
人工智能是当今的热议行业,深度学习是热门中的热门,浪尖上的浪潮,但对传统IT从业人员来说,人工智能技术到处都是模型、算法、矢量向量,太晦涩难懂了。所以我写了这篇入门级科普文章,目标是让IT从业者能看清读懂深度学习技术的特点,以及我们如何从中受益,找到自己的工作。
行业的成熟要靠从业者的奋斗(人和),也要考虑大环境和历史的进程(天时和地利)。
人工智能技术的井喷并不是单纯的技术进步,而是软件、硬件、数据三方面共同努力水到渠成的结果,深度学习是AI技术的最热分支,也是受这三方面条件的限制。
AI软件所依赖的算法已经存在很多年了,神经网络是50年前提出的技术,CNN/RNN等算法比大部分读者的年龄都要大。AI技术一直被束之高阁,是因为缺乏硬件算力和海量数据。随着CPU、GPU、FPGA硬件的更新,几十年时间硬件算力扩充了万倍,硬件算力被逐渐解放。随着硬盘和带宽的降价提速,20年前全人类都没几张高清照片,现在单个公司的数据量就能达到EB级。大数据技术只能读写结构化日志,要读视频和图片必须用AI,人类已经盯不过来这么多摄像头了。
我们只有从心里把AI技术请下神坛,才能把它当做顺手的工具去用。AI的技术很深理论很晦涩,主要是这个行业刚刚发芽还未分层,就像20年前IT工程师需要全面掌握技能,现在的小朋友们连字符集都不用关注。
深度学习有两步工作,先要训练生成模型,然后使用模型去推测当前的任务。
比如说我用100万张图片标记好这是猫还是狗,AI把图片内各个片段的特征提取出来,生成一个猫狗识别模型。然后我们再给这个模型套上接口做成猫狗检测程序,每给这个程序一张照片它就能告诉你有多大几率是猫多大几率是狗。
这个识别模型是整个程序中最关键的部分,可以模糊的认为它就是一个密封黑盒的识别函数。以前我们写程序都是做if-then-else因果判断,但图像特征没有因果关系只看关联度,过去的工作经验反而成了新的认知障碍,还不如就将其当做黑盒直接拿来用。
接下来我放一个模型训练和推测的实验步骤截图,向大家说明两个问题:
1.需要用客户的现场数据做训练才能出模型,训练模型不是软件外包堆人日就行,很难直接承诺模型训练结果。
2.训练模型的过程很繁琐耗时,但并不难以掌握,其工作压力比DBA在线调试SQL小多了,IT工程师在AI时代仍有用伍之地。
本节较长,如果读者对实验步骤和结果没兴趣,而是直接想看我的结论,也可以跳过这一节。
这个实验是Nvidia提供的入门培训课程——ImageClassification with DIGITS - Training a model。
我们的实验很简单,用6000张图片去训练AI识别0-9这几个数字。
训练样本数据是6000张标号0-9的小图片,其中4500张是用来做训练(train),1500张是验证(val)训练结果。
####实验数据准备 ####
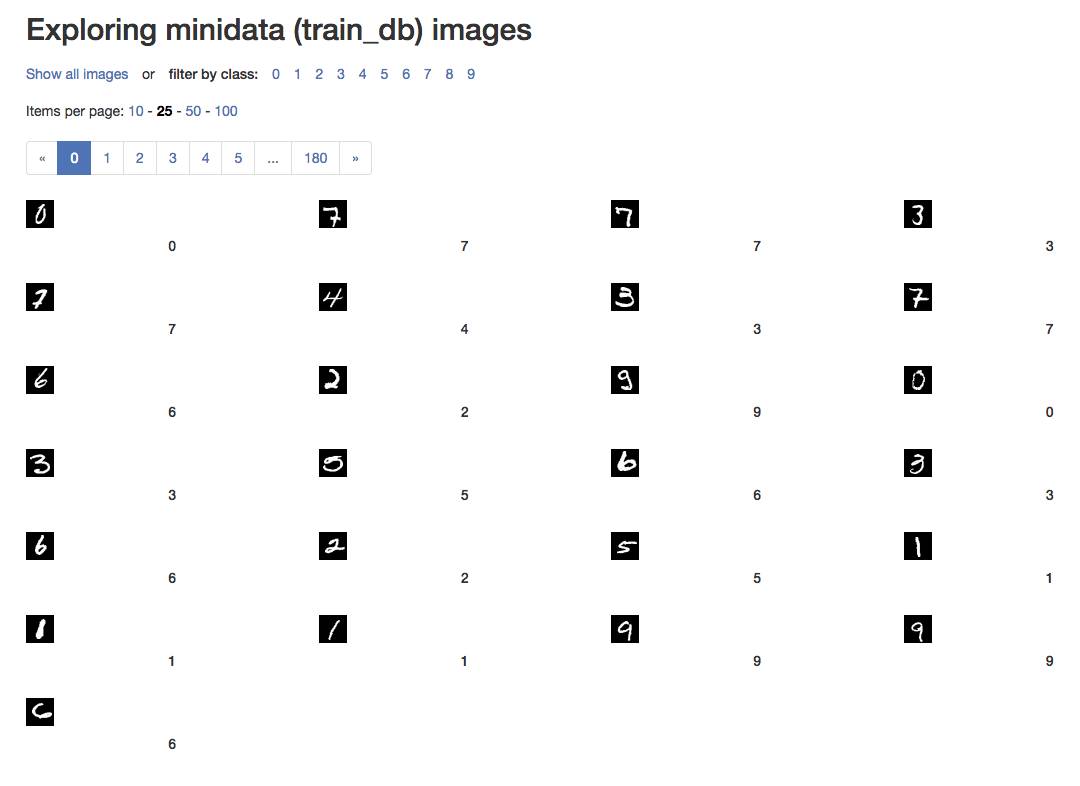
1.训练图片很小也很简单,如下图预览,就是一堆数字:
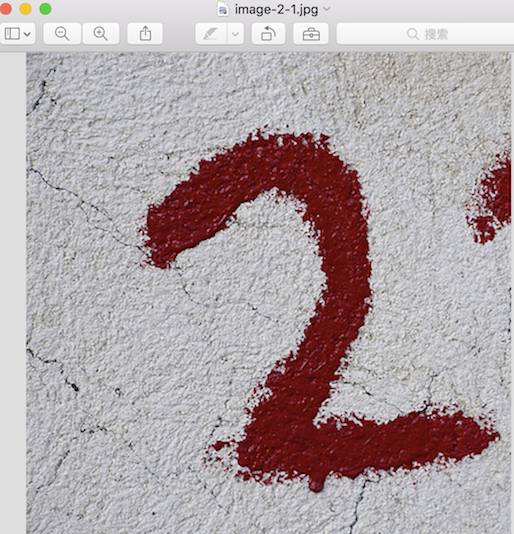
2.我做测试的图片是官方教程提供了个白底红字的“2”.
####制作数据集 ####
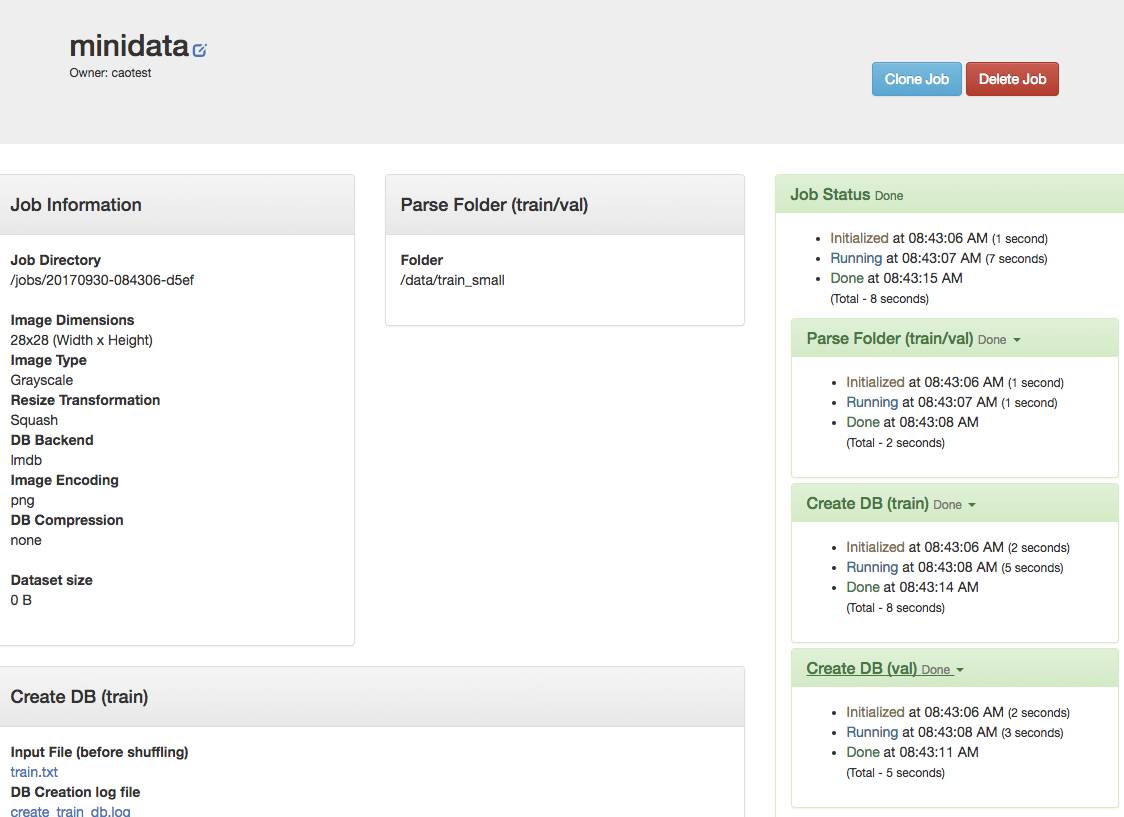
3.首先我们要做一个图片识别的数据集,数据集文件放在“/data/train_small”目录下,图片的类型选择“Grayscale”,大小选28x28,其他都选默认,然后选择创建数据集“minidata”。
4.下面是数据集创建的过程,因为我们的文件很小很少,所以速度很快;如果是几千万张高清大图
速度就会很慢,甚至要搭建分布式系统把IO分散到多台机器上。
5.这是创建完成数据集的柱形统计图,鼠标恰好停在第二个柱形上,显示当前标记为“9”的图片有466个。
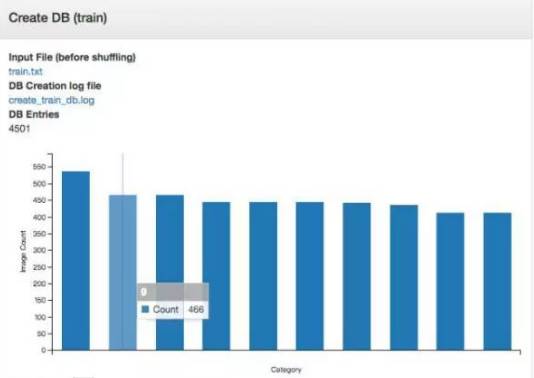

####开始创建模型 ####
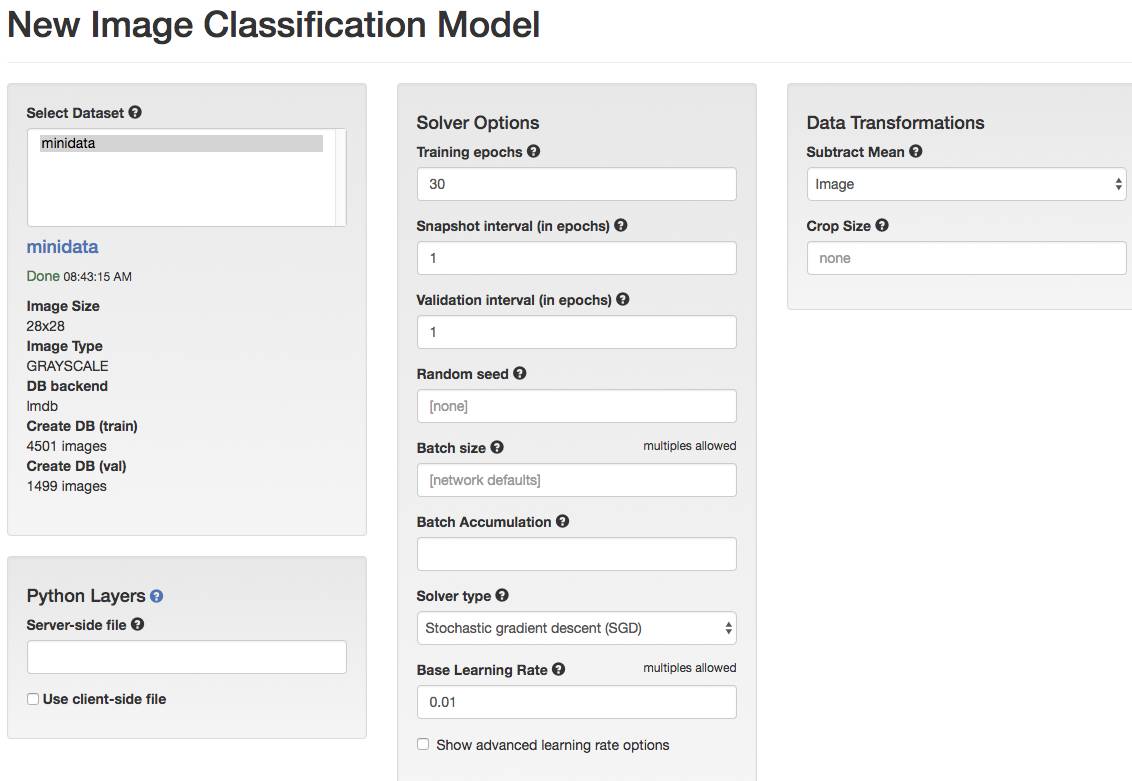
6.有了数据集以后我们就可以创建模型了,我们选择创建一个图像分类模型(Image Classification Model),数据集选之前创建的“minidata”,训练圈数输30次,其他选项暂时保持默认。
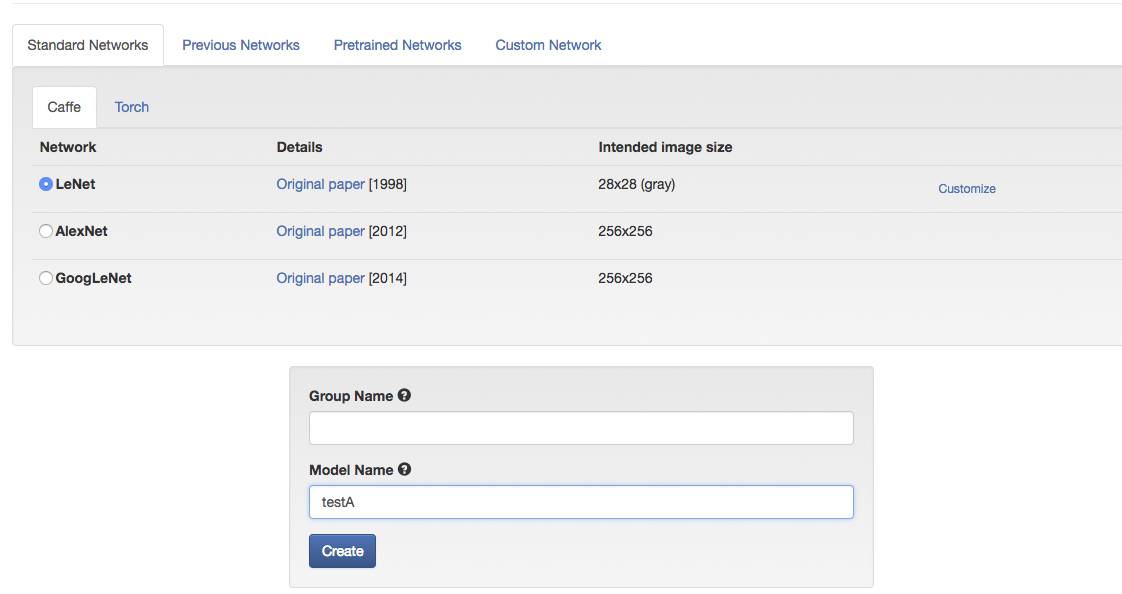
7.到了创建模型的下半段是选择网络构型,我们选择LeNet即可,将模型命名为TestA。
8.这次Demo我们没做细节设置,但生产环境可能要经常修改配置文件。
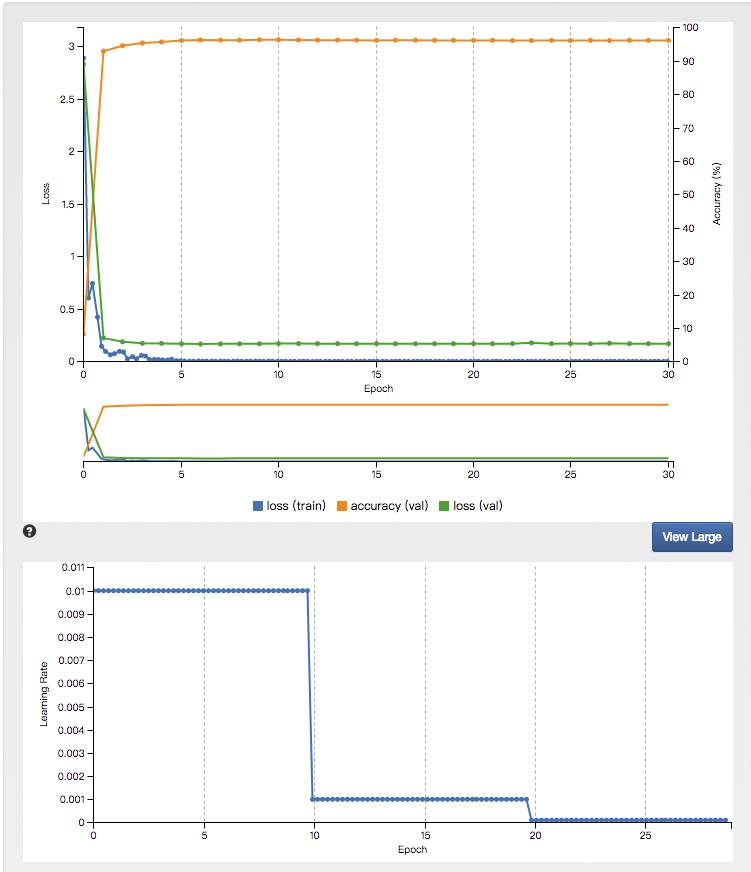
9.接下来就开始生成模型了,小数据集简单任务的速度还是很快的,而且验证正确率很高。但是如果是大任务大模型,可能会算上几天时间。
10.模型生成完成,我们再看一下验证正确率很高了,如果生产环境正确率太低,可能你要微调创建模型的参数。
####调试模型 ####
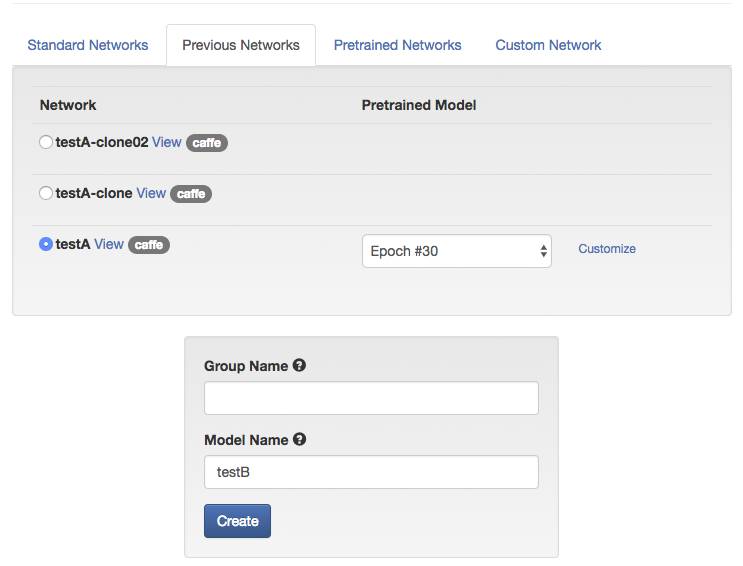
11.在模型页面往下拖就可以看到下载模型、测试模型等按钮,我们选择测试模型,将那个“白底红字2”提交做个测试。
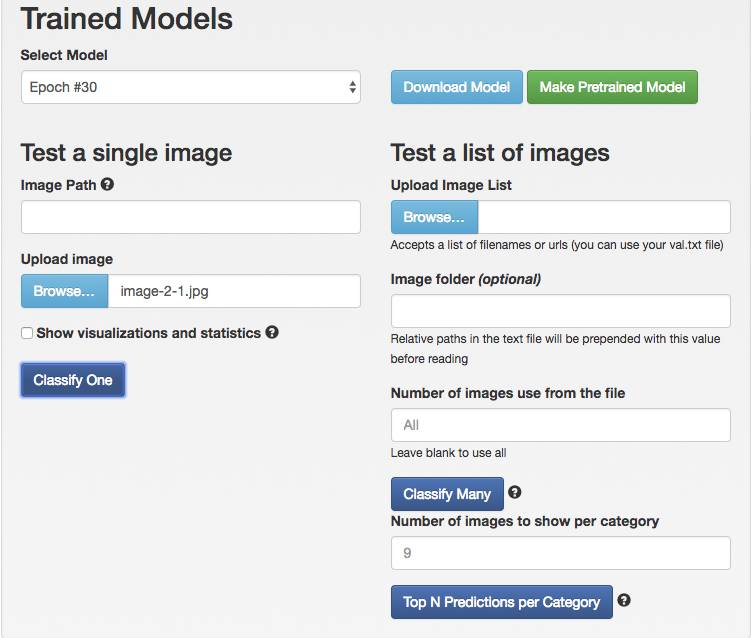
12.默认是测试Epoch #30,我们先跑10次试试。本来想省点服务器电费,结果只有20.3%的几率识别正确。
13.我们提高测试圈数到25圈,结果准确率从20.3%提高到了21.9%。





