来源:J.P.Morgan
编译:张易 弗格森
【新智元导读】
近日,
微软 AI 首席科学家邓力加盟对冲基金公司 Citadel 再次引发了人们对于机器学习技术应用于金融投资领域的关注。J.P.摩根最新的280 页研究报告《大数据和 AI 策略——面向投资的机器学习和另类数据方法》,极为详尽地梳理、评述、预测了对冲基金和投资者使用机器学习技术利用、分析另类数据的现状与未来,对于一切关注这一新兴大趋势的人们、一切投资者都有重要的借鉴意义。我们节选介绍了这一长篇报告,并提供了报告的下载。
在新智元微信公众号回复
“
JP摩根
”
下载报告全文。

大数据,特别是另类数据集的构建和利用,已经极大地改变了投资领域的面貌。
对冲基金和其他经验丰富的投资者日益增加了对“另类数据”(alternative data)的消费。只要可能影响投资决策但又不属于市场统计数据和公司财报这类传统信息的数据都称为“另类数据”。
不过,如果没有内行的数据科学家,这类数据就难以使用,而且有时候并不可靠。对冲基金只是在最近才能获得卫星图像分析之类的数据,所以没有多少历史数据用来核实其价值。部分批评者认为,如此复杂的公司和经济分析方法的好处被夸大了。
就在前不久,微软AI首席科学家、IEEE Fellow 邓力离开微软,加盟对冲基金公司 Citadel,担任首席人工智能官(Chief Artificial-Intelligence Officer)。这条消息再次引发了人们对于 AI 技术、尤其是机器学习技术在金融投资领域应用的关注。
J.P.摩根最新的280 页研究报告《大数据和 AI 策略——面向投资的机器学习和另类数据方法》,极为详尽地梳理、评述、预测了对冲基金和投资者使用机器学习技术利用、分析另类数据的现状与未来,对于一切关注这一新兴大趋势的人们、一切投资者都有重要的借鉴意义。我们节选了这一长篇报告非常小的一部分介绍给读者朋友们,并提供了报告的下载。
另类数据的可用以及分析这些数据的新定量技术——机器学习,正在成为竞争优势的新来源
大数据和机器学习“革命”:目前,联网设备以电子方式获得了大多数的记录和观察。这原则上允许投资者实时访问广泛的市场相关数据。例如,可用于评估通货膨胀数百万项目的在线价格,可以实时估计销售量的商店访问和交易的客户数量,可以评估石油钻井平台或农业活动产量的卫星图像。历史上,类似的数据只能以低频率(例如每月CPI、每周钻机数量、美国农业部作物报告、零售销售报告和季度收入等)提供。鉴于可用的数据量,有经验的量化投资者在理论上可以接近获得实时的某公司特定的数据,而这些数据不能从传统的数据源获得。在实践中,有用的数据不容易获得,需要购买,需要组织和分析另类数据集以提取可交易信号。大型或非结构化数据集的分析通常使用机器学习来完成。在设计定量策略方面,成功应用机器学习技术需要一定的理论知识和很多实践经验。
在苦苦追寻 Alpha (对于非金融领域的读者,可以简单地将 Alpha 理解为超额回报)的过程中,基金经理越来越多地采用量化策略。
另类数据的可用以及分析这些数据的新定量技术——机器学习,正在成为竞争优势的新来源
。这种“数据的工业革命”旨在通过信息优势和发现新的不相关信号的能力来提供 Alpha。大数据信息优势来自手机、卫星、社交媒体等新技术创造的数据。大数据的信息优势与专家、行业网络甚至企业管理能力不直接相关,更多体现的是收集大量数据并实时分析数据的能力。在这方面,大数据有能力深刻改变投资环境,进一步将投资行业趋势从自由决定性转变为量化投资风格。
有三个趋势使大数据革命成为可能:
1)可用数据量的指数增加;
2)提高计算能力和数据存储容量的成本降低;
3)分析复杂数据集的机器学习方法取得了进展。
有许多经常使用的概念可以用于描述大数据,这里我们给出最简明的用来描述大数据的维度:
大数据有三个重要的特征维度:
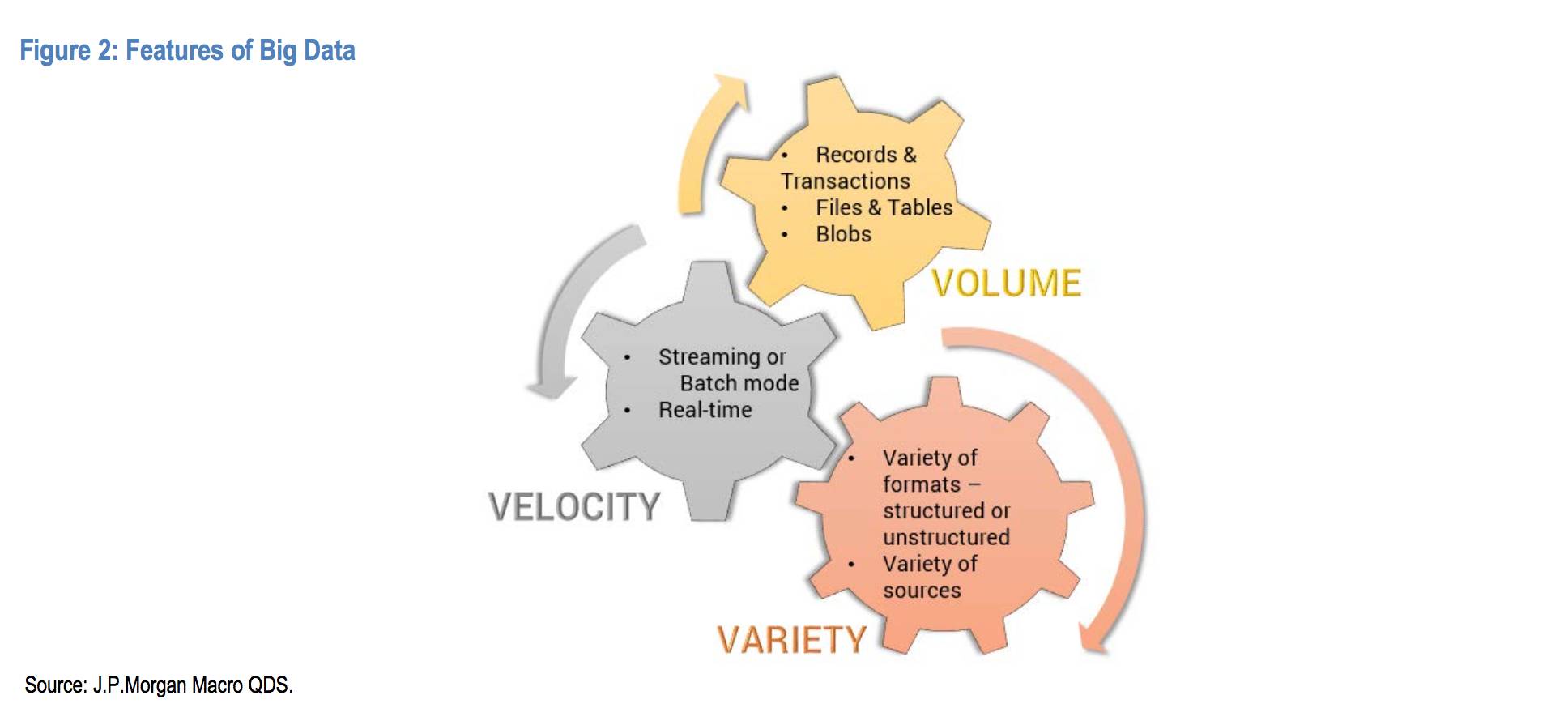
体量
:通过记录、公报、图表、文件等等收集并存储的数据的规模,大数据的“大”的下限正在持续升高;
速度
:数据的发送和接收速度经常被作为大数据的显著特征。大数据能够批量传送;大数据的获取是实时的,或是接近实时的。
多样性
:大数据经常具有多样性的形式——结构化的(如SQL 表格或 CSV 文件),半结构化的(如 JSON 或 HTML),非结构化的(如博客或视频信息)。
在投资管理中,大数据革命的核心在于能够提供具有信息优势的数据资源。另类数据带来的优势可能是在于发现传统的信息源中没有包含的新信息,或者发现的是相同的信息,但是速度更快,时间更早。例如,矿井或者土地的卫星图片能够在媒体或者官方报告前,揭示供应短缺。
我们旨在提供大数据的框架或分类。首先,我们根据数据的生成方式对数据进行分类。然后,我们考虑的是数据集的属性,也就是与投资专业直接相关的,例如将数据集映射到资产类别或投资风格,alpha内容,数据质量,技术规格等。
我们首先在高水平上对数据来源进行分类,指出它们到底是由个人(如社交媒体帖子)生成,还是通过业务流程(如电子商务或信用卡交易数据)生成,或由传感器(比如卫星图片、雷达等等)生成。

上图
展示了这一分类。这种一方法扩展了
Kitchin
(
2015
年
)
和联合国报告
(
2015
年
)
在非财务文本中早期的尝试。虽然这种分类法在某种程度上只是理论上的
,
但是
,
在分析这三个类型的数据时
,
确实存在共同特征
,
分析方法和共同的挑战。例如
,
个人生成的数据通常是非结构化的文本格式
,
需要自然语言处理。传感器生成的数据往往是非结构化的
,
并且可能需要分析技术
,
例如计数对象
,
或消除天气
/
云从卫星图像的影响。许多商业上生成的数据集
,
如信用卡交易和公司的
“
废弃
”
数据都面临共同的法律和隐私问题。
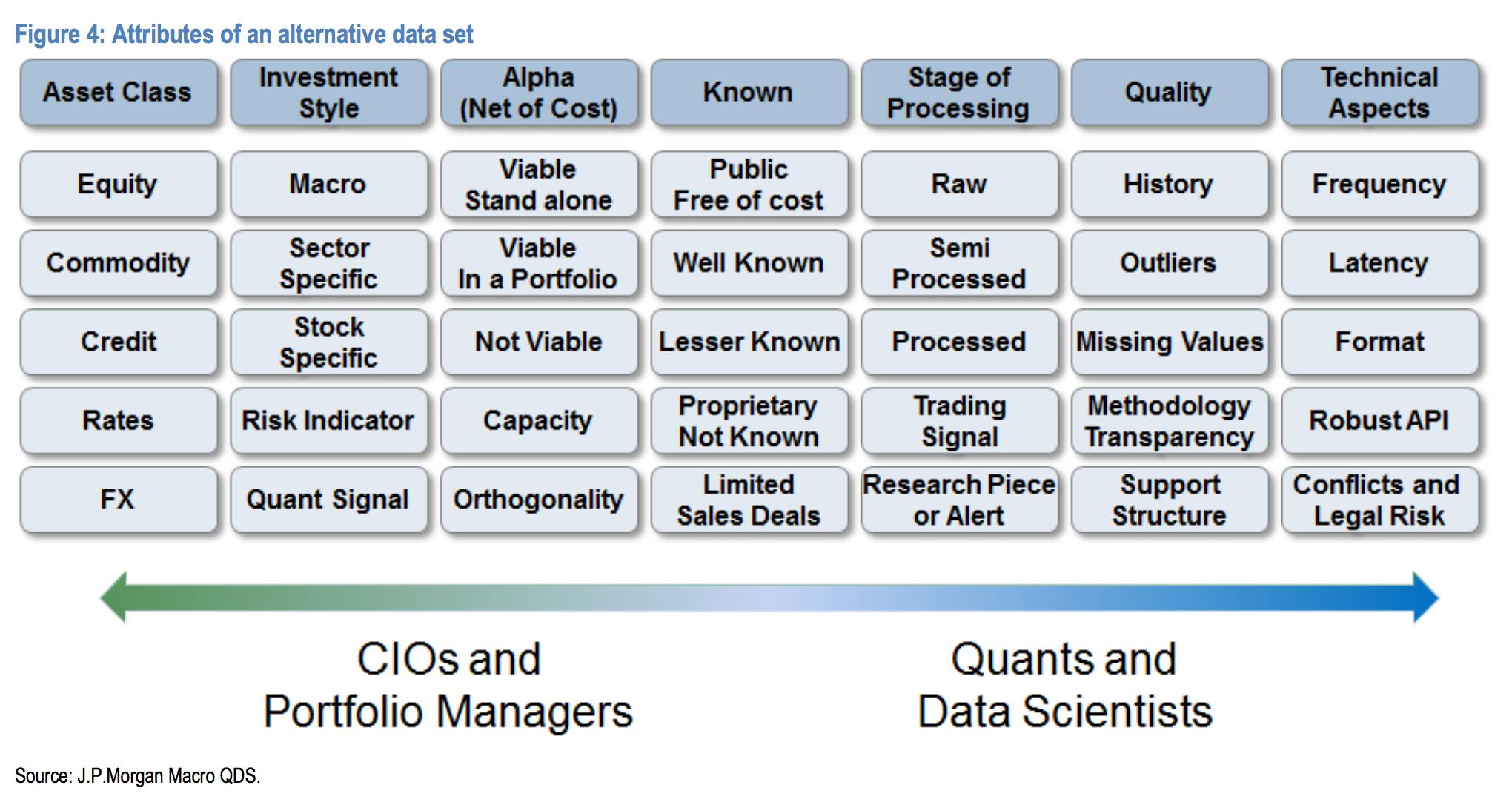
在根据数据来源对数据进行分类之后,我们还要提供另一个投资人士可能更为感兴趣的分类方法。一个零售版块的投资组合经理可能更关心的是特定的销售数据,而无所谓它们是卫星生成的还是消费者志愿填写的。高频交易者关心每天产生的数据,比如推特、最新发布等等,但不太关心有明显延迟的信息,比如信用卡数据。
在下图这个“投资分类”中,我们为各种另类数据标示了不同的属性,这些属性和投资专业人士比如 CIO、投资组合经理等高度相关。
大型和较少结构化的数据集通常不能用简单的电子表格工作和散点图进行分析。我们需要新的方法来解决新数据集的复杂性和规模。例如,使用金融分析师的标准工具不可能对非结构化数据(如图像,社交媒体和新闻稿)进行自动分析。即使在大型传统数据集上,使用简单的线性回归往往会导致过度拟合或不一致的结果。机器学习方法可用于分析大数据,以及更有效地分析传统数据集。
毫无疑问,机器学习技术在应用于图像识别,模式识别,自然语言处理以及自动驾驶汽车等复杂任务时,产生了一些惊人的成果。那么,机器学习在金融中的应用是什么,这些方法相互之间有何不同?
首先需要强调,任务的自动化不是机器学习
。我们可以指示计算机根据固定的规则执行某些操作。例如,如果资产价格下降了一定量(止损),我们可以指示电脑出售资产。即使给机器(也称为“符号人工智能”)大量复杂的规则,并不意味着就是机器学习,这只能说是任务的自动化。使用这个“符号人工智能”,机器在遇到与此前预编程的规则不匹配的情况时,只会选择自我“冻结”。
在机器学习中,给予计算机一个输入(一组变量和数据集),输出是输入变量的结果。该机器然后发现或“学习”在输入和输出之间起到链接作用的规则。
最终,这个学习任务的成功会被进行“样本外测试”,也就是,在未知的情景下,测试它所获得的这种连接变量和可能的预测结果之间的关系能力。
机器学习可以是监督的或无监督的。在监督学习中,我们试图找到一个规则,一个可以用来预测变量的“方程式”。例如,我们可能想要寻找一种能够预测未来市场表现的能力(趋势跟踪)信号。这可以通过运行先进的回归模型来评估哪一个具有较高的预测能力,并且对于regime变化最为稳定。










