加入雷锋网,分享 AI 时代的信息红利,与智能未来同行。听说牛人都点了这里。

雷锋网按:2016年1月11日-12日,美国加州圣克拉拉市,AI Frontier大会召开,这次大会聚集了美国人工智能公司里最强悍的明星人物,包括谷歌大脑负责人Jeff Dean、微软AI首席科学家邓力、亚马逊首席科学家Nikko Strom、百度AI实验室主管Adam Coates、Facebook科学家贾杨清等20多位业界大咖,堪称AI业界领域的一场盛事。
作为2017开年最火的人工智能之星Alexa项目的领导者,亚马逊首席科学家Nikko Strom带来了演讲,详细阐述了Alexa里的大规模深度的基本架构、语音识别、语音合成等内容,尤其提到了Alexa为“鸡尾酒派对难题”找到了有效的解决方法。

Nikko Strom,亚马逊首席科学家。1997年于瑞典工学院获得博士学位,之后担任MIT计算机科学实验室研究员,2000年加入初创公司Tellme Networks,2007年加入微软,推进商业语音识别技术的前沿研究。2011年加入亚马逊,并担任首席科学家,领导语音识别及相关领域的深度学习项目,是如今炙手可热的亚马逊Echo和Alexa项目的创始成员。
以下是 AI 科技评论根据Nikko Strom现场演讲整理而成,在不改变愿意的基础上做了删减和补充。
这是Amazon Echo,内置了一个Alexa系统,提供语音服务,你可以把它放到你的家里,你可以跟它对话,并不需要拿遥控器来控制。这个Holiday Season,我们加入了新的白色Echo和Dot,你们当中应该有很多人比较偏爱白色的电子产品。其它的一些产品,并没有内置Alexa系统,但是可以与其连接,比如家里的灯具、咖啡机、恒温器等,你只需要语音,就可以让它们执行一些命令。另外,开发者们通过“Skills”来给Alexa增加更多的功能应用。

如今数百万的家庭里放置了Echo,而它真正地在被使用着,由此我们得到的数据多到疯狂(insane),可能会超出你的想象。我无法告诉你确切的数字,但尽可能往大了去想吧。
大规模深度学习
人的耳朵并非每时每刻都在搜集语音信息,“听”的时间大约占10%,所以一个人成长到16岁的年纪,他/她所听到的语音训练时间大概有14016小时,关于这个数据,我后面会提到一个对比。

回到Alexa,我们把数千个小时的真实语音训练数据存储到S3中,使用EC2云上的分布式GPU集群来训练深度学习模型。
在训练模型的过程中,用MapReduce的方法效果并不理想,因为节点之间需要频繁地保持同步更新,不能再通过增加更多的节点来加速运算。我们可以这样理解,那就是GPU集群更新模型的计算速度非常之快,每秒都有几次更新,而每次更新大约是模型本身的大小。也就是说,每一个线程(Worker)都要跟其它线程同步更新几百兆的量,而这在一秒钟的时间里要发生很多次。所以,MapReduce的方法效果并不是很好。

我们在Alexa里的解决方法就是,使用几个逼近算法(Approximations)来减少这些更新的规模,将其压缩3个量级。这里是我们一篇2015年论文的图表,我们可以看到,随着GPU线程的增加,训练速度加快。到 40个GUP线程时,几乎成直线上升,然后增速有点放缓。80 GPU线程对应着大约55万帧/秒的速度,每一秒的语音大约包含100帧,也就是说这时的一秒钟可以处理大约90分钟的语音。前面我提到一个人要花16年的时间来学习1.4万小时的语音,而用我们的系统,大约3个小时就可以学习完成。
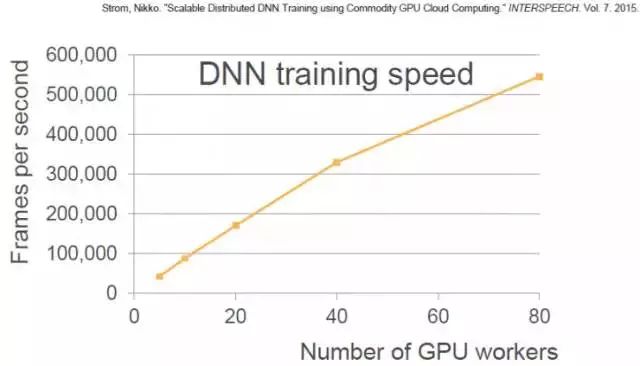
这就是我们大致的深度学习基础架构。
Alexa的语音识别
我们知道语音识别系统框架主要包括四大块:信号处理、声学模型、解码器和后处理。
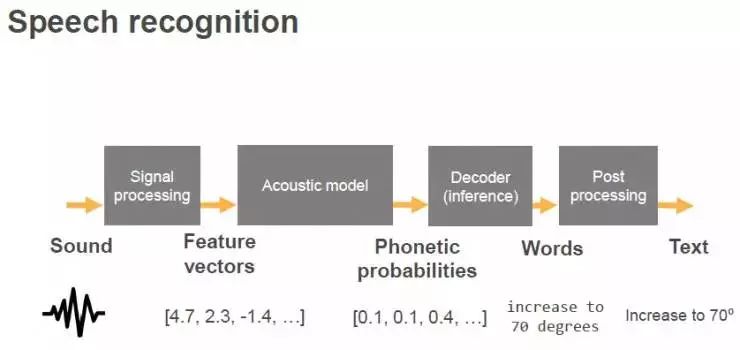
首先我们将从麦克风收集来的声音,进行一些信号处理,将语音信号转化到频域,从每10毫秒的语音中提出一个特征向量,提供给后面的声学模型。声学模型负责把音频分类成不同的音素。接下来就是解码器,可以得出概率最高一串词串,最后一步是后处理,就是把单词组合成容易读取的文本。
在这几个步骤中,我们或多或少都会用到机器学习和深度学习的方法。但是我今天主要讲一下声学模型的部分。
声学模型就是一个分类器(classifier),输入的是向量,输出的是语音类别的概率。这是一个典型的神经网络。底部是输入的信息,隐藏层将向量转化到最后一层里的音素概率。
这里是一个美式英语的Alexa语音识别系统,所以就会输出美式英语中的各个音素。在Echo初始发布的时候,我们录了几千个小时的美式英语语音来训练神经网络模型,这个成本是很高的。当然,世界上还有很多其它的语言,比如我们在2016年9月发行了德语版的Echo,如果再重头来一遍用几千个小时的德语语音来训练,成本是很高的。所以,这个神经网络模型一个有趣的地方就是可以“迁移学习”,你可以保持原有网络中其它层不变,只把最后的一层换成德语的。
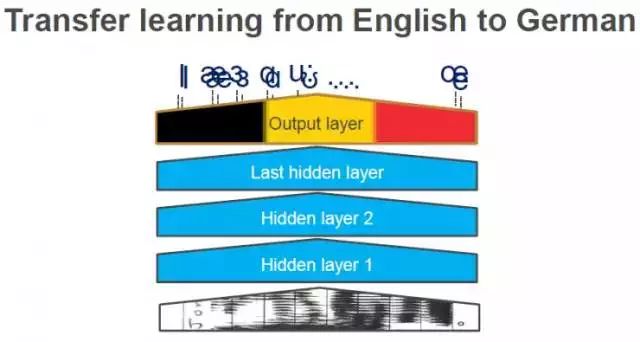
两种不同的语言,音素有很多是不一样的,但是仍然有很多相同的部分。所以,你可以只使用少量的德语的训练数据,在稍作改变的模型上就可以最终得到不错的德语结果。
鸡尾酒派对难题
在一个充满很多人的空间里,Alexa需要弄清楚到底谁在说话。开始的部分比较简单,用户说一句唤醒词“Alexa”,Echo上的对应方向的麦克风就会开启,但接下来的部分就比较困难了。比如,在一个鸡尾酒派对中,一个人说“Alexa,来一点爵士乐”,但如果他/她的旁边紧挨着同伴一起交谈,在很短的时间里都说话,那么要弄清楚到底是谁在发出指令就比较困难了。
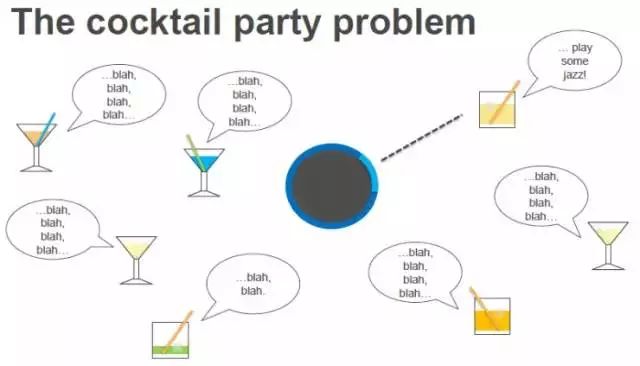
这个问题的解决方案来自于2016年的一份论文《锚定语音检测》(Anchored Speech Detection)。一开始,我们得到唤醒词“Alexa”,我们使用一个RNN从中提取一个“锚定嵌入”(Anchor embedding),这代表了唤醒词里包含语音特征。接下来,我们用了另一个不同的RNN,从后续的请求语句中提取语音特征,基于此得出一个端点决策。这就是我们解决鸡尾酒派对难题的方法。
语音合成
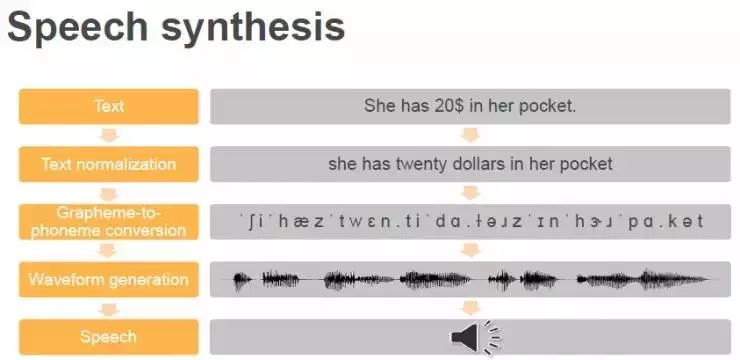
Alexa里的语音合成技术,也用在了Polly里。语音合成的步骤一般包括:
第一步,将文本规范化。如果你还记得的话,这一步骤恰是对“语音识别”里的最后一个步骤的逆向操作。
第二步,把字素转换成音素,由此得到音素串。
第三步是关键的一步,也是最难的一步,就是将音素生成波形,也就是真正的声音。
最后,就可以把音频播放出来了。
Alexa拥有连续的语音合成。我们录下了数小时人的自然发音的音频,然后将其切割成非常小的片段,由此组成一个数据库。这些被切割的片段被称为“双连音片段”(Di-phone segment),双连音由一个音素的后半段和另一个音素的前半段组成,当最终把语音整合起来时,声音听起来的效果就比较好。
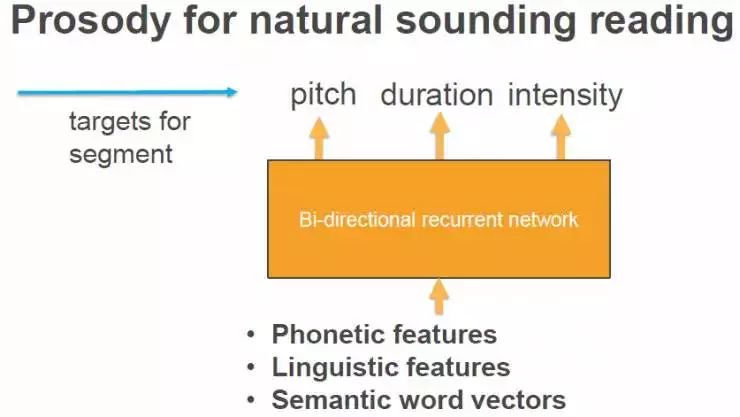
当你创建这个数据库时,要高度细致,保证整个数据库里片段的一致性。另外一个重要的环节是算法方面的,如何选择最佳的片段序列结合在一起形成最终的波形。首先要弄清楚目标函数是什么,来确保得到最合适的“双连音片段”,以及如何从庞大的数据库里搜索到这些片段。比如,我们会把这些片段标签上属性,我今天会谈到三个属性,分别是音高(pitch)、时长(duration)和密度(intensity),我们也要用RNN为这些特征找到目标值。之后,我们在数据库中,搜索到最佳片段组合序列,然后播放出来。











