获得比较完整的投资组合。此外如行业对标关系、行业上下游关系、供应链关系、股权变更历史、定增与重大资产重组的关系、多张财务报表之间的数据交叉验证,都需要深入关联来自多个源头、多个时期、多个企业之间的数据关系。
第五个问题是在知识图谱的基础上表达业务逻辑。挂牌、定增、并购、对冲、二级市场交易等等,每一个业务场景都会有自身的逻辑。我们遇到很多研究员、投资总监在学习Python、R、Matlab,因为他们痛感自己脑子里的逻辑,难以用文字或者Excel表格表达出来,市场上也没有一个好用的工具,帮助他们在数据的基础上把被验证有效的业务逻辑清晰地表达出来,以免总是要做简单重复劳动。逻辑的表达可能是看数据的一些方式、处理数据的一些规则、展示数据的一些模板。一旦可以把逻辑数字化,一些比较初级的价值判断和风险评估就可以由机器来做了。
解决了这五个问题,我们就拥有了“变魔术”的有力道具,如图2所示。当然,这并不是说,我们需要把这五个问题都解决了,机器才能辅助人来“变魔术”。每个层次都可以比之前的层次更能帮助人快速发现洞察、做出判断。每多一些机器的辅助,人就可以更好地集中精力去完成机器不擅长的工作,当好“魔术师”的角色。
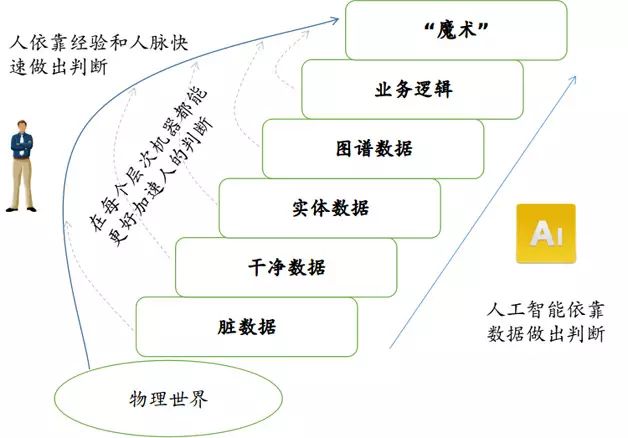
图2 金融数据发展的五个阶段
那么,当前这个阶段,技术发展到了哪一步呢?就金融领域的应用而言,我们认为美国领先中国很多。如表1所示,美国在各个层面都有相应的服务提供商,而中国仅仅在干净数据层面有了成熟的解决方案。在实体数据层面,中国还只是刚刚开始(如一些行业数据库和工商信息服务商),而美国七八年前就已经有了成熟的服务。再往上的图谱数据和业务逻辑,中国基本还没有对应的服务者。不过也需要指出,业务逻辑和“魔术”的层面,美国金融领域的尝试也是初步的,现在还很难说已经走通了。
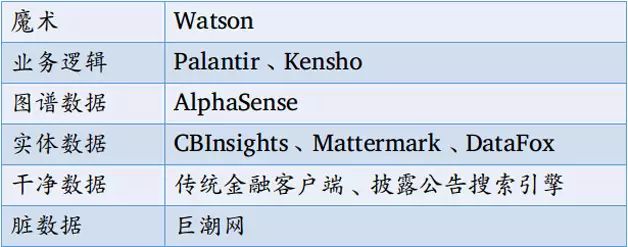
表1 不同层级的智能金融服务提供商
总结来说,美国的成熟行业前沿(state of the art)在图谱数据层面,而中国在干净数据层面。
因此,我们认为,当前中国的金融智能化,应该聚焦于基础数据的实体化和图谱化,让数据更可信、更好用、更容易被发现和获得。
数据发展的5个阶段,也可以从分析的角度来看。数据质量的提升,依赖于不同层面分析方法的应用,总体如表2所示。
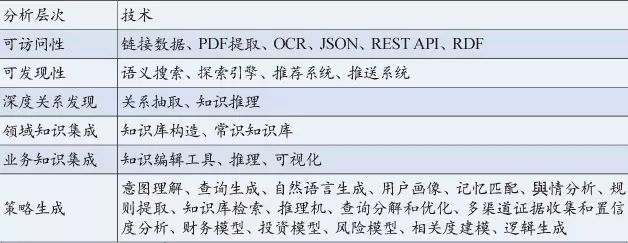
表2 金融数据图谱化的分析技术
1.首先是基础数据的可访问性。这是其他一切事情的基础。基础数据如果被封闭在部门的高墙里,或者封闭在Excel表格、PDF文件、专用的数据终端里,我们不得不花费很多人力和时间去复制、粘贴,甚至进行手工录入这种高度浪费人力的工作。此外现在是移动时代,人们在手机上经常需要做一些快速的轻量级的信息处理,传统的金融数据工具都太重,可访问性不好。
提高可访问性的主要技术手段是把数据转化为“链接数据”(linked data),就是方便在Web上访问和相互链接的数据。里面涉及爬虫、PDF文本化、表格提取、图像OCR、文本清理等技术,也利用JSON/REST API或者新一代的语义数据接口(如RDF和JSON-LD),提供不同应用之间跨平台的对接。
2.数据的可发现性。金融数据的问题不是数据太少,而是数据太多。怎么从纷繁芜杂的数据里找到少数真正有价值的数据?怎么快速定位只是模模糊糊有点印象的数据?这些是后续分析的基础——因为金融分析一定是人和机器协作的过程,不是机器有个银弹算法就能搞定的,一定要提高对人友好的数据可发现性。
可发现性主要是利用语义搜索引擎和探索引擎。金融搜索引擎的背后核心技术是高质量的知识图谱和大量的业务规则,帮助实现联想、属性查找、短程关系发现。探索引擎,如分面浏览器,也是在知识图谱的基础上,则提供了人机协作的界面,让人对数据的探索过程可以很方便地被记录、迭代、重用。此外推荐系统和推送系统也非常有用,帮助金融用户聚焦在关键数据上,更省时省力地做投前发现和投后跟踪。
3.数据深度关系的发现。找到那些人力根本看不出来的关系。人最多能看一两百个维度,机器可以看成千上万个维度。比如一个企业的重大风险提示和当前发生的新闻事件之间的关系,人力是很难监控和判断这么多企业的那么多相关动态的,机器可以帮助我们。
这一部分依赖的技术主要是各种自然语言理解的方法,特别是关系抽取(Relation Extraction)。此外知识推理的方法也非常有用,通过推理规则可以发现隐藏得很深的关系。
4.领域知识的集成。金融涉及国民经济各个领域,官方分了一百多个领域只是为了管理的方便,真正可用的领域大概有几百个。这些领域都或多或少需要集成领域的知识。不管是投资有色金属还是珠宝,领域的关键概念、产品分类、关键人物、市场竞争情况等,都需要梳理。
这一部分用到的主要技术是领域知识库或“本体”(ontology)的构造和对齐,有文档结构分析、篇章分割、常用词和新词发现、中文分词、实体提取、实体消歧、实体链接、实体对齐、关系提取、本体学习、规则建立、本体映射等流程。另外常识知识库如Freebase、DBPedia、Wikidata也是有用的。
5.金融业务知识的集成。并购、征信、融资、资管、对冲、二级市场交易等等,在每一个具体的业务场景上,都需要业务逻辑,然后在基础数据和领域知识的基础上表达这个逻辑。并购找壳有逻辑,股票日内交易预警有逻辑,这些逻辑要在数据之上表达为模型。需要一个系统来方便金融人士表达这些模型、重用这些模型、学习这些模型。
这一部分主要是用到知识建模和推理的技术。例如Palantir提供了一个“本体编辑器”来帮助金融人士来表达他们对数据的理解,把数据探索的过程表达为可重用的模型。此外我们通常也会利用可视化技术来提高从业者的工作效率。
6.策略的生成。到了最高的层面,就又是“魔术”了,机器辅助我们做出了价值判断、风险判断,通过过往的案例或者既定的逻辑,提供给我们可行的策略,或者策略的决策依赖点。
这个层面可以说是人工智能技术的集大成。从用户交互角度有意图理解、查询生成、自然语言生成、用户画像、记忆匹配等;从数据层面有與情分析、规则提取、知识库检索、推理机、查询分解和优化、多渠道证据收集和置信度分析等;从业务层面有财务模型、投资模型、风险模型、相关度建模、逻辑生成等。
上文说的数据问题和分析问题,需要很大的投入才能构造出完整可用的系统。没有底层的基础的工作,就想跳到“魔术”的层面,是不切实际的。当然,这并不意味着底层的工作、中间步骤本身就没有实用价值。比如仅仅是基础的实体数据,解决它们的跨平台的可访问性和可发现性,就能解放很多人力出来。中国的很多金融机构都在用实习生和初级分析师做简单重复劳动,复制粘帖这些数据,这是迫切需要改变的。我们从知识图谱的四个层面来探讨如何设计系统:
金融和所有其他领域一样,迟早要被互联网渗透,被人工智能渗透。现在我们靠经验和人脉来做出很多决策,是在数据不足、分析能力低下的情况下不得不做的妥协。经验和人脉以后依然很重要,但是我们会越来越多地依靠机器的帮助。不同于AlphaGo能超越围棋人类冠军,金融辅助判断工具超过最优秀的投资人还比较困难,但是人工智能可以提供大量的辅助决策工具,让投资人在形成逻辑链条的过程中,更容易地获得数据和分析层面的支持,大大提高工作效率。
在整个技术链条中,知识图谱居于核心的地位,可以说是金融报表电子化(以XBRL为代表)以来又一次质的飞跃。知识图谱是金融数据分析从简单的量化模型走向更为复杂的价值判断和风险评估必经的一环,是把人的经验和人脉逐步变成可重用、可演化、可验证、可传播的知识模型的方法。在系统的构造中,知识图谱弥补原有数据库的不足,把机器学习、自然语言处理、深度学习这些知识提取方法,领域词表、分类树、词向量、本体这些知识表现方法,RDF数据库和图数据库这些知识存储方法,和语义搜索、问答系统、分面浏览器这些知识检索方法粘合在一起,提供金融智能化的工具集。
上文提到了推进金融智能化的一些问题,但这并不是说智能金融要在遥远的将来才能实现。其实基础的算法都是很常见的,过去15年的语义网、互联数据、知识图谱的发展,也为我们准备了大量的底层数据、开源工具(如图数据库、检索引擎、NLP工具)。现在这个领域到了一个转折点——智能金融需要把多种已经比较成熟的人工智能工具结合起来,具体来说就是知识提取、知识表示、知识存储和知识检索这几个不同的分支,按工程不同阶段的需要象绣花一样配合好,在应用场景上落地——这种结合的条件,目前已经成熟了。
作者简介: 鲍捷,文因互联CEO。Iowa State University博士,研究领域包括神经网络、信息论、机器学习、逻辑与推理、语义网、自然语言处理等。三星S-Voice个人助手个核心设计者、语义网基础国际标准OWL2作者之一。
王丛,文因互联CKO。美国Wright State University辍学博士生,专长知识提取、本体建模、语义推理。曾参与欧盟的大规模知识加速器项目、爱尔兰DERI研究中心RDF规则推理系统等项目。
《程序员》文章推荐阅读:
更多精彩文章请扫描下方二维码,订阅2017年《程序员》(含iOS、Android及印刷版)











