选自kdnuggets
作者:Savaram Ravindra等
参与:Lj Linjing、蒋思源
机器学习算法可以融合来自车体内外不同传感器的数据,从而评估驾驶员状况或者对驾驶场景进行分类。本文将粗略讲解一下各类用于自动驾驶技术的算法。
如今,机器学习算法正大规模地用于解决自动驾驶汽车产业日益增多的问题。结合 ECU (电子控制单元)传感器数据,我们须加强对机器学习方法的利用以迎接新的挑战。潜在的应用包括利用分布在车体内外的传感器,比如激光探测、雷达、摄像头或者物联网(IoT),融合各类数据进行驾驶员状况评估或者驾驶场景分类。
运行车载辅助系统的相关程序可从数据融合传感系统接收相关信息进行判断。比如,如果系统注意到驾驶员有不适的情况出现,其可以令汽车改道去往医院。这项技术基于机器学习,且能对驾驶员的语音及动作进行识别,同时还有语言翻译。算法总的来说可以分为监督式学习和非监督式学习两大类。二者的区别在于学习方式不同。
监督式学习通过给定的训练集来学习,该学习过程一直持续到模型达到预设的期望值(即错误率达到最小)。监督式学习算法可以分为回归、分类以及异常数据检测或降维算法等几大类。
非监督式学习试图从可用数据集中学习到其内部结构与模式。这意味着,基于提供的数据,算法旨在推导出一种关系,以便根据各个数据之间的相似度来检测模式或者将数据集内部数据自动分类。无监督算法很大一部分可以进一步分类为关联规则学习和聚类算法等。
强化学习算法是介于非监督式学习和监督式学习的另外一类机器学习算法。对于每个训练样本来说,监督式学习有对应的类别标签而非监督式学习没有。强化学习则是将时间延迟和稀疏标签作为奖励机制的一部分。在环境中学习的行为方式取决于奖励机制的设置。强化学习的目的在于了解算法的优劣势并对算法进行改进。该算法有望用于解决实际应用当中产生的大量问题,涵盖从人工智能到工程控制或操作研究的方方面面,而这些都关乎自动驾驶汽车的发展走向。强化学习可分为间接学习和直接学习两大类。
在自动驾驶技术中,机器学习算法的主要任务之一就是持续渲染周围环境并预测周围环境可能产生的变化。这些可以分解为以下三个子类:
目标检测
目标辨认或者目标识别分类
目标定位和运动预判
机器学习算法可大致分为四种:决策矩阵、聚类算法、模式识别和回归算法。每种可以用于两个或多个子任务。比如,回归算法可以用于目标定位以及目标预测或者行为预判。
决策矩阵算法
决策矩阵算法系统地分析、识别及评估信息本身和值之间的关系,这类算法主要用于作出决策。汽车是否需要制动或左转是基于算法对物体的下一次运动的识别、分类和预测给定的置信度。决策矩阵算法是由从各种角度独立训练,并由各决策模型组成的模型矩阵。其优点是将这些预测结合起来进行总体预测,同时降低决策中错误的可能性。AdaBoosting 是其中最常用的一种算法。
AdaBoosting(Adaptive Boosting 的简称)
AdaBoosting 是将多种学习算法组合起来,可用于回归或者分类。与其他机器学习算法相比,该算法克服了过拟合问题,但对异常值和噪音数据通常比较敏感。为了构建出强学习方法,AdaBoost 通常会进行多次迭代,这也是其被称为『适应性』增强算法的原因。AdaBoosting 如同其他提升方法一样通过集成一些弱学习器的学习能力从而进阶成一个强学习器。具体到算法,AdaBoost 在之前学习器的基础上改变样本的权重,增加那些之前被分类错误的样本的比重,降低分类正确样本的比重。之后,学习器将重点关注那些被分类错误的样本。这样的结果就是我们将得到一个比弱学习器的分类器精度更高的分类器。
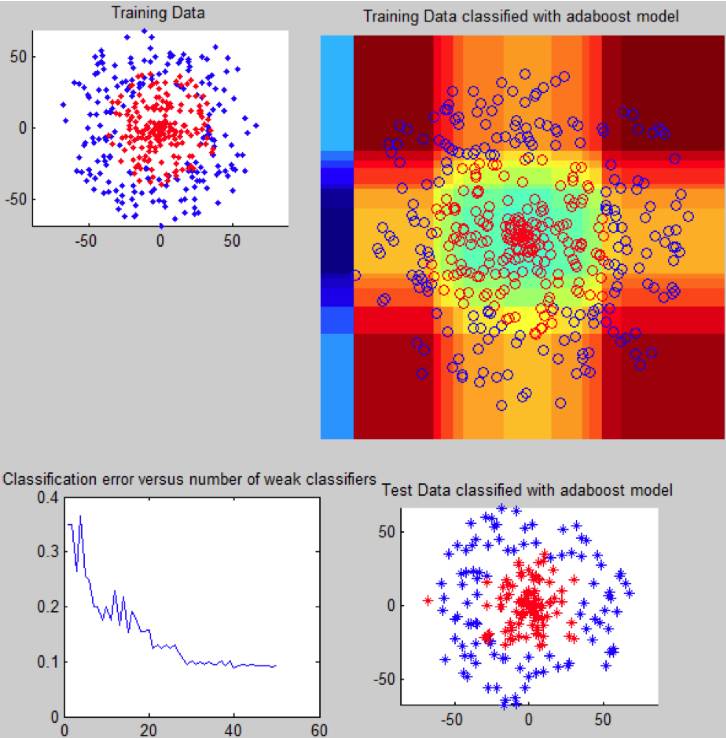
AdaBoost 有助于将弱阈值分类器提升为强分类器。上图具体展示了 AdaBoost 的实现的场景。弱分类器尝试在数据维度中取得一个理想阈值,使得数据能分为两类。分类器在迭代以及每个分类步骤之后得到调用,改变错误分类样本的权重,从而创建了一个类似强分类器的级联弱分类器。
聚类算法
遇到某些情况(比如系统采集的图像不清晰,难以用于定位和检测;或者使用分类算法有可能跟丢检测对象),系统无法对目标进行分类并汇总报告。其原因也许包括数据不连贯,数据样本太少或图像分辨率低等。聚类算法能够专门从数据中发现结构,通过分层和设置质心点的方法来建模。所有方法都旨在利用数据的内在结构将数据分门别类,且保证每类的数据拥有最高的相似性。K-均值聚类、层次聚类和多类神经网络是其中最具代表性的算法。
K-均值聚类
K-均值聚类是一种十分出名的聚类算法。该算法将样本聚类成 k 个集群(cluster),k 用于定义各集群的 k 个质心点。如果一个点比其他任何质心点更接近该簇初始的质心点,那么这个点就存在于该簇类中。质心点的更新则根据计算当前分配的数据点到簇类的欧氏距离来进行。将数据点归于某个集群则取决于当前的质心点是哪些。
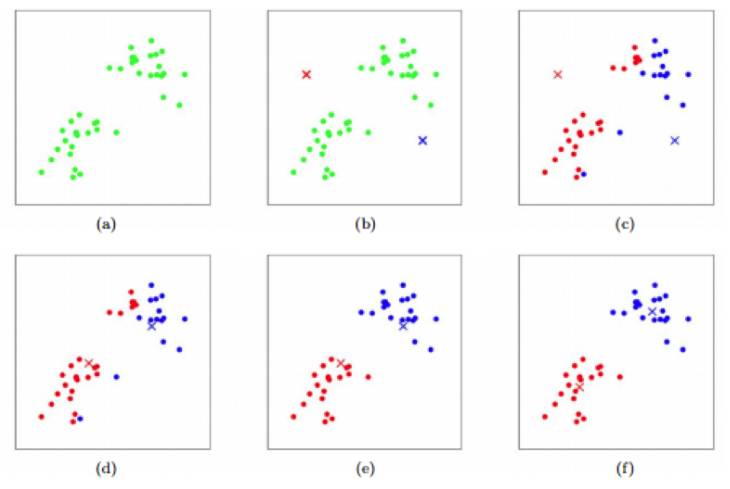
K-means 算法示意图。叉表示各集群质心点,点表示训练数据(a)原始数据集(b) 随机设定的初始质心点(c-f) 两轮迭代之后的数据分布。每个训练数据在每次迭代中分配给最接近的聚类质心点,将该类数据的均值作为聚类质心,更新聚类质心点。
模式识别算法(分类)
高级驾驶辅助系统(ADAS)的传感器获得的图像由各种环境数据组成,但确定对象类别须滤掉图像。所以我们需要滤除无关数据来实现。在分类对象之前,模式识别在数据集中是很重要的一步。这种算法被称为数据简化算法。
数据简化算法有助于减少对象的边和聚合线(拟合为线段和圆弧)。直到在某个结点,聚合线与边连成一条直线,此后出现一条新的聚合线。圆弧和形似圆弧的线也类似。各种图像的特征(圆弧和线段)组合起来,用于确定某一物体的特征。
相较于 PCA(主成分分析法)和 HOG(定向梯度直方图),支持向量机(Support Vector Machines)是高级驾驶辅助系统(ADAS)中常用的识别算法。与此同时,K 近邻(KNN)和贝叶斯决策法则也同样经常用到。
支持向量机(SVM)
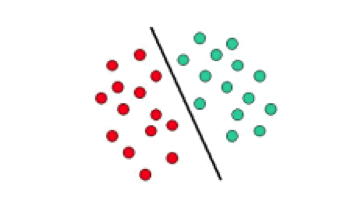
支持向量机(SVM)主要在于如何定义决策边界或分离超平面。SVM 的超平面会在保留最大间隔的情况下把不同类别的数据分隔开。在如下示意图中,数据分属红绿两类。一个超平面将红绿数据分开。任何落在左侧的新对象都将标记为红色,落在右侧的都将标记为绿色。
回归算法
该算法非常适用于对事件的预测。回归分析对两个或者两个以上变量之间的关系进行评估,并核对出变量在不同程度上产生的影响。通常有以下三种指标:
图像信号(摄像机或雷达)的启动和定位在高级辅助驾驶系统中起着重要的作用。对于任何算法而言,最大的挑战在于开发基于图像特征选择及预测的模型。
给定物体在图像中的位置与该图像,回归算法可以利用环境的重复性创建出一个关系统计模型。该模型允许图像采样,并提供快速在线检测和离线学习模式。它还可以进一步扩展到其他物体而无需大量人工建模。作为在线实时输出以及对物体存在的反馈,算法将自动返回该物体的位置。
回归算法亦可用于短期预测和长期学习。可以用于自动驾驶的回归算法包括决策森林回归,神经网络回归和贝叶斯回归等。
神经网络回归
神经网络可以用于回归、分类或者非监督式学习。这类算法可以基于无监督将未经标注的数据进行分类,或者在监督训练之后用来预测后续的数值。神经网络通常使用 logistic 回归作为网络的最后一层将连续性的据转换成 1 或 0 这样的离散型变量。
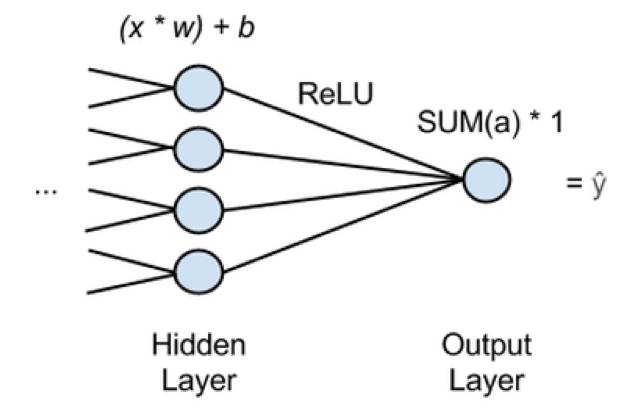
上图中可以看到,『x』 是输入数据,特征从网络结构的输入层开始传递。在向后传递没经过一条边时,每一个特征值『x』会被乘以一个相应的权重『w』。所有乘积之和将通过一个激活函数 ReLU 使结果可用于非线性分类。ReLU 十分常用,它不像 sigmoid 函数那样在浅层梯度情况下易趋于饱和(当输入非常大或者非常小的时候,神经元的梯度是接近于 0 的。如果这样,大部分神经元可能都会处在饱和状态而令梯度消失,这会导致网络变的很难学习)。ReLU 为每个隐藏神经元提供一个激活输出并传递到下一个输出神经元中。这意味着执行回归的神经网络包含单个输出节点,且该节点将先前层的激活数值总和乘以 1。图中的神经网络预测『y_hat』便是结果。『y_hat』是所有 x 映射的因变量。我们以这种方式使用神经网络,从而通过与 y(单个因变量)相关的 x(多个自变量)而预测连续值结果。
原文地址:http://www.kdnuggets.com/2017/06/machine-learning-algorithms-used-self-driving-cars.html
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]
点击阅读原文,查看机器之心官网↓↓↓










