
Python 已经成为数据科学家的必选语言,从数据处理到机器学习,它几乎无所不能。本文将探讨一些Python特性,这些特性不仅能帮助你编写更高效、更易读、更易维护的代码,还特别适合数据科学的需求,使你的代码简洁且优雅。
一:推导式(Comprehensions)
Python中的推导式是机器学习和数据科学任务中的一个有用工具,因为它们可以用简洁且易读的方式创建复杂的数据结构。
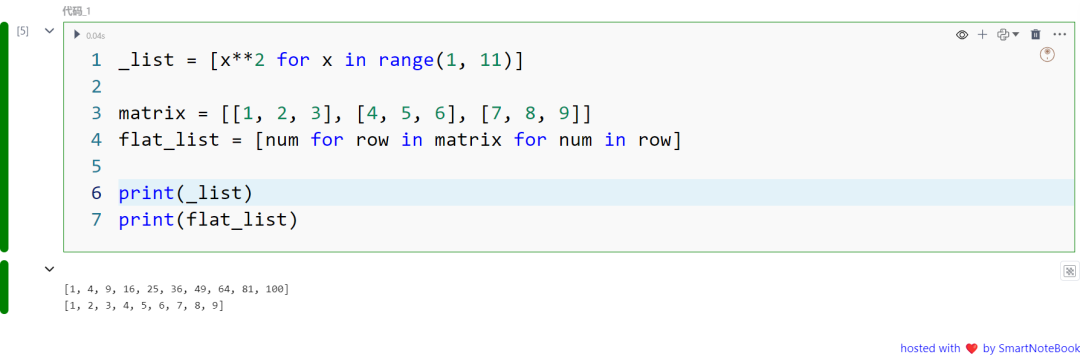
列表推导式可以用来生成数据列表,例如,从一系列数字中创建平方值列表。嵌套列表推导式可以用来展平多维数组,这是数据科学中常见的预处理任务。
_list = [x**2 for x in range(1, 11)]
matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]flat_list = [num for row in matrix for num in row]
print(_list)print(flat_list)
字典和集合推导式分别用于创建数据的字典和集合。例如,字典推导式可以用来创建一个包含特征名称及其在机器学习模型中的重要性得分的字典。生成器推导式在处理大数据集时特别有用,因为它们是即时生成值,而不是在内存中创建一个大型数据结构。这有助于提高性能并减少内存使用。
_dict = {var:var ** 2 for var in range(1, 11) if var % 2 != 0}
_set = {x**2 for x in range(1, 11)}
_gen = (x**2 for x in range(1, 11))
print(_dict)print(_set)print(list(g for g in _gen))

二:枚举(enumerate)
enumerate 是一个内置函数,可以在迭代序列(如列表或元组)的同时跟踪每个元素的索引。这在处理数据集时非常有用,因为它可以轻松访问和操作各个元素,同时跟踪它们的索引位置。
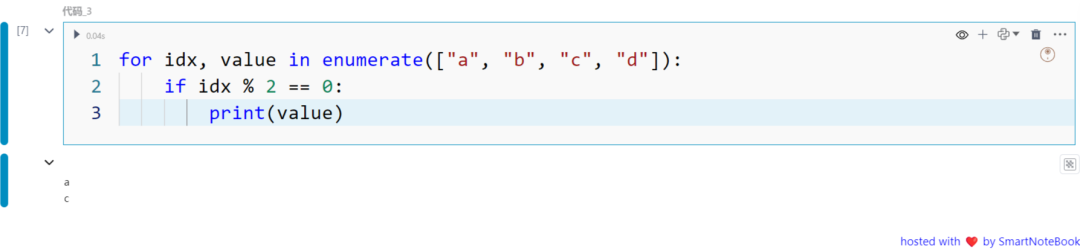
下面的例子中,我们使用 enumerate 来迭代一个字符串列表,并在索引为偶数时打印出相应的值。
for idx, value in enumerate(["a", "b", "c", "d"]): if idx % 2 == 0: print(value)
三:拉链(zip)
zip 是一个内置函数,允许并行迭代多个序列(如列表或元组)。
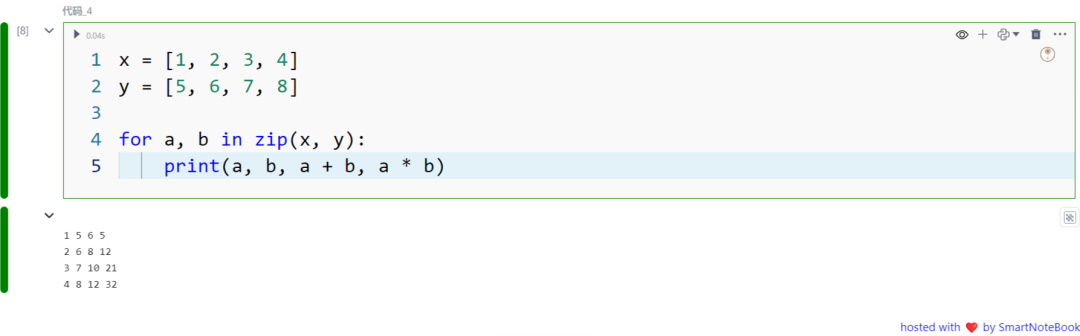
在下面的例子中,我们使用 zip 同时迭代两个列表 x 和 y,并对它们的对应元素执行操作。在这种情况下,它打印出 x 和 y 中每个元素的值、它们的和以及它们的积。
x = [1, 2, 3, 4]y = [5, 6, 7, 8]
for a, b in zip(x, y): print(a, b, a + b, a * b)
四:生成器(Generators)
Python中的生成器是一种可迭代对象,允许即时生成一系列值,而不是一次性生成所有值并将其存储在内存中。这使得它们在处理无法全部装入内存的大数据集时特别有用,因为数据是以小块或批次的方式处理的,而不是一次性全部处理。
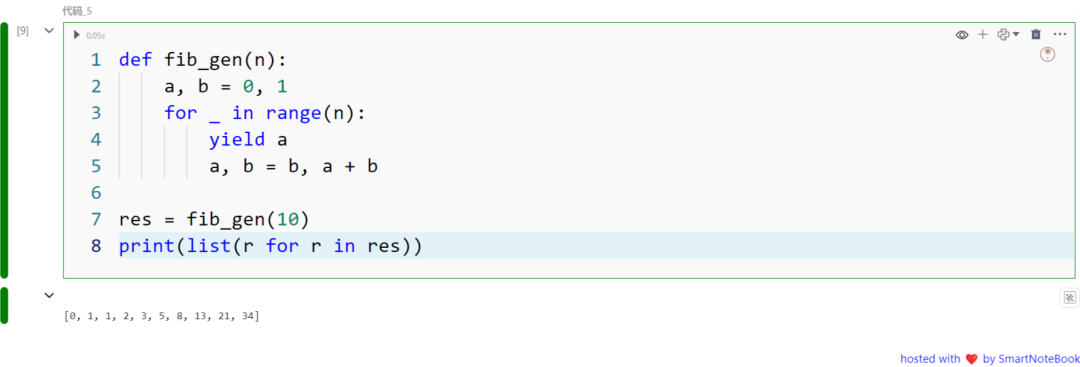
下面我们使用一个生成器函数来生成前 n 个斐波那契数列。yield 关键字用于一次生成序列中的一个值,而不是一次性生成整个序列。
def fib_gen(n): a, b = 0, 1 for _ in range(n): yield a a, b = b, a + b
res = fib_gen(10)print(list(r for r in res))
五:匿名函数(lambda 函数)
lambda 是一个关键字,用于创建匿名函数,即没有名称的函数,可以在一行代码中定义。它们在特征工程、数据预处理或模型评估时非常有用,因为可以即时定义自定义函数。
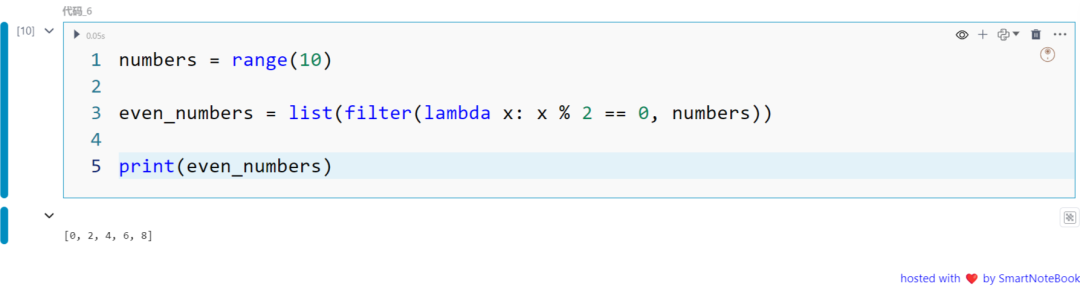
下面我们使用 lambda 创建一个简单的函数,用于从数字列表中筛选出偶数。
numbers = range(10)
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers)
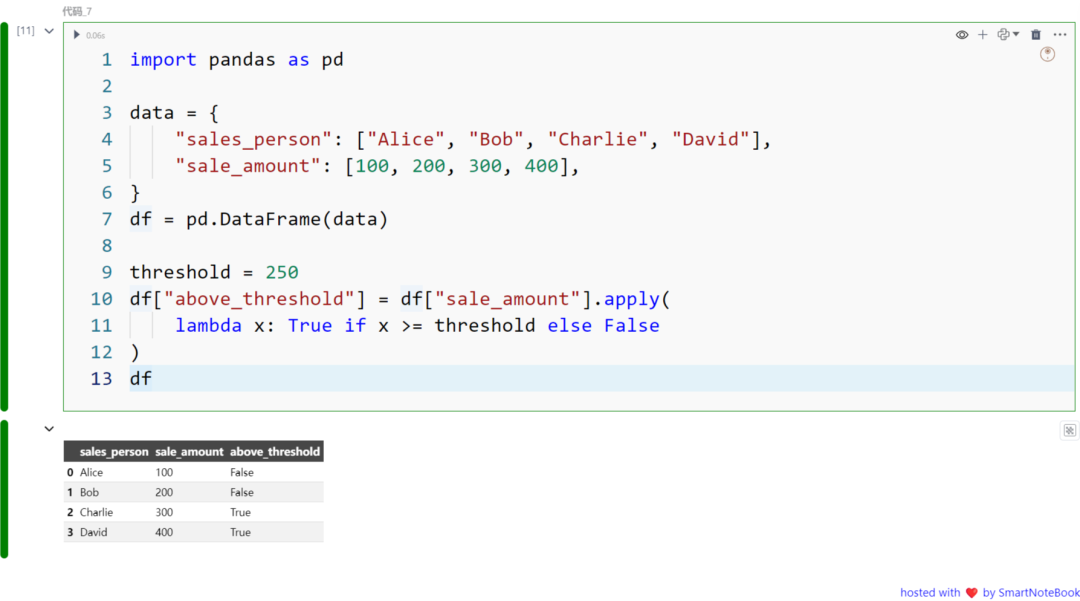
以下是一个使用 lambda 函数与 Pandas 的代码示例:
import pandas as pd
data = { "sales_person": ["Alice", "Bob", "Charlie", "David"], "sale_amount": [100, 200, 300, 400],}df = pd.DataFrame(data)
threshold = 250df["above_threshold"] = df["sale_amount"].apply( lambda x: True if x >= threshold else False)df
六:映射(map)、筛选(filter)、归约(reduce)
map
、
filter
和
reduce
是三个内置函数,用于处理和转换数据。
下面我们在一个管道中使用这三个函数,计算偶数的平方和:
numbers = [1, 2, 3, 4, 5, 6]
squared = map(lambda x: x ** 2, numbers)
evens = filter(lambda x: x % 2 == 0, squared)
sum_of_squares = reduce(lambda x, y: x + y, evens)
print("Sum of the squares of even numbers:",sum_of_squares)

七:any、all
any
和
all
是内置函数,用于检查可迭代对象中的任意或所有元素是否满足某个条件。
这两个函数在检查数据集中某些条件是否被满足时非常有用。例如,它们可以用来检查某一列中是否存在缺失值,或者某一列中的所有值是否都在某个范围内。
在这个示例中,
any
函数检查列表中是否存在任何偶数值,而
all
函数检查列表中的所有值是否都是奇数。





