(点击上方公众号,可快速关注)
来源:伯乐在线专栏作者 - Janzou
欢迎投稿,请点击这里查看详情;
如需转载,发送「转载」二字查看说明
本文面向的是那些刚刚接触编程,可能已经听说过”面向对象编程”,”OOP”,”类”,”继承/封装/多态”,以及其他计算机科学术语的,但是仍然没有真正明白如何使用OOP的朋友。在本文中,我将解释为什么使用OOP和如何轻松编码。这篇文章使用Python 3代码,但其概念适用于任何编程语言。
有两个关键的非面向对象编程概念需要马上理解:
重复的代码是一件坏事。
代码永远都在改变。
除了一些单任务和只运行一次的微小的”用完即弃”的程序,你几乎总是需要为了解决bug或增加新功能而更新你的代码。大部分编写良好的软件是那种可读性高,易于修改的软件。
如果你经常在你的程序中复制/黏贴代码,那么当你修改它的时候,就需要在很多地方做出同样的改动。这是棘手的。如果在某些地方遗漏了修改,你将到处修改bug或者实现的新功能有不一致性。重复的代码是一件坏事。程序中重复的代码将会把你置于bug和头痛之中。
函数让你摆脱重复的代码。你只需要将代码写到函数中一次,就可以在程序中的任何需要运行代码的地方调用它就可以。更新函数的代码就可以自动更新调用函数的地方。正如函数使得更新代码变得容易,使用面向对象编程技术也会组织你的代码使它更容易改变。记住代码总是在改变的。
一个角色扮演游戏栗子
大多数OOP教程都是令人作恶的。它们有”汽车”类和”鸣笛”方法,其他一些例子与新手写的或者之前接触过的实际程序都是不相关的。因此本博文将使用一个RPG类视频游戏(回忆下魔兽,宠物小精灵,或龙与地下城的世界)。我们已经习惯于将游戏中的事物想象成一些整数与字符的集合。看看Diablo(暗黑破坏神)角色屏幕或D&D角色表单上的数字:
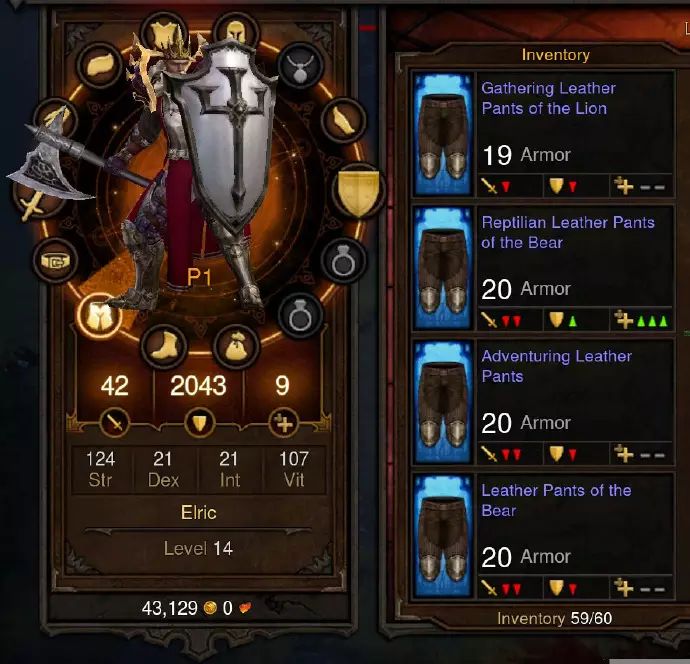

从这些RPG视频游戏中去除图片,角色,装甲,其他对象只是变量形式的一个整数或者字符值的集合。不使用面向对象概念,你可以在Python中这样实现这些事物:
name = 'Elsa'
health = 50
magicPoints = 80
inventory = {'gold': 40, 'healing potion': 2, 'key': 1}
print('The hero %s has %s health.' % (name, health))
以上变量名都是非常通用的。为了在游戏中增加怪兽,你需要重命名玩家角色变量,并且增加一个怪兽角色:
heroName = 'Elsa'
heroHealth = 50
heroMagicPoints = 80
heroInventory = {'gold': 40, 'healing potion': 2, 'key': 1}
monsterName = 'Goblin'
monsterHealth = 20
monsterMagicPoints = 0
monsterInventory = {'gold': 12, 'dagger': 1}
print('The hero %s has %s health.' % (heroName, heroHealth))
当然你希望有更多的怪物,接着你会有类似monster1Name, monster2Name等等的变量。这不是一种好的编码方法,因此你可能会使用怪物变量列表:
monsterName = ['Goblin', 'Dragon', 'Goblin']
monsterHealth = [20, 300, 18]
monsterMagicPoints = [0, 200, 0]
monsterInventory = [{'gold': 12, 'dagger': 1}, {'gold': 890, 'magic amulet': 1}, {'gold': 15, 'dagger': 1}]
然后列表索引0处是第一个哥布林的状态,龙的状态在索引1处,另一个哥布林在索引2处。这样你可以在这些变量中存放很多怪物。
但是,这种代码容易导致错误。如果你的列表不同步,程序将无法正常工作。例如玩家击败了索引0处的哥布林,程序调用了vanquishMonster()函数。但这个函数有一个bug,它会(意外的)删除列表中的所有值除了monsterInventory:
def vanquishMonster(monsterIndex):
del monsterName[monsterIndex]
del monsterHealth[monsterIndex]
del monsterMagicPoints[monsterIndex]
# Note there is no del for monsterInventory
vanquishMonster(0)
怪兽列表最后看起来像这样:
monsterName = ['Dragon', 'Goblin']
monsterHealth = [300, 18]
monsterMagicPoints = [200, 0]
monsterInventory = [{'gold': 12, 'dagger': 1}, {'gold': 890, 'magic amulet': 1}, {'gold': 15, 'dagger': 1}
现在龙的道具看起来跟之前哥布林的道具一样。第二个哥布林的道具是之前龙的道具。游戏迅速失控了。问题是你把一个怪物的数据散布在多个变量中。解决这个问题的方法是将一个怪物的数据放入一个字典里,然后使用一个字典列表:
monsters = [{'name': 'Goblin', 'health': 20, 'magic points': 0, 'inventory': {'gold': 12, 'dagger': 1}},
{'name': 'Dragon', 'health': 300, 'magic points': 200, 'inventory': {'gold': 890, 'magic amulet': 1}},
{'name': 'Goblin', 'health': 18, 'magic points': 0, 'inventory': {'gold': 15, 'dagger': 1}}]
啊哈!这段代码变得更加复杂了。例如,一个怪兽的状态是一个字典列表中的字典项。假如咒语或者道具栏也有它们自己的属性,且需要放到字典该怎么办?假如一个道具栏中的物品是一个背包,它本身包含了其他道具该怎么办?这个怪物列表会变得紧张。
这点是面向对象程序设计通过创建一个新的数据类型就可以解决的。
创建类
类是你程序中新数据类型的蓝图。面向对象编程对装甲,怪物等建模提供了新的方法,该方法比列表和字典的大杂烩好得多。虽然需要花些时间来熟悉OOP的概念。
事实上,因为英雄角色与怪兽们拥有相同的属性(健康值,状态值等等),我们只需要一个英雄与怪兽共享的通用的LivingThing类。你的代码可以变为:
class LivingThing():
def __init__(self, name, health, magicPoints, inventory):
self.name = name
self.health = health
self.magicPoints = magicPoints
self.inventory = inventory
# Create the LivingThing object for the hero.
hero = LivingThing('Elsa', 50, 80, {})
monsters = []
monsters.append(LivingThing('Goblin', 20, 0, {'gold': 12, 'dagger': 1}))
monsters.append(LivingThing('Dragon', 300, 200, {'gold': 890, 'magic amulet': 1}))
print('The hero %s has %s health.' % (hero.name, hero.health))
嘿,瞧瞧,使用类已经把我们的代码削减了一半,因为我们可以对玩家角色和怪兽使用同样的代码。
在上面的代码中,你可以定义新的数据类型/类(除了学院派,但是这两个术语基本上是一样的。参见Stack Overflow – What’s the difference between a type and a class?)名为LivingThing。你可以实例化LivingThing变量/对象(重复一次,这两个术语基本上也是相同的)就好像你可以拥有整形值,字符值或布尔值一样。
上面代码特定于Python的细节:
class LivingThing():
上面class声明定义了一个新类,就像def声明定义一个新函数。该类名是LivingThing。
def __init__(self, name, health, magicPoints, inventory):
上面代码为LivingThing类定义了一个方法。”方法“只是命名属于这个类的函数。(参考Stack Overflow – What is the difference between a method and a function?)
这个方法很特别。__init__()用于类的构造函数(或者称为”构造方法”,”构造函数”,简写为”ctor”)。而一个类是一个新数据类型的蓝图,你还需要创建这个数据类型的值,以便于存储到变量或者使用函数传递。
当调用构造器创建新对象时,执行构造器中的代码,并返回一个新对象。这就是
hero = LivingThing('Elsa', 50, 80, {})
这行的意思。无论类名是什么,构造器总是被命名为__init__。
如果类没有__init__()方法,Python会为类提供通用的构造方法,该方法什么都不做。但是__init__()是初始化建立一个新对象的绝佳地方。
在Python语言中,方法中的第一个变量是self。self变量用于创建成员变量,后面会做解释。
构造函数体:
self.name = name
self.health = health
self.magicPoints = magicPoints
self.inventory = inventory
这看上去有点重复,但这段代码所作的就是对由构造函数创建的对象的成员变量赋值。成员变量开头是self.表示这些成员变量属于创建的对象,且不是函数中的普通局部变量。
调用构造器
# Create the LivingThing object for the hero.
hero = LivingThing('Elsa', 50, 80, {})
monsters = [LivingThing('Goblin', 20, 0, {'gold': 12, 'dagger': 1}),
LivingThing('Dragon', 300, 200, {'gold': 890, 'magic amulet': 1}),
LivingThing('Goblin', 18, 0, {'gold': 15, 'dagger': 1})]
print('The hero %s has %s health.' % (hero.name, hero.health))
Python中调用构造器就像是一个函数调用,该函数名为类名。因此LivingThing()就是调用LivingThing类的__init__()构造器。
LivingThing('Elsa', 50, 80, {})
调用创建了一个新的LivingThing对象,并保存在到hero变量里。以上代码还创建了3个怪兽LivingThing对象并保存在monsters列表中。
至此我们开始看到了面向对象编程的好处。如果其他程序员读了你的代码,当他们看到LivingThing()调用,他们知道他们可以搜索LivingThing类,然后从LivingThing类中找出所有他们想知道的细节。
但一个更大的好处是当你试图更新LivingThing类时才能体会的。
更新类
假如你想给你的RPG增加”饥饿”度属性。如果一个英雄或怪兽的饥饿度为0,他们一点也不饿。但如果他们的饥饿度超过100,那么他们将受到伤害并且健康值每天递减。你可以这样改变__init__()函数:
def __init__(self, name, health, magicPoints, inventory):
self.name = name
self.health = health
self.magicPoints = magicPoints
self.inventory = inventory
self.hunger = 0 # all living things start with hunger level 0
不需要修改其他任何代码行,你游戏中所有LivingThing对象现在都有了饥饿度。你不需要担心某些LivingThing对象有hunger成员变量,而有些没有:所有LivingThing对象都更新了。
你也不需要改变任何构造器调用,因为你没有在__init__()函数的参数列表总中增加一个新的饥饿度参数。这是因为队一个新的LivingThing对象的饥饿度来说0是一个很好的默认值。如果你在__init__()函数的参数列表总中增加一个新的饥饿度参数,那么你需要更新所有调用构造器的代码。但这对其他函数也是一样的。
如果你的RPG有很多类似的默认值,通过使用类的构造器进行默认值赋值,就可以避免当量的”样板”代码。
方法
方法具有执行代码来影响对象本身的用途。例如,你可以编码来直接修改LivingThing对象的健康度:
hero = LivingThing('Elsa', 50, {})
hero.health -= 10 # Elsa takes 10 points of damage
但这样处理伤害不是一个非常健壮的方式。每当有什么东西受到伤害时就需要检查很多其他的游戏逻辑。例如,假设你想要检查一个角色在受到伤害后,它是否死亡。你需要这样的代码:
hero = LivingThing('Elsa', 50, {})
hero.health -= 10 # Elsa takes 10 points of damage
if hero.health 0:
print(hero.name + ' has died!')
以上方法的问题是你需要检查各处代码来减少LivingThing对象的健康值。但是重复的代码是一件坏事。阻止重复的代码的非OOP方式可能是把以上方法放入一个函数中:
def takeDamage(livingThingObject, dmgAmount):
livingThingObject.health = self.health - dmgAmount
if livingThingObject.health 0:
print(livingThingObject.name + ' is dead!')
hero = LivingThing('Elsa', 50, {})
takeDamage(hero, 10) # Elsa takes 10 points of damage
这是一个更好的解决方案,因为任何更新takeDamage()(例如装甲防护,保护性法术,增益效果等)只需要增加到takeDamage()函数中。
然而,不利的一面是,当您的程序规模增长,takeDamage()函数很容易迷失在其中。takeDamage()函数与LivingThing类的关系并不明显。如果你的程序有成百上千的函数,它将很难指出哪一个函数与LivingThing类有关系。
解决的方法是将这个函数变成LivingThing类的方法:
class LivingThing():
# ...other code in the class...
def takeDamage(self, dmgAmount):
self.health = self.health - dmgAmount
if self.health == 0:
print(self.name + ' is dead!')
# ...other code in the class...
hero = LivingThing('Elsa', 50, {})
hero.takeDamage(10) # Elsa takes 10 points of damage
一旦你的程序有很多类,每个类有许多方法和成员变量,你将开始看到OOP可以帮助组织你的程序而使他更易于管理。
公共与私有方法
方法与成员变量可以被标示为public或private。公共方法可以和公共成员变量可以在类内部或外部的任何代码调用和赋值。私有方法和私有成员变量只能在对象自己的类内部被调用和赋值。
在某些语言中,例如Java,这种”可以被调用/赋值”由编译器严格的保证。而Python,却没有”私有”和”公共”的概念。所有方法和成员变量都是”公共”的。然而,语言规定如果一个方法名开头是下划线,它就被认为是一个私有方法。这就是为什么你将看到_takeDamage()等方法了。你可以方便的编写代码从对象的类的外部调用私有函数或者设置私有成员变量,但你已经被彻底警告不要去这样做了。
公共/私有的区别的原因是为了解释类如何与外部代码进行交互的。(参考Stack Overflow – Why “private” methods in the object oriented?)类的程序员期望其他人不会编写代码调用私有方法或设置私有成员变量。
例如,takeDamage()方法包括健康值低于0就检查死亡。你可能想要在代码中添加各种各样的其他检查。护甲、敏捷性和防护法术来减少伤害的可能因素。LivingThing对象可能穿着一件魔法斗篷,通过增加抗损害值,而不是减少它们的健康值来进行治疗。这个游戏的所有逻辑都可以放入takeDamage()方法中。
如果你偶然的把代码放到那里,所有的OOP结构就毫无意义了
class LivingThing():
# ...code in the class...
hero = LivingThing('Elsa', 50, {})
# ...some more code...
if someCondition:
hero.health -= 50
语句hero.health -= 50会减少50点健康值,而不会考虑Elsa穿着哪种装甲,或者她有防护法术,或者她穿着魔法治疗披风。这段代码将直截了当的减少50点健康值。
很容易忘掉takeDamage()方法并且偶尔写出这样的代码。它不会检查英雄对象的健康值是否低于0。游戏继续运行好像Elsa还活着,及时她的健康值是负数!我们可以使用公共/私有成员和方法来避免这个bug。
如果你重命名health成员变量为_health且标记为私有的,那么当你写成这样就很容易捕获这个bug:
hero = LivingThing('Elsa', 50, {})
# ...some more code...
if someCondition:
hero._health -= 50 # WAIT! This code is outside the hero object's class but modifying a private member variable! This must be a bug!
在一种语言中如Java,如果编译器确保私有/公共访问,它就不可能编写非法访问自由成员和方法的程序。面向对象编程帮助我们防止这种bug。
继承
使用LivingThing类表示龙是不错的,但是除了LivingThing类提供的属性外,龙有很多其他的属性。因此你想创建一个新的Dragon类,它包含如airSpeed和breathType(可以使用 'fire','blizzard', 'lightning', 'poison gas'等字符串表示)等成员变量。
因为Dragon对象也包含health,magicPoints,inventory和其他LivingThing对象的属性,你可以创建一个新的Dragon类,并且从LivingThing类复制/黏贴所有代码。但这将导致重复的代码这一坏习惯。
相反,可以使Dragon类作为LivingThing类的子类:
class LivingThing():
# ...other code in the class...
class Dragon(LivingThing):
# ...Dragon-specific code in the class...
实际上是说,”一个龙也是一种LivingThing,还有一些附加的方法和成员变量”。当你创建龙对象时,它会自动的拥有LivingThing的方法和成员变量(拯救我们脱离重复的代码)。但它也有龙特有的方法和成员变量。进一步说,任何处理LivingThing对象的代码都可以自动的操作龙对象,因为龙对象已经拥有了LivingThing成员变量和方法。这个原则被称为子类型多态性。
然而在实践中,继承是容易滥用的。你必须确保任何对LivingThing类做出的改变和更新都适用于Dragon类和所有其他LivingThing的子类。这可能不总是那么简单直接。
例如,如果你创建了LivingThing类的Monster和Hero子类,接着创建了Monster类的 FlyingMonster 和MagicalMonster子类,新的Dragon类继承自FlyingMonster 类还是MagicalMonster类?或者可能它只是Monster类的子类
这就是继承和OOP开始变得棘手且严谨的争论哪种是”正确”设计类的方式之所在。我希望报纸这篇博文简短而简单,因此我要把这些问题留给读者作为练习来调查。(参考 Stack Overflow – Prefer composition over inheritance? 和Wikipedia – Composition over inheritance)
总结
我讨厌由面向对象编程开始的面向初学者的程序教程。OOP是十分抽象的概念。有一些经验和编写过大型程序之前,你不会理解为什么使用类和对象使编程更容易。相反,它会给初学者留下一条陡峭的学习曲线去爬,他们不知道为什么攀登它。我希望这个RPG例子至少让你领略了为什么OOP是有帮助的。有更多的OOP。如果你想了解更多,试试搜索“python object oriented design” 和 “python design patterns”。
如果你仍然对OOP概念感到迷惑,放心大胆的编写没有类的程序。你不需要它们,它们将导致过度设计的代码。但是一旦你已经有了一些编码经验,面向对象编程的好处会变得更加明显。祝你好运!
觉得本文对你有帮助?请分享给更多人
关注「Python开发者」
看更多技术干货











