AI科技评论按:近期Yann LeCun的新作《Hierarchical loss for classification》已经放在了arXiv上,联合作者为Facebook人工智能研究院的Cinna Wu和 Mark Tygert。
 在这篇文章中,作者认为在分类任务中,一般的神经网络模型(例如LeCun, Bengio 和 Hinton等人2015年中的模型,其他研究的模型也大多基于此展开的)很少会考虑到类型之间的亲疏关系,例如这些模型的分类学习过程中并没有考虑牧羊犬事实上比摩天大楼更像哈巴狗。在文章中,作者通过“超度规类树”构造了一种新的损失函数,称为“层级损失函数”。这种损失函数因为内含了类型树中不同类之间的亲疏关系,预期中应当能够增强分类学习的效果。不过经过六组实验的对比,作者发现结果并没有显著的改进。作者认为,不管怎么着吧,至少这表明层级损失函数能用。
在这篇文章中,作者认为在分类任务中,一般的神经网络模型(例如LeCun, Bengio 和 Hinton等人2015年中的模型,其他研究的模型也大多基于此展开的)很少会考虑到类型之间的亲疏关系,例如这些模型的分类学习过程中并没有考虑牧羊犬事实上比摩天大楼更像哈巴狗。在文章中,作者通过“超度规类树”构造了一种新的损失函数,称为“层级损失函数”。这种损失函数因为内含了类型树中不同类之间的亲疏关系,预期中应当能够增强分类学习的效果。不过经过六组实验的对比,作者发现结果并没有显著的改进。作者认为,不管怎么着吧,至少这表明层级损失函数能用。
AI 科技评论认为,它不仅能用,还极具潜力,因为LeCun只是用了最简单的“超度规类树”来阐述这种思想,相信在选用更合适的超度规树后,分类学习会得到一个更好的结果。下面我们来看具体内容。
构建层级损失/获得函数
注:由于获得函数(Win Function)与损失函数是同一个内容的相反表示,训练过程其实就是在寻找最小的损失函数或者最大的获得函数。所以接下来只考虑层级获得函数的构建。
构建层级获得函数,首先需要一个类树,也即将待分的所有类按照亲疏关系放到一颗关系树中,每一个类都是类树中的“树叶”。对于一个输入,分类器会映射到类树每个树叶上一个概率值,也即一个概率分布(图中P1-P7)。类树中每个节点处,文章中规定,其对应的概率值为其下所有树叶概率值的和,如图中所示。显然在不考虑计算机的浮点误差的情况下,“根部”的概率应该为1。
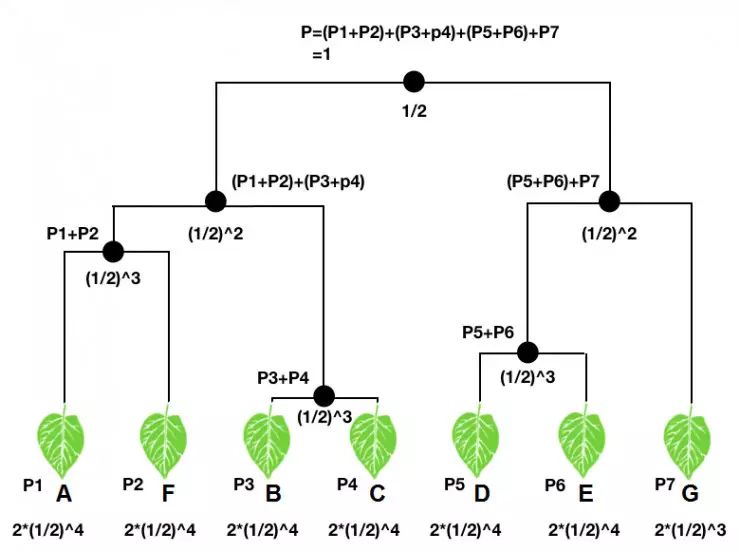
另一方面,对每个“节点”和“树叶”都赋予一个权重。文章中规定,“根部”的权重为1/2,随后每经过一个“节点”,权重乘以1/2,直到树叶;树叶的权重由于是“树”的末端,所以其权重要双倍,如图所示。
如果我们输入一张A的图片,那么我们可以计算其层级获得函数W:
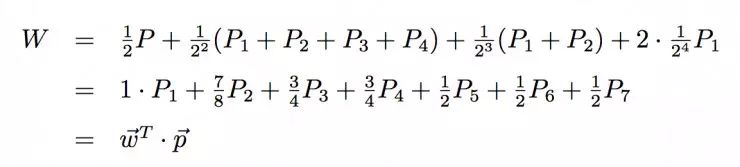
其中
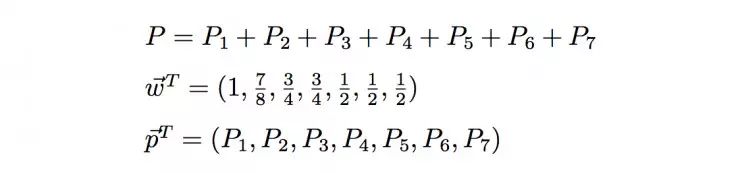
从上面可以看到,事实上层级获得函数的构造非常简单,就是一个结构权重向量和概率分布向量的一个点乘。同样可以看出,不管分类器给出什么样的概率分布,层级获得函数的范围都在[1/2,1]区间内;当P1=1时,W最大,为1;而当P5、P6、P7中的任意一个等于1时,W最小,为1/2。在类树中接近A的类的概率越大,层级获得函数值就越大,所以层级获得函数在某种程度上隐含了类之间亲疏的关系,也构建了分类器准确度的一种度量。
一种改进:获得函数的对数
有时候分类器给出的分布可能不是概率,这时候为了获得一个正则的分布,我们可以使用softmax函数的方法,也即将(x1, x2, x3, ……xn)的分布序列转换成
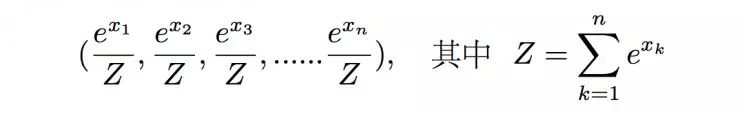
这样的概率分布,显然满足正则性,且分布在(0,1)区间内。这种方法不仅可以对向量进行归一化,更重要的是它能够凸显出其中最大的值并抑制远低于最大值的其他分量。
当采用softmax函数的结果作为概率分布时,最好是使用层级获得函数W的对数进行优化学习,而不是W本身。使用logW进行优化的好处之一就是,当输入样本为多个独立样本时,它们的联合概率将是它们概率的乘积;这时候对这些样本的获得函数W进行求平均就具有了意义(在特殊情况下logW的平均将等于联合概率的对数)。
文章中对logW’ 的构建为:舍掉W中“根部”的项,然后将剩下的部分乘以2,此时W’=(W-1/2)*2的范围在[0,1]之间(其中0对应最错误的分类,1则对应完全正确的分类),相应的,logW’将在(-∞,0]之间。
这就会导致一个问题。当多个独立样本,求log W’的平均值时,只要有一个出现了最错误的判断,那么不管其他样本的结果如何,log W’的平均值都会等于无穷大。所以这种方法对样本及学习过程都有非常严格的要求。
实验结果不理想
作者随后用Joulin等人的fastTest文本分类监督学习模型对层级获得函数进行了六组实验(六个数据集)。结果如下:
说明:
(1)flat表示没有分类的情况(没有分类相当于类树只有一个层级),raw表示用层级获得函数进行训练,log表示用负的层级获得函数的对数进行训练,course表示在层级中使用通常的交叉熵损失函数只分类到最粗糙类(聚合)。
(2)one-hot win via hierarchy 表示喂给层级获得函数的概率分布为独热码(只有一个为1,其余为0)
(3)softmax win via hierarchy 表示喂给层级获得函数的概率分布为softmax函数的结果;
(4)−log of win via hierarchy 表示(3)中层级获得函数的负自然对数;
(5)cross entropy表示使用交叉熵损失函数计算的结果,这种情况相当于类树只有一个层级;
(6)coarsest accuracy 表示最粗糙分类正确的比例结果;
(7)parents’ accuracy 表示父级分类正确的比例结果;
(8)finest accuracy 表示分类到最终每一个类中正确的比例结果。
(9)最后一行的“higher”和“lower”分别表示相应的列中“越大”和“越小”的值越好。
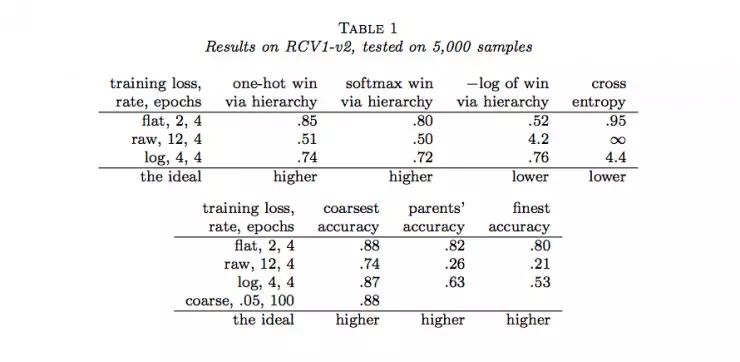
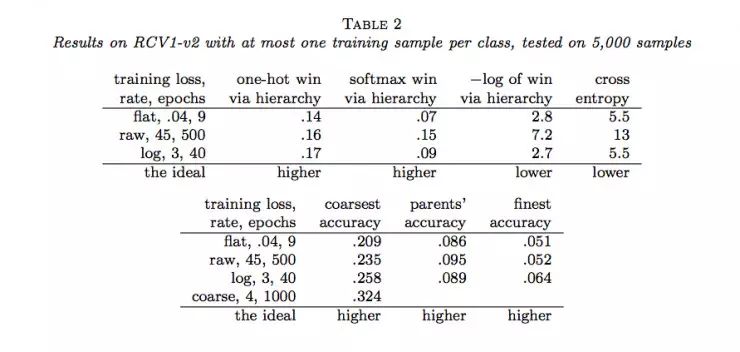
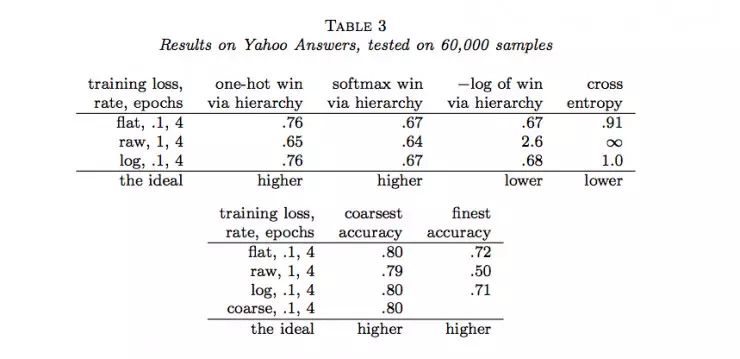
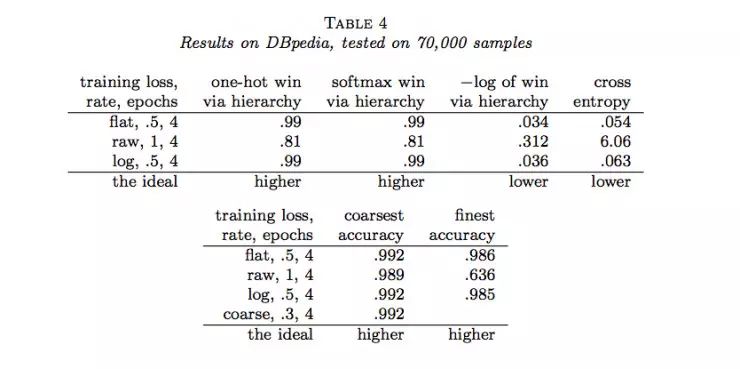
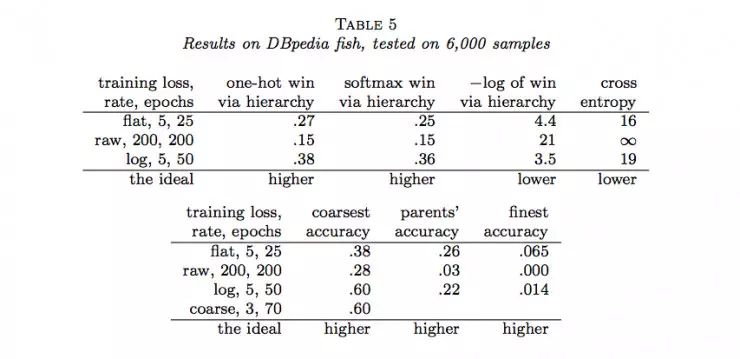
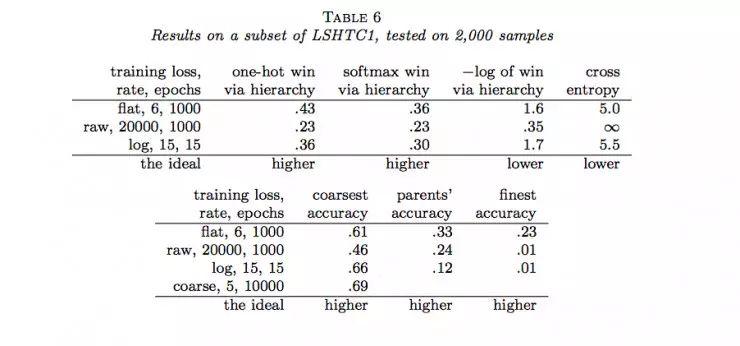 通过以上结果,我们可以看到很多时候,通过层级获得函数优化的结果并没有原来通过交叉熵损失函数优化的结果好。那么,LeCun的这项工作白做了吗?也并不是,至少它表明在一定程度上层级获得函数能够用做作为分类准确度的度量,它暗示了一种可能:当有采用更合适的层级获得函数时,效果可能会超过当前所常用的交叉熵损失函数等方法。
通过以上结果,我们可以看到很多时候,通过层级获得函数优化的结果并没有原来通过交叉熵损失函数优化的结果好。那么,LeCun的这项工作白做了吗?也并不是,至少它表明在一定程度上层级获得函数能够用做作为分类准确度的度量,它暗示了一种可能:当有采用更合适的层级获得函数时,效果可能会超过当前所常用的交叉熵损失函数等方法。
那么机会来了,“更合适”就意味着有多种可能,就看你如何构造了!
————— 给爱学习的你的福利 —————
3个月,从无人问津到年薪30万的秘密究竟是什么?答案在这里——崔立明授课【推荐系统算法工程师-从入门到就业】3个月算法水平得到快速提升,让你的职业生涯更有竞争力!长按识别下方二维码(或阅读原文戳开链接)抵达课程详细介绍~

————————————————————











