
科研经验
|
文献
|
实验
|
工具
|
SCI写作
|
国自然

作者:叶子(转载请注:解螺旋·医生科研助手)
这次文献精读课给大家带来的是一篇跟生物统计相关的文章,会涉及到一些比较基础的生物统计分析概念。这篇paper是今年年初发表在Nature Genetics上的,主要讲的是一种新的模型来改进传统的病例对照分析的方法。本文不仅实用性强,而且另辟蹊径。
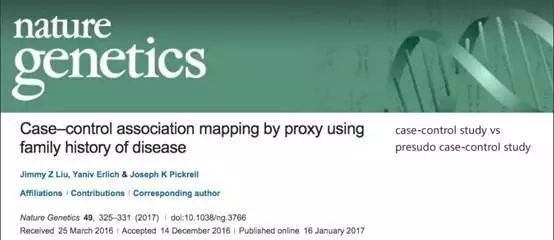
先说下传统的疾病对照研究
,是用来推测基因位点与疾病间有无关联及关联强度大小的一种分析方法,如果有关联还要表示出关联强度大小。具体怎么做呢,首先是采集样本,之后按照所研究的疾病把样本分为2组。
病例组:患所研究疾病的人群
对照组:未患有所研究疾病的人群
那这篇文章里的研究条件是什么呢?就是单核苷酸多态性(SNP),一般用来表示等位基因上的突变。比如有一对原始的基因型是AA,如果发生突变了就会变成AT或者TT。在人群中,针对这一个单核苷酸基因位点就有3种基因型,AA、AT和TT。
然后再说下一个概念,MAF:minor allele fréquence,其实就是最不常见的那个等位基因的发生频率,继续拿刚才的例子,在一群人中假设只有10个人有A,但有1000个有T,那MAF就是10/1000。
分组之后,疾病组和对照组都有个A/T的比率,通过卡方检验看下这个基因比率是不是有统计学差异。如有,那就说明这个基因位点是与疾病有关联的,还能通过比率来计算关联的强度,也就是OR值。
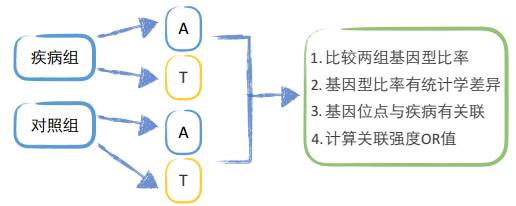
根据上面这个二联表就可以通过卡方检验公式,算出卡方值。公式是:

代进去就行了,拿到卡方值后,根据卡方分布就能求到P值。求出P值后我们还要继续算一个OR值,它的公式更简单 (a/c)/(b/d)。
它是个风险因素值,当OR=1,说明这个SNP与疾病没有相关性;当OR1时,SNP与疾病呈正相关,位点的基因突变会导致疾病的发生。
这一套就是传统的病例对照分析研究流程。
了解了传统流程后,来看看这篇文章又有什么创新点呢?那就是作者发明了一种新的病例对照方法可以弥补传统方法的不足。传统方法有哪些不足之处呢?
对于低发病率疾病、过早致死疾病、低存在率疾病这3类疾病的样本并不容易采集,使得分析结果有一定的偏差。这也很好理解,低发病率疾病,10000个人里只有1个病人,就算有20000个样本,也只有2个疾病组。过早死的呢,小孩3岁就死了,那也是没办法采集样本的。还有低存在率疾病是什么呢?比如说,有个疾病在非洲爆发了,但在亚洲并没有这种疾病,如果你要在亚洲进行样本采集,那就是无效样本。
本文新方法的概念很简单,在疾病组里不仅仅有患病的人,还加入了患病人的一级亲属,也当做case来研究。通过这种方法大大增加了疾病组的数量,使很多传统分析方法无效的疾病就可以用新方法来分析。
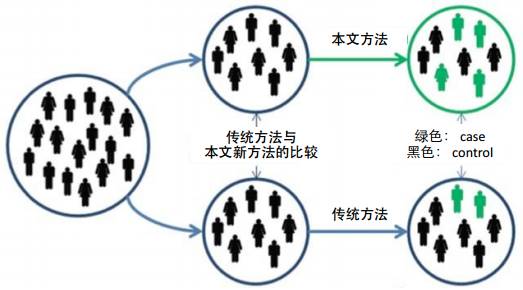
那这个OR值要怎么算呢?
它用了一个均值的算法,这里
f
P
为包含一级亲属的疾病组基因型频率;
f
A
与
f
U
分别是疾病组与对照组的基因型频率。
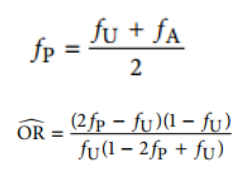
文章只有4个Figure,看看全文大概的思路。
-
Fig1里计算了两种方法在样本量需求与power值方面的比较;
-
Fig2里对所有病例做了样本量的统计;
-
Fig3里对于致病基因位点分别采用两种方法计算了OR值并作比较,发现两种方法的相关性很强;
-
Fig4将新方法运用在不同疾病中发现了已经报导的信号更发现了一些新信号。

Fig1将两种方法在样本量与power值方面进行了比较。先看b图,有3条曲线,分别代表什么呢?黑色的那条是传统的做法,只把患病人作为疾病组;红色曲线不仅把患病的人,还将他们的家属也作为疾病组;而蓝线则将,病人、病人亲属和没有患病的人分别分析。
Fig1b告诉我们,当OR值相同的时候,用新的方法,会有更大的P值。
同样的,Fig1a表示,当OR值相同的时候,用新的方法,要更大的样本量。
新模型的特征也就出来了,对样本量有更高的要求,所得结果有更高的P值。这么看来,这个新模型也没什么好嘛,需要更多样本,就要花多的时间去采集。那这有什么意义,不用担心,作者在Fig2里证明了,这种不利条件并不用过分担心。
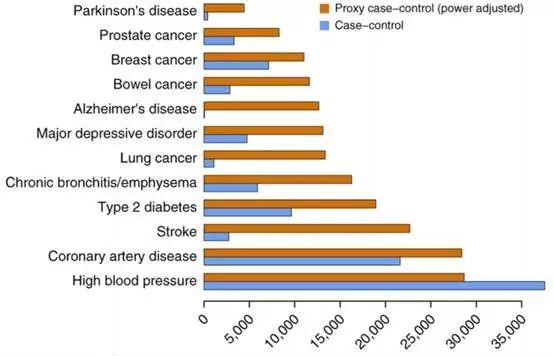
Fig2给出了各种疾病的样本量,红色的包含了一级亲属;蓝色的不包含一级亲属。可以看到尽管新模型需要4倍的样本量;但是现实病例可以满足这种方法的基本要求(父母、兄弟姐妹、子女)。所以,样本量的弊端不用过多的考虑。
然后作者想比较新旧两种方法得出的OR值是不是相关联,这就有了Fig3。
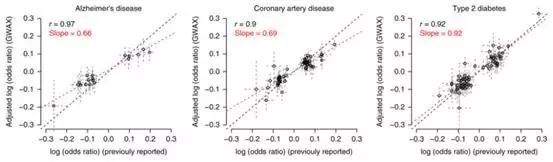
作者把收录的16种疾病都用新旧两种方法做了下,这里举其中3个例子。对于II型糖尿病来说,每个黑点都是以前研究找到的致病位点,把每个位点计算了OR值后,传统方法的值做X轴,新方法的值做Y轴。Log后做了个线性回归,Slope高达0.92,也就是说,新方法的OR值是比较高,但并非虚高。
同样在阿兹海默病和冠状动脉病里Slope也有0.7左右,并且作者发现,对于发病率较高的疾病,两种方法的OR值相关性更强。
最后看下Fig4,这是个曼哈顿图,X轴代表SNP在基因组上的物理位置,1就代表1号染色体,一个一个排下去。Y轴代表的是SNP和疾病的关联程度,虚线以上说明该SNP和疾病强相关。
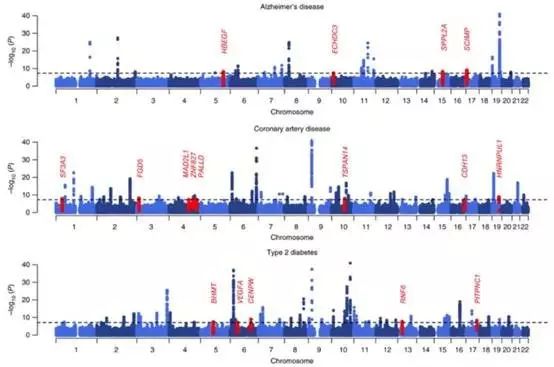
作者把以前所有研究结果做了个合并分析,所以看着相关突变特别多,蓝色点就是前人用传统方法找到的点,而红点则是作者用新方法找到的位点。说明对于那些传统方法不太适合的疾病来说,新方法有着更敏感的检测效果。
这也是新方法的优势所在。
本文一个很好的思路就在于,如果我研究的是罕见病,用传统方法收集病例就是个坑。而新方法与众不同的用了一级亲属替代,人为的加大疾病组的样本量,来做病例对照分析。
但这篇paper也有所不足,主要在于
f
P
值单纯的用了
f
A
和
f
U
的平均数,过于简单粗暴,可能并不是一个很好、很精细的模型,相信今后会对其有所改善。
长按识别下方二维码添加文献菌为好友,直接提问和深入交流。







